
# encoding:utf-8
import requests
import csv
headers = {
'cookie':'device_id=02a63e162n=0035d9dae1eded6e3=1666944669347886',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
#循环翻页功能
for ye in range(1,5):
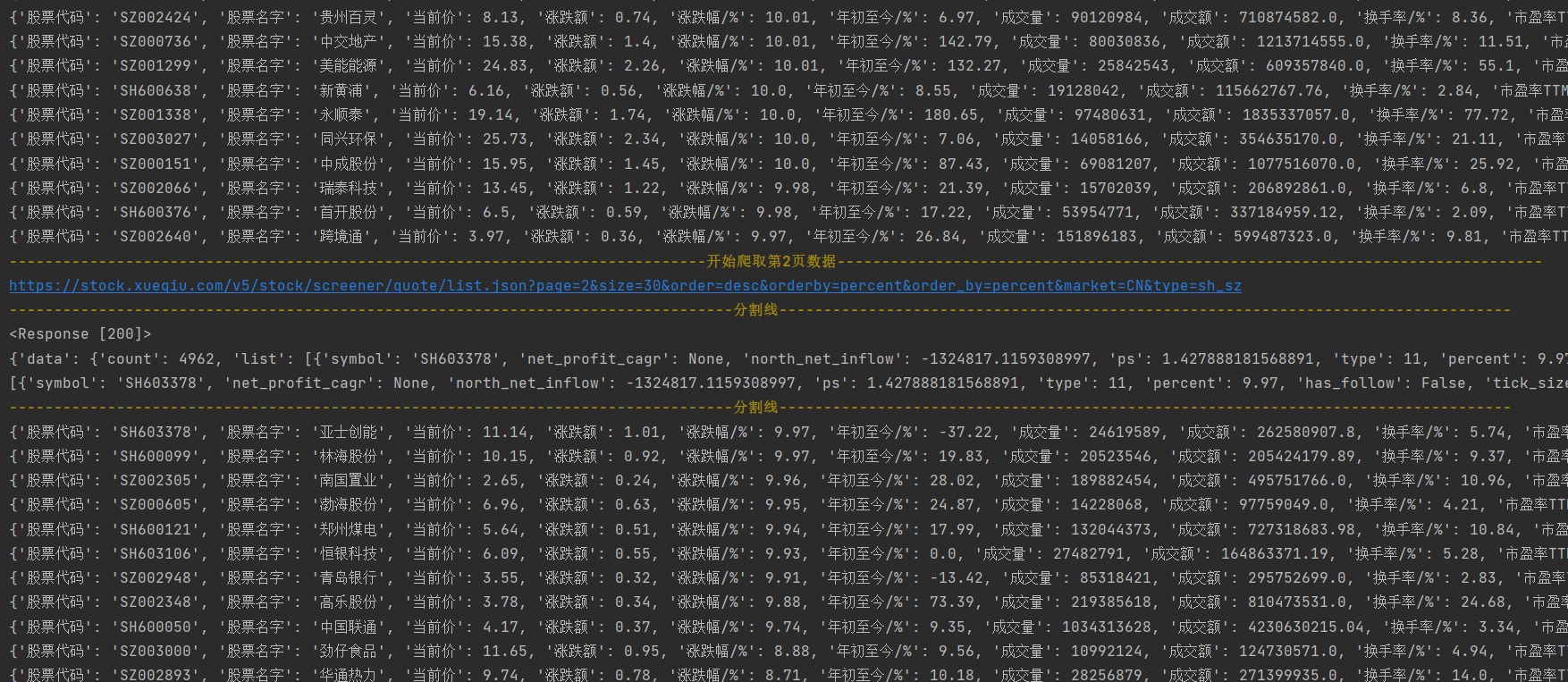
url = 'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=%d&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz' %ye
print('\033[1;33m%s\033[0m' % (("开始爬取第%s页数据" %ye).center(166, '-')))
print(url)
#################################################################################################################################
print('\033[1;33m%s\033[0m' %("分割线".center(166,'-')))
#################################################################################################################################
response = requests.get(url=url, headers=headers)
print(response)
html_data = response.json()
print(html_data)
data_list = html_data['data']['list']
print(data_list)
#################################################################################################################################
print('\033[1;33m%s\033[0m' %("分割线".center(166,'-')))
#################################################################################################################################
for i in data_list:
dit = {}
dit['股票代码'] = i['symbol']
dit['股票名字'] = i['name']
dit['当前价'] = i['current']
dit['涨跌额'] = i['chg']
dit['涨跌幅/%'] = i['percent']
dit['年初至今/%'] = i['current_year_percent']
dit['成交量'] = i['volume']
dit['成交额'] = i['amount']
dit['换手率/%'] = i['turnover_rate']
dit['市盈率TTM'] = i['pe_ttm']
dit['股息率/%'] = i['dividend_yield']
dit['市值'] = i['market_capital']
print(dit)
#保存数据
# f = open('股票数据.csv', mode='a', encoding='utf-8-sig', newline='')
# csv_writer = csv.DictWriter(f, fieldnames=['股票代码', '股票名字', '当前价', '涨跌额', '涨跌幅/%', '年初至今/%',
# '成交量', '成交额', '换手率/%', '市盈率TTM', '股息率/%', '市值'])
# csv_writer.writeheader()
# csv_writer.writerow(dit)
# f.close()
# encoding:utf-8
# encoding:utf-8
import requests
import csv
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
cookies = {
'Cookie': 'device_id=02a6jaWQiOiJkOW9347886'
}
for ye in range(1,3):
date = round(time.time() * 1000)
params = {
'page': '{}'.format(ye),
'size': '30',
'order': 'desc',
'order_by': 'amount',
'exchange': 'CN',
'market': 'CN',
'type': 'sha',
'_': '{}'.format(date),
}
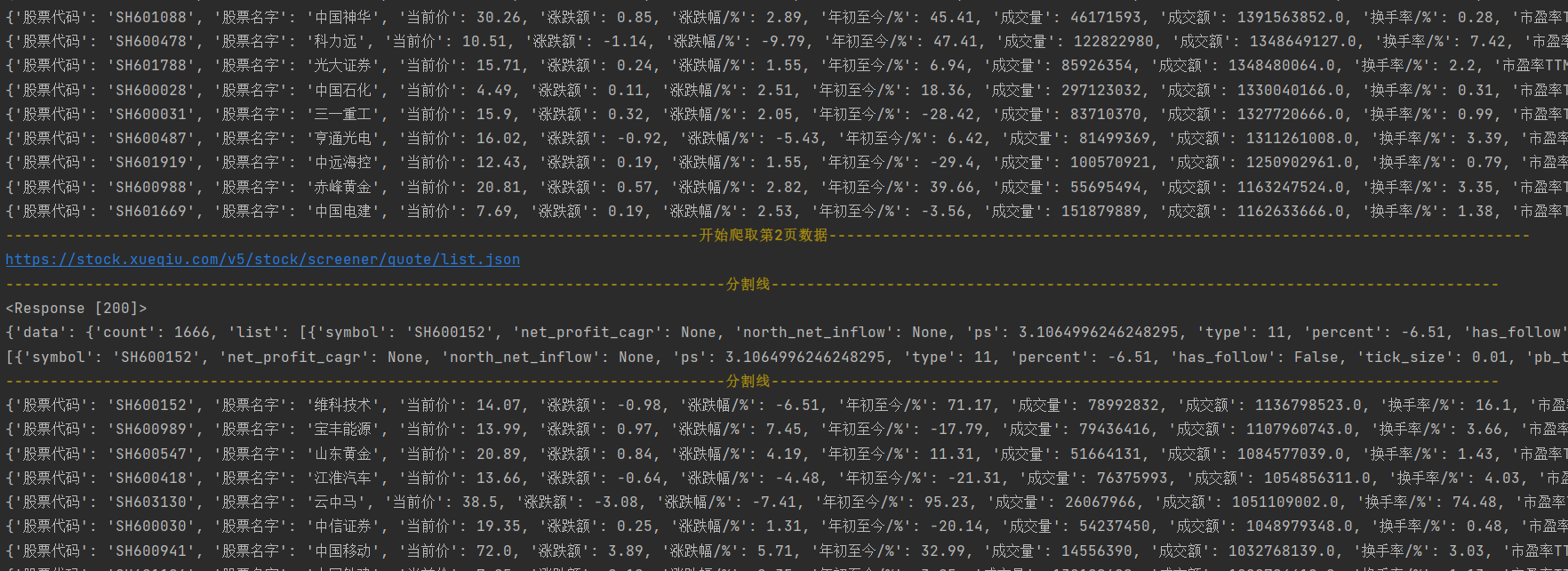
url = 'https://stock.xueqiu.com/v5/stock/screener/quote/list.json'
print('\033[1;33m%s\033[0m' % (("开始爬取第%s页数据" %ye).center(166, '-')))
print(url)
#################################################################################################################################
print('\033[1;33m%s\033[0m' %("分割线".center(166,'-')))
#################################################################################################################################
response = requests.get(url=url, params=params, headers=headers, cookies=cookies)
print(response)
html_data = response.json()
print(html_data)
data_list = html_data['data']['list']
print(data_list)
#################################################################################################################################
print('\033[1;33m%s\033[0m' %("分割线".center(166,'-')))
#################################################################################################################################
for i in data_list:
dit = {}
dit['股票代码'] = i['symbol']
dit['股票名字'] = i['name']
dit['当前价'] = i['current']
dit['涨跌额'] = i['chg']
dit['涨跌幅/%'] = i['percent']
dit['年初至今/%'] = i['current_year_percent']
dit['成交量'] = i['volume']
dit['成交额'] = i['amount']
dit['换手率/%'] = i['turnover_rate']
dit['市盈率TTM'] = i['pe_ttm']
dit['股息率/%'] = i['dividend_yield']
dit['市值'] = i['market_capital']
print(dit)
#保存数据
# f = open('股票数据.csv', mode='a', encoding='utf-8-sig', newline='')
# csv_writer = csv.DictWriter(f, fieldnames=['股票代码', '股票名字', '当前价', '涨跌额', '涨跌幅/%', '年初至今/%',
# '成交量', '成交额', '换手率/%', '市盈率TTM', '股息率/%', '市值'])
# csv_writer.writeheader()
# csv_writer.writerow(dit)
# f.close()
# encoding:utf-8
import requests
import json
for ye in range(1, 3):
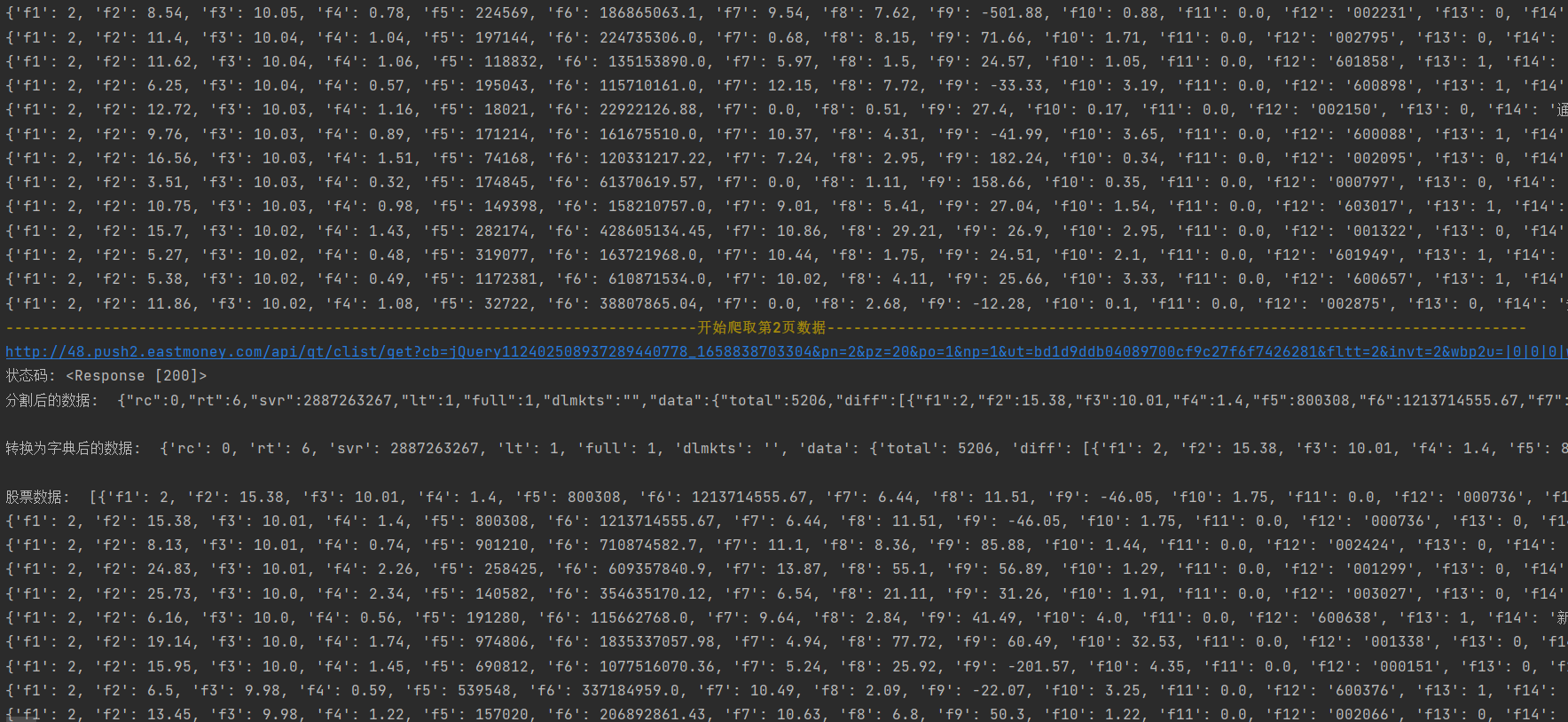
print('\033[1;33m%s\033[0m' % (("开始爬取第%s页数据" % ye).center(166, '-')))
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305" % str(
ye)
print(url)
res = requests.get(url)
print("状态码:",res)
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
print("分割后的数据: ",result,'\n')
result_json = json.loads(result)
print("转换为字典后的数据: ",result_json,'\n')
stock_data = result_json['data']['diff']
print("股票数据: ",stock_data)
for data in stock_data:
print(data)
#print(data["f14"])




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?