
HashMap是线程不安全的,所以jdk提供了ConcurrentHashMap 这个线程安全的map集合实现,这一篇文章来分析下jdk7中ConcurrentHashMap 的实现原理
一、分段锁 Segment
jdk7中ConcurrentHashMap 的实现使用了分段锁的思想。
先来思考下Hashtable是一个线程安全的map,但为什么它的效率不高呢?
因为它里边的所有方法都是被synchronized修饰的,这样当一个线程t1进行put操作时,另一个线程t2就不能进行put或者get操作即使他们操作的是不同的数组下标,所以说它的效率低,同时只能允许一个线程进行操作。
分段锁的思想就是为了解决这种效率问题,我们先给出一张图来说明下。
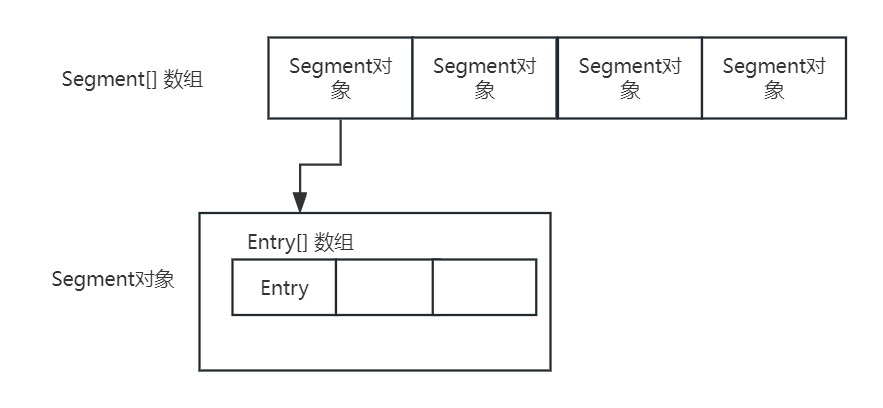
相比于HashMap,ConcurrentHashMap 的实现中多嵌套了一层Segment数组,而这个Segment对象就是分段锁,可以理解成它就是一个小型的HashMap,
当两个线程t1和t2同时进行put操作时,会先根据key的hash值计算出要存放
在Segment数组的那个下标处,假设t1和t2计算出的下标不一样,那么他们就会各自去找到自己需要的Segment对象去进行put(调用segment对象的put方法),加锁是在segment对象的内部实现的,这样就实现了两个线程的put操作互不干扰,提高了效率,当然如果两个线程要操作的是Segment数组的同一个下标,那还是需要竞争锁的,这就是jdk7中分段锁的实现原理。
二、构造方法
先从构造方法看起,了解下构造方法的几个参数和HashMap的有什么不同
//无参数的构造方法,调用有参数的构造方法,传递了几个默认值
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
//我们来详细看下这几个参数的含义
/**
* initialCapacity map的初始容量,注意这个容量是整个map的容量
也就是 容量= 并发级别* 每个Segment对象中entry数组的长度,创建Segment对象时就是根据这个关系计算内部
Entry数组的容量
* loadFactor 负载因子,和扩容相关
* concurrencyLevel map的并发级别,即map最多支持几个线程同时操作,也就是Segment数组的长度
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
//底下这个循环是在计算真正的并发级别,根据传入的数字,得到一个比它大的最小的2的次方数,
//计算得到的ssize会作为segment数组的容量,注意这个容量确定后后边就不会再变了
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//这里是在计算每个Segment对象中Entry数组的长度,
//初始容量/计算出的并发度,注意这里是用int接收,如果除不尽就会只保留整数部分,
int c = initialCapacity / ssize;
//这里是检验算出的c*并发度是否满足传入的初始容量,如果不满足就给它加1
if (c * ssize < initialCapacity)
++c;
//这个常量表示Entry数组最小的长度是2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//如果上边算出的容量比2大,就cap*2继续和c比较,最后得当的cap是一个比c大的2的次方数,
//为什么一定要是2的次方数这和Segment对象中计算待put的key的下标的方式有关
while (cap < c)
cap <<= 1;
// create segments and segments[0]
//创建Segment数组0下标处的Segment对象
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
/*这个数组就是Segment内部Entry数组*/
(HashEntry<K,V>[])new HashEntry[cap]);
//创建Segment数组
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//用UNSAFE对象把s0放到ss的0号下标处,这里使用UNSAFE是为了直接操作主内存
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
注意到这个构造方法中比HashMap的构造方法多了一个concurrencyLevel,并发级别,它表示最多可以同时允许多少个线程同时操作,对应的是Segment数组的容量。
三、put方法
put方法的思想是先计算出key应该放在外层Segment数组的那个下标处,然后再调用Segment对象的put方法。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
//计算key对应的Segment数组下标, hash值 & 数组长度-1,和hashmap类似
int j = (hash >>> segmentShift) & segmentMask;
// 这个if条件里边用UNSAFE对象从Segment数组中获取下标j处的对象,
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//如果获取到的对象是空就需要新创建一个
//这个方法内部就是创建一个Segemnt对象放在Segment数组的j下标处,
//内部用多重检查和cas操作保证了只有一个线程会创建对象并放到数组下标处成功
s = ensureSegment(j);
//调用Segemnt对象的put方法
return s.put(key, hash, value, false);
}
//这是Segemnt对象内部的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试获取锁,如果失败了就执行scanAndLockForPut,这里边是在继续尝试获取锁,并做
// 一些准备工作,尝试次数到达一定限度就会改成用阻塞的方式获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
//能走到这里表示当前线程已经成功获取到了锁
try {
HashEntry<K,V>[] tab = table;
//计算key对应的Entry数组下标
int index = (tab.length - 1) & hash;
//取出下标处的元素
HashEntry<K,V> first = entryAt(tab, index);
//循环下标处的链表
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
//这里是在判断链表上的某个元素的key是否和传入的key相等,
//如果相等就替换value,不相等就继续遍历下个元素
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//这个else表示遍历到了链表的最后一个节点
//这个node就是针对要put的key/value创建的节点,它有可能在上边尝试获取锁的
//的时候提前创建了,如果没有这里就重新创建然后加入原来的链表,
//jdk7采用的是头插法
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//校验容量看是否需要扩容
rehash(node);
else
//这里边利用unsfafe修改entry数组下标index处的元素为新创建的node
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
可以看到put时是先确定往哪个Segment对象放,然后在Segment对象内部加锁进行put,这就是分段锁的体现。
四、扩容方法
上边在put方法里边提到了put一个元素的过程中会校验是否需要扩容,如果需要就会调用扩容方法,
要注意的是扩容值是把当前Segment对象内部的Entry数组进行扩容,并不会影响其他的Segment对象,同时注意扩容只扩Segment对象内部,Segment数组是不扩容的,也就是并发级别是不会变的。
扩容的过程就是先创建一个容量是原来数组两倍的新数组,然后遍历就数组的每一个下标,再遍历下标处的链表,重新计算每个元素在数组的下标并搬到新数组中。
扩容是支持多个线程同时扩容的,注意是每个线程对不同的Segment对象进行扩容。


