
LLVM的总结
LLVM
写在前面的话:无意中看到的LLVM的作者Chris Lattner相关的介绍和故事,觉得很有意思就贴上来,如果不感兴趣,可以直接跳入下一章。
关于LLVM
如果你对LLVM的由来陌生,那么我们先来讲讲最近编程语言的新贵—swift。
2010 年的夏天,Chris Lattner 接到了一个不同寻常的任务:为 OS X 和 iOS 平台开发下一代新的编程语言。那时候乔布斯还在以带病之身掌控着庞大的苹果帝国,他是否参与了这个研发计划,我们不得而知,不过我想他至少应该知道此事,因为这个计划是高度机密的,只有极少数人知道,最初的执行者也只有一个人,那就是 Chris Lattner。
从 2010 年的 7 月起,克里斯(Chris)就开始了无休止的思考、设计、编程和调试,他用了近一年的时间实现了大部分基础语言结构,之后另一些语言专家加入进来持续改进。到了 2013 年,该项目成为了苹果开发工具组的重中之重,克里斯带领着他的团队逐步完成了一门全新语言的语法设计、编译器、运行时、框架、IDE 和文档等相关工作,并在 2014 年的 WWDC 大会上首次登台亮相便震惊了世界,这门语言的名字叫做:「Swift」。
根据克里斯个人博客(http://nondot.org/sabre/ )对 Swift 的描述,这门语言几乎是他凭借一己之力完成的。这位著名的 70 后程序员同时还是 LLVM 项目的主要发起人与作者之一、Clang 编译器的作者,可以说 Swift 语言和克里斯之前的软件作品有着千丝万缕的联系。
关于作者

克里斯可以说是天才少年和好学生的代名词,他在 2000 年本科毕业之后,继续攻读计算机硕士和博士。但克里斯并不是宅男,学习之余他手捧「龙书」游历世界,成为德智体美劳全面发展的好学生。之后就是一篇又一篇的发表论文,硕士毕业论文即提出了一套完整的运行时编译思想,奠定了 LLVM 的发展基础,读博期间 LLVM 编译框架在他的领导下得到了长足的发展,已经可以基于 GCC 前端编译器的语义分析结果进行编译优化和代码生成,所以克里斯在 2005 年毕业的时候已经是业界知名的编译器专家了。
克里斯毕业的时候正是苹果为了编译器焦头烂额的时候,因为苹果之前的软件产品都依赖于整条 GCC 编译链,而开源界的这帮大爷并不买苹果的帐,他们不愿意专门为了苹果公司的要求优化和改进 GCC 代码,所以苹果一怒之下将编译器后端直接替换为 LLVM,并且把克里斯招入麾下。克里斯进入了苹果之后如鱼得水,不仅大幅度优化和改进 LLVM 以适应 Objective-C 的语法变革和性能要求,同时发起了 CLang 项目,旨在全面替换 GCC。这个目标目前已经实现了,从 OS X10.9 和 XCode 5 开始,LLVM+GCC 已经被替换成了 LLVM+Clang。
Swift 是克里斯在 LLVM 和 Clang 之后第三个伟大的项目!
代码生成(LLVM)
why
对于一个query,优化执行性能的最理想状态,就是创造一个应用,只支持这个query的数据格式,和查询类型。
举例来说,最理想的状态下,执行一下query的速度:
select count(*) from tbl where col like %XYZ%
和
grep -c "XYZ" tbl
是相同的。
考虑另一个query:select sum(col) from tbl。如果表只有一列,类型是int64,可以用一下代码执行:
int64_t sum=0;
int64_t* values = (int64_t*)buffer;
for (int i=0; i < num_rows; ++i) {
sum += values[i];
}
用以上两种方式执行query,通常比在通用的queryengine里执行要快的多(不考虑database使用索引等优化技术)。这主要是因为目前的queryengine存在以下的开销:
虚函数调用:
在不使用代码生成技术的情况下,表达式的求值过程中通常需要调用虚函数,例如eval。这主要取决于系统的实现,通常来说,总会有一群operator类,每一个operator类都会实现eval函数。在这种情况下,表达式计算本身的开销很小,而虚函数调用带来的开销通常就会比较大。
大量的switch case代码,需要对类型等进行判断:
尽管分支预测技术可以缓解这个问题,但是分支指令依然会降低执行pipeline的效率,以及影响指令级并行。
无法通过使用常量提高性能:
在Impala中,每一个tuple的的长度在编译时就已经计算好。例如col3在tuple中的offset时16。如果把这些常量写入代码中,则可以减少额外的内存访问的开销。
代码生成的目标就是,对每一个query,都使用和定制程序几乎相同的指令数,并得到相同的结果。避免因为支持更多的功能而导致的额外开销。
what
LLVM(Low Level Virtual Machine)是一组库,包含了编译器的building blocks。主要的模块包括:
ü AST -> IR generation
ü IR优化
ü IR -> machine code generation
LLVM的IR和Java的byte code很类似。IR一种二进制语言,LLVM把IR当作其内部模块的输入和输出LLVM也提供更高级的code object(instruction object,function object),使得可以更方便的对IR进行编程。包括对函数进行inline,移除指令,用常量替代一个计算,等等。Impala用到了LLVM中的IR优化,以及IR生成机器码。
除了LLVM,还有其他的生成代码的方式,但LLVM的效果更好:
l 直接生成可以执行的机器码:
尽管这个过程速度很快,但是生成机器码很容易出错,也很复杂,尤其是当函数数量增加时。同时,这种方法也无法享受编译器优化带来的性能提升。
l 生成c++代码,编译,并动态加载:
这种方法生成的代码可以经过编译器优化,并且生成高级语言相对简单。但通常编译c++代码需要几秒的时间,是比较慢的。
how
在进行完语意分析后,impala为每一个独立的操作生成其kernal代码。在代码生成时,由于已经知道了数据的类型,数据的layout。所以生成的代码中,会对循环等进行很多的优化。
LLVM提供两种生成IR的机制。1)使用IrBuilder API;2)使用clang编译器。这两种方法Impala都用到了。
- 使用IrBuilder生成IR
- 加载已经编译好的IR,仅加载query需要的函数。
- 把1和2的结果combine到一起。
- 通过LLVM的优化器,对IR进行优化。
- JIT compile,把优化后的IR编译成机器码。LLVM会把它以函数指针的形势返回。
示例:
select
l_returnflag,
l_linestatus,
sum(l_quantity),
sum(l_extendedprice),
sum(l_extendedprice * (1 - l_discount)),
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)),
avg(l_quantity),
avg(l_extendedprice),
avg(l_discount),
count(1)
from
tpch.lineitem
where
l_shipdate<='1998-09-02'
group by
l_returnflag,
l_linestatus
Impala会将这个query编译成一个算子树。对这个query来说,会有两个算子:scan算子,用于读取输入数据;聚合算子,计算sum和avg。
下图时执行结果对比:
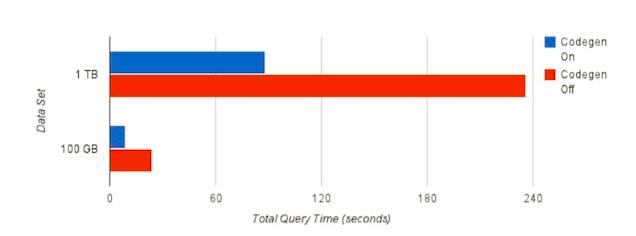
对于两种不同的dataset,性能头提高了3倍。而代码生成消耗的时间大概为150s。代码生成消耗的时间和采用的优化选项有很大关系。可以在impala shell中,使用set命令查看优化选项。
下表是更详细的对比:
可以看到,采用代码生成可以减少一半的指令和一半的branch miss。
总结
我们在代码生生成上投入的精力已经得到了回报。随着我们继续的改进,我们期望得到更大的性能提升。列存储,更高效的编码方式,以及更大的缓存,这些技术会提高IO的性能。这时候,CPU的效率就将变得更加重要。
代码生成对于简单的query,带来的性能提升会更明显。对于query中带有复杂操作的,例如正则表达式,则性能提升会不那么显著。因为相对来说,正则表达本身的计算会占用更多时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号