
# encoding:utf-8
import os
import requests
from bs4 import BeautifulSoup
#爬虫头数据
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ',
'_s_tentry': 'www.baidu.com',
'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com',
'Apache': '7782025452543.054.1635925669528',
'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('cate', 'realtimehot'),
)
#获取网页
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)
response.encoding='utf-8'
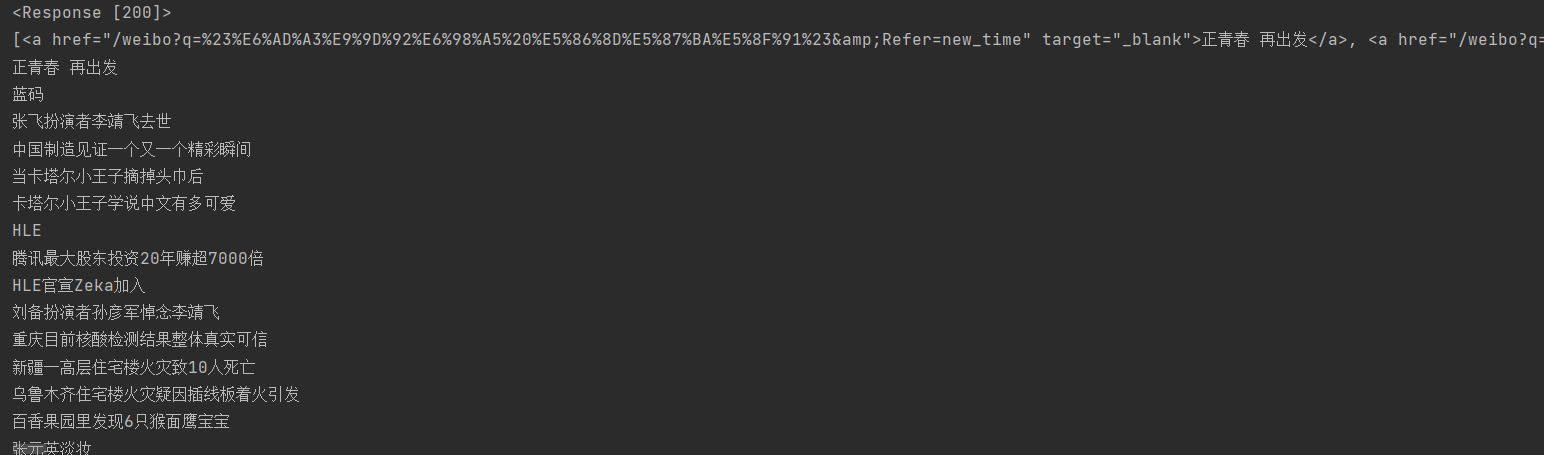
print(response)
#解析网页
soup = BeautifulSoup(response.text, 'html.parser')
#爬取内容
content="#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
a=soup.select(content)
print(a)
for i in range(0,len(a)):
#print(i)
a[i] = a[i].text
print(a[i])




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?