

mybatis中存在一级缓存和二级缓存,其中一级缓存是默认开启并且不能关闭的,二级缓存需要手动开启。
一、一级缓存
mybatis中的一级缓存是SqlSession级别的缓存,只有在同一个sqlSession范围内的查询才会走一级缓存。
1.1 一级缓存的效果
先来看下一级缓存的效果
准备下面的测试代码
public class CacheTest {
public static void main(String[] args) {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/stu_admin");
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("dev",transactionFactory,dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(IUserDao.class);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession = sqlSessionFactory.openSession();
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
User user1 = userDao.findById("1");
User user2 = userDao.findById("1");
System.out.println(user1==user2);
}
}
控制台会得到这样的输出
17:00:06.334 [main] DEBUG org.apache.ibatis.logging.LogFactory - Logging initialized using 'class org.apache.ibatis.logging.slf4j.Slf4jImpl' adapter.
17:00:06.528 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Opening JDBC Connection
17:00:06.621 [main] INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-1} inited
17:00:06.856 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@167fdd33]
17:00:06.856 [main] DEBUG com.lyy.dao.IUserDao.findById - ==> Preparing: SELECT * FROM t_user WHERE user_id=?
17:00:06.887 [main] DEBUG com.lyy.dao.IUserDao.findById - ==> Parameters: 1(String)
17:00:06.965 [main] DEBUG com.lyy.dao.IUserDao.findById - <== Total: 1
true
可以看到执行了两次查询但mybatis只打印了一次sql,并且user1和user2是相等的,所以可以说明mybatis使用了缓存。但如果你重新创建一个sqlsession去执行查询就不会走缓存。
1.2 从一级缓存的源码分析一级缓存的命中原则
先给出一个mybatis中Executor的类图

mybatis的一级缓存是在BaseExecutor中实现的,mybatis通过sqlsession执行sql,sqlsession中会持有Executor。
public abstract class BaseExecutor implements Executor {
//省略其他
//这个属性就是一级缓存,它内部有一个map
protected PerpetualCache localCache;
}
我们通过研究DefaultSqlSession#selectList 方法来看下一级缓存的值是怎么被放进去的。
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
//调用执行器方法查询,所以关键在执行器上
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
executor.query会调到BaseExecutor中
BaseExecutor
public abstract class BaseExecutor implements Executor {
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
//生成缓存key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//查询
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
//生成缓存key的方法
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());//statemnetId
cacheKey.update(Integer.valueOf(rowBounds.getOffset()));
cacheKey.update(Integer.valueOf(rowBounds.getLimit()));//mybatis的分页参数
cacheKey.update(boundSql.getSql());//要发送给数据库的sql
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);//sql参数
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());//mybaits的环境对象
}
return cacheKey;
}
}
从这个createCacheKey方法看出一级缓存的命名条件:
同一个statementID,使用的参数要一样,mybatis分页参数一样(这个一般不自己指定),发给数据库的sql要一样,
mybatis环境对象要一样。
1.3 一级缓存什么时候被放进去
继续看BaseExecutor中的query方法来看下一级缓存是什么时候被放进去的
public abstract class BaseExecutor implements Executor {
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//这里是从一级缓存中查询
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//一级缓存中查不到时再从数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
//查询数据库的方法
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//查询数据库
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//把查询到的结果放入一级缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
}
所以一级缓存是在BaseExecutor的query方法中被放进去的,也就是说需要调用sqlsession.select开头的方法才会放入一级缓存。
1.4 一级缓存什么时候会被清空
当我们通过sqlsession执行update,delete,insert语句时最终都会调用org.apache.ibatis.session.defaults.DefaultSqlSession#update(java.lang.String, java.lang.Object)
方法,
public class DefaultSqlSession implements SqlSession {
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
//调用执行器的update方法
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
一级缓存是在BaseExecutor中实现的,所以直接看BaseExecutor#update方法
public abstract class BaseExecutor implements Executor {
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//这里就是在清空一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
}
所以一级缓存在通过sqlsession进行修改数据库数据的操作时会被清空
1.5 注意点
一级缓存是通过BaseExecutor执行的,SqlSession中持有Executor,所以一级缓存只有在同一个sqlsession的范围内会生效。
在spring整合mybatis的工程中如果不开启事务每次都会创建新的sqlsession,也就是一级缓存不生效。
如果开启了事务在同一个事务的范围内使用的是同一个sqlsession对象,这时一级缓存就生效了。
二、二级缓存
2.1开启二级缓存的方法
二级缓存默认不开启
二级缓存依赖的是org.apache.ibatis.mapping.MappedStatement#cache 属性,而这个属性针对同一个mapper文件中的所有statement用的是同一个,所以二级缓存的作用范围是在同一个mapper范围内,即同一个namespace范围内。而MappedStatement保存在org.apache.ibatis.session.Configuration#mappedStatements属性中,创建sqlsessionFactory时需要传递Configuration对象,
所以只要是根据同一个Configuration创建的sqlsessionFactory去创建sqlsession进行查询时都可以访问到同一个二级缓存,也就是二级缓存不仅可以跨sqlsession访问,也可以跨sqlsessionFactory访问。
接下来举例来验证下,那个mapper文件需要开启二级缓存,就给其中加上cache标签
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lyy.dao.IUserDao">
<cache></cache>
<select id="findById" resultType="com.lyy.domain.User">
SELECT * FROM t_user WHERE user_id=#{userId}
</select>
</mapper>
代码验证:
public class CacheTest {
public static void main(String[] args) {
//创建Configuration对象
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/stu_admin");
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("dev",transactionFactory,dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(IUserDao.class);
//创建第一个sqlsessionfactory
SqlSessionFactory sqlSessionFactory1 = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession = sqlSessionFactory1.openSession();
User user3 = sqlSession.selectOne("com.lyy.dao.IUserDao.findById","1");
//只有执行了close或commit方法才会把查询结果存入二级缓存
sqlSession.close();
//使用sqlSessionFactory1创建新sqlsession来查询,验证二级缓存可以跨sqlsession访问
sqlSessionFactory1.openSession().selectOne("com.lyy.dao.IUserDao.findById","1");
//获取第2个sqlSessionFactory并创建sqlsession进行查询,验证二级缓存可以跨sqlsessionfactory访问
SqlSessionFactory sqlSessionFactory2 = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession2 = sqlSessionFactory2.openSession();
User user4 = sqlSession2.selectOne("com.lyy.dao.IUserDao.findById","1");
}
}
2.2 二级缓存的源码分析
首先,一级缓存是在BaseExecutor中实现的,而二级缓存是在CachingExecutor中实现的,利用装饰者模式对
BaseExecutor进行了装饰,我们先看下这个装饰是在哪里完成的,Executor的创建是通过sqlsessionFactory完成的,所以看下DefaultSqlSessionFactory#openSession方法
public class DefaultSqlSessionFactory implements SqlSessionFactory {
@Override
public SqlSession openSession() {
// configuration.getDefaultExecutorType()默认值是simple类型的
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//这个newExecutor方法是在创建Executor,
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
//这里是根据传入的类型创建对应的Executor
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
//这里根据Configuration.cacheEnabled属性来决定是否创建CachingExecutor来装饰executor
//在Configuration中cacheEnabled默认就是true
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
}
然后我们接着看下CachingExecutor中对二级缓存的实现
public class CachingExecutor implements Executor {
//被代理的执行器
private Executor delegate;
//缓存管理器
private TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
//生成缓存key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
//生成key的方法直接调用的是被代理对象的,也就是BaseExecutor,所以二级缓存的命中条件和
// 一级缓存是一样的
return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
//使用二级缓存的查询方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//从MappedStatement对象中获取cache,这个对象是在解析mapper文件的过程中创建的,只有我们的mapper文件
// 中有cache标签才会去创建这个对象
// 二级缓存中的数据最终就是存储在这个cache对象中的
Cache cache = ms.getCache();
if (cache != null) {
//看是否配置了查询之前刷新二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
//如果是有输出参数的查询这个方法内部会抛出异常
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
//从二级缓存中查询
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//查不到从数据库查询
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//把查询结果添加到缓存管理器中,但是并没有保存到二级缓存里边,只有调用了commit/close才会存
//要了解这个需要继续看tcm的实现,
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//不使用二级缓存
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public void close(boolean forceRollback) {
try {
//issues #499, #524 and #573
if (forceRollback) {
tcm.rollback();
} else {
//通过缓存管理器提交数据到二级缓存
tcm.commit();
}
} finally {
delegate.close(forceRollback);
}
}
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
//通过缓存管理器提交数据到二级缓存
tcm.commit();
}
}
上边的查询方法中出现了一个 TransactionalCacheManager,它是用来管理二级缓存的,通过它把数据存储到从
MappedStatement对象中获取到的cache对象中
public class TransactionalCacheManager {
//每一个开启二级缓存的mapper文件都对应一个cache,这个map中存放了当前sqlsession查询过的
// statement对应的cache对象,同一个mapper文件中statement用的是同一个cache对象,
//key是cache对象本身,value是用装饰者模式对cache的又一次装饰
private Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
public Object getObject(Cache cache, CacheKey key) {
//先从transactionalCaches中获取到TransactionalCache再去查询
return getTransactionalCache(cache).getObject(key);
}
private TransactionalCache getTransactionalCache(Cache cache) {
//先根据cache看能不能找到装饰后的transactionalCache
TransactionalCache txCache = transactionalCaches.get(cache);
if (txCache == null) {
//找不到表示这个mapper文件是第一次被查询,给它创建一个cache的包装对象然后放到transactionalCaches中
txCache = new TransactionalCache(cache);
transactionalCaches.put(cache, txCache);
}
return txCache;
}
public void putObject(Cache cache, CacheKey key, Object value) {
//先获取transactionalCache,再调用先获取transactionalCache.put方法
getTransactionalCache(cache).putObject(key, value);
}
}
通过上边的代码我们了解到 TransactionalCacheManager中对MappedStatement.cache对象用TransactionalCache 又进行了一次包装,
public class TransactionalCache implements Cache {
// 被代理的对象,也就是mapperstatment对象中的cache属性
private Cache delegate;
private boolean clearOnCommit;
//暂存将要被提交到delegate中的数据,
private Map<Object, Object> entriesToAddOnCommit;
private Set<Object> entriesMissedInCache;
@Override
public void putObject(Object key, Object object) {
//可以看到当我们在CachingExecutor中调用putObj方法后数据并没有进入二级缓存
entriesToAddOnCommit.put(key, object);
}
//只有当这个方法被调用后数据才会进入二级缓存,这也就是为什么二级缓存要在调用了sqlsession
// 的commit或者close方法后才会被写入
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
//循环待放入的集合,把数据放入delegate中,也就是mapperstatment对象中持有的cache属性中
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
}
二级缓存中多次使用了装饰者模式,在解析mapper文件生成MapperStatment对象时会给它的cache属性赋值,这个值这时候也已经是被装饰了很多次了,Cache本身是一个接口,
public interface Cache {
//...
}
每一次装饰就是创建一个新的实现类对象然后传入旧的实现类对象,这样cache就会增加一些新功能。
xml文件中cache标签的解析是从XMLMapperBuilder#parse方法这里开始的
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
//解析mapper标签的过程中会解析cache标签
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingChacheRefs();
parsePendingStatements();
}
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
//解析cache标签
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
private void cacheElement(XNode context) throws Exception {
if (context != null) {
//拿到cache标签的type属性,这个type属性是用来自定义二级缓存的实现的,
String type = context.getStringAttribute("type", "PERPETUAL");
//type属性值对应的class文件
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
//利用typeClass去创建二级缓存的存储对象cache
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
org.apache.ibatis.builder.MapperBuilderAssistant#useNewCache这个方法就是用来创建cache的
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
//根据type属性的值去创建二级缓存存储对象,创建好后进行一系列的包装
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();//这里的每一个方法调用都是一次装饰
configuration.addCache(cache);//把cache对象添加到configuration.caches属性中
//这个currentCache在创建mapperstatment时会被赋值给mapperstatment对象中的cache属性,
//所以说同一个mapper文件中每个statement用的是同一个二级缓存对象
currentCache = cache;
return cache;
}
//解析statement标签时会调用的方法
public MappedStatement addMappedStatement(
String id,
SqlSource sqlSource,
StatementType statementType,
SqlCommandType sqlCommandType,
Integer fetchSize,
Integer timeout,
String parameterMap,
Class<?> parameterType,
String resultMap,
Class<?> resultType,
ResultSetType resultSetType,
boolean flushCache,
boolean useCache,
boolean resultOrdered,
KeyGenerator keyGenerator,
String keyProperty,
String keyColumn,
String databaseId,
LanguageDriver lang,
String resultSets) {
if (unresolvedCacheRef) {
throw new IncompleteElementException("Cache-ref not yet resolved");
}
id = applyCurrentNamespace(id, false);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);//这里就是在设置二级缓存对象
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
statementBuilder.parameterMap(statementParameterMap);
}
MappedStatement statement = statementBuilder.build();
configuration.addMappedStatement(statement);
return statement;
}
2.2 二级缓存命中原则
通过上边的源码分析可以知道二级缓存的命中原则和一级缓存是一样的
2.3二级缓存什么时候被放进去
查询后并调用了sqlsession的commit或者close方法
2.4 二级缓存什么时候会被清空
CachingExecutor的update方法被执行后
2.5 使用二级缓存引发的问题
二级缓存在在同一个Mapper范围内生效,放入,清空这些操作都只会针对当前sqlsession查询过的mapper
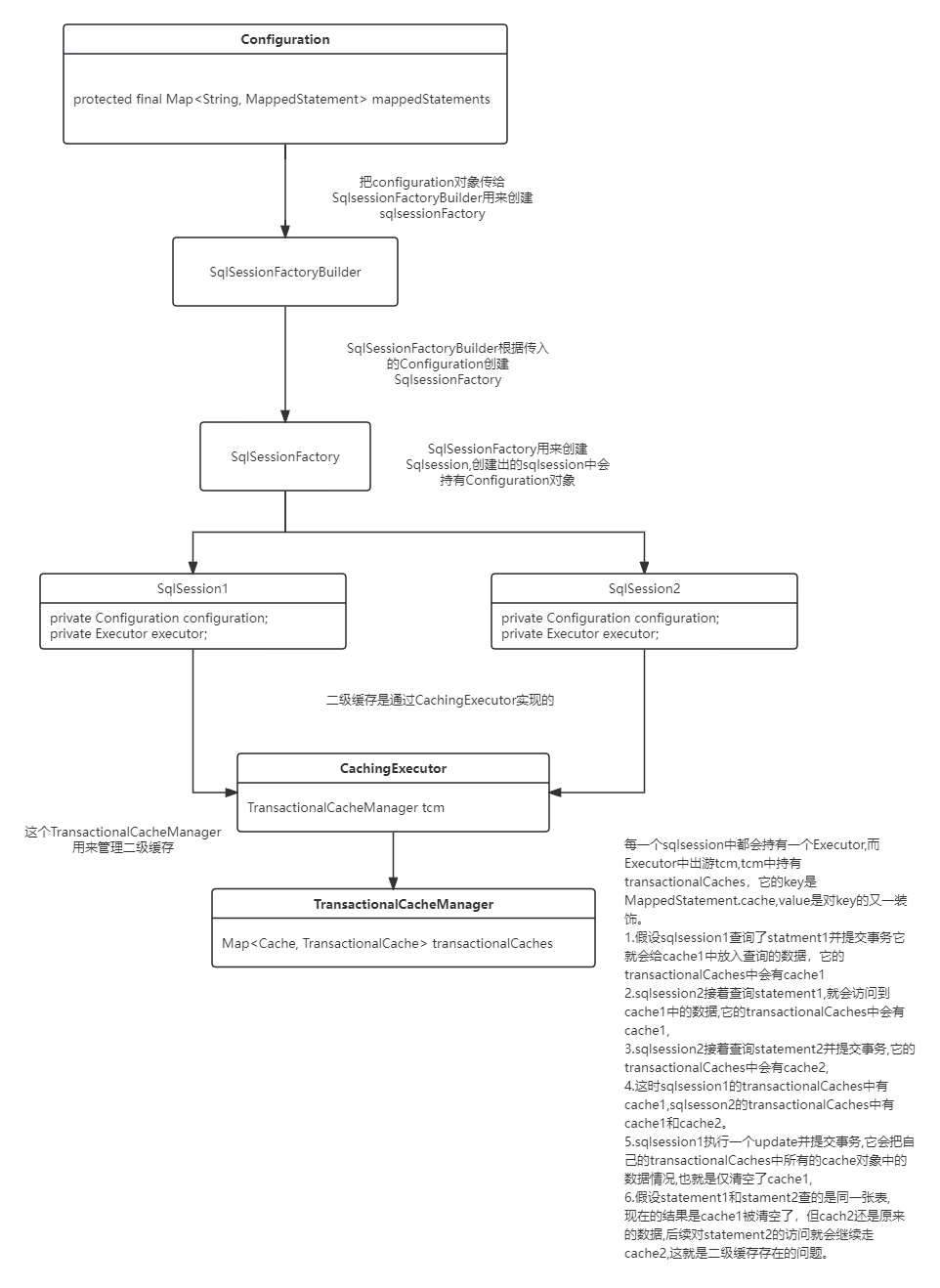
所以如果两个Mappe文件查询同一张表,statement1是mapper1中的,statement2是mapper2中,sqlsession1先查询statement1并提交,则mapper1.cache会缓存数据,sqlsession2再查询statement2并提交,则mapper2.cache会缓存数据,
然后sqlsession1修改表并提交,它只会清空自己查询过的mapper1.cache,而mapper2.cache还是以前的,
所以 所有sqlsession针对statement2的访问都会走缓存,只到某个sqlsession先查询statement2再执行update才会去清空cache2
下面给出一个详细的二级缓存原理和存在问题的示意图
三、自定义二级缓存的实现类
上边源码分析的时候提到了cache标签有一个type属性,自定义二级缓存的实现类就是通过这个属性。
先看下怎么写一个自定义二级缓存实现类,
mabatis提供了一个Cache接口,只需要提供一个此接口的实现类,并把全路径用type属性指定即可替换mybatis默认的二级缓存实现类,例如可以把二级缓存放在redis中。
public interface Cache {
/**
* @return The identifier of this cache,注意必须实现这个方法,mybatis会使用这个方法
*/
String getId();
/**
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* As of 3.3.0 this method is only called during a rollback
* for any previous value that was missing in the cache.
* This lets any blocking cache to release the lock that
* may have previously put on the key.
* A blocking cache puts a lock when a value is null
* and releases it when the value is back again.
* This way other threads will wait for the value to be
* available instead of hitting the database.
*
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* Clears this cache instance
*/
void clear();
/**
* Optional. This method is not called by the core.
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* Optional. As of 3.2.6 this method is no longer called by the core.
*
* Any locking needed by the cache must be provided internally by the cache provider.
*
* @return A ReadWriteLock
*/
ReadWriteLock getReadWriteLock();
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!