
一、spring中bean的生命周期回顾
要理解spring中的循环依赖问题需要先了解spring中bean的生命周期,spring中创建bean的过程中主要有这几个阶段:
实例化前 $\rightarrow$ 实例化 $\rightarrow$ 属性填充 $\rightarrow$ 初始化前 $\rightarrow$ 初始化 $\rightarrow$ 初始化后
而循环依赖问题会出现在属性填充阶段
二、循环依赖问题
假设现在有AService和BService两个类需要加入到spring容器中,这两个类相互持有对方的引用
@Service
public class AService {
@Autowired
private BService bService;
}
---
@Service
public class BService {
@Autowired
private AService aService;
}
像上边这样把A,B都加入到容器中,A中需要依赖注入B,B中需要依赖注入A,这样就会产生循环依赖问题,下面我通过bean的生命周期来说明下为何会产生循环依赖问题。
假设spring启动过程中先创建AService的Bean,就会开始走A的生命周期
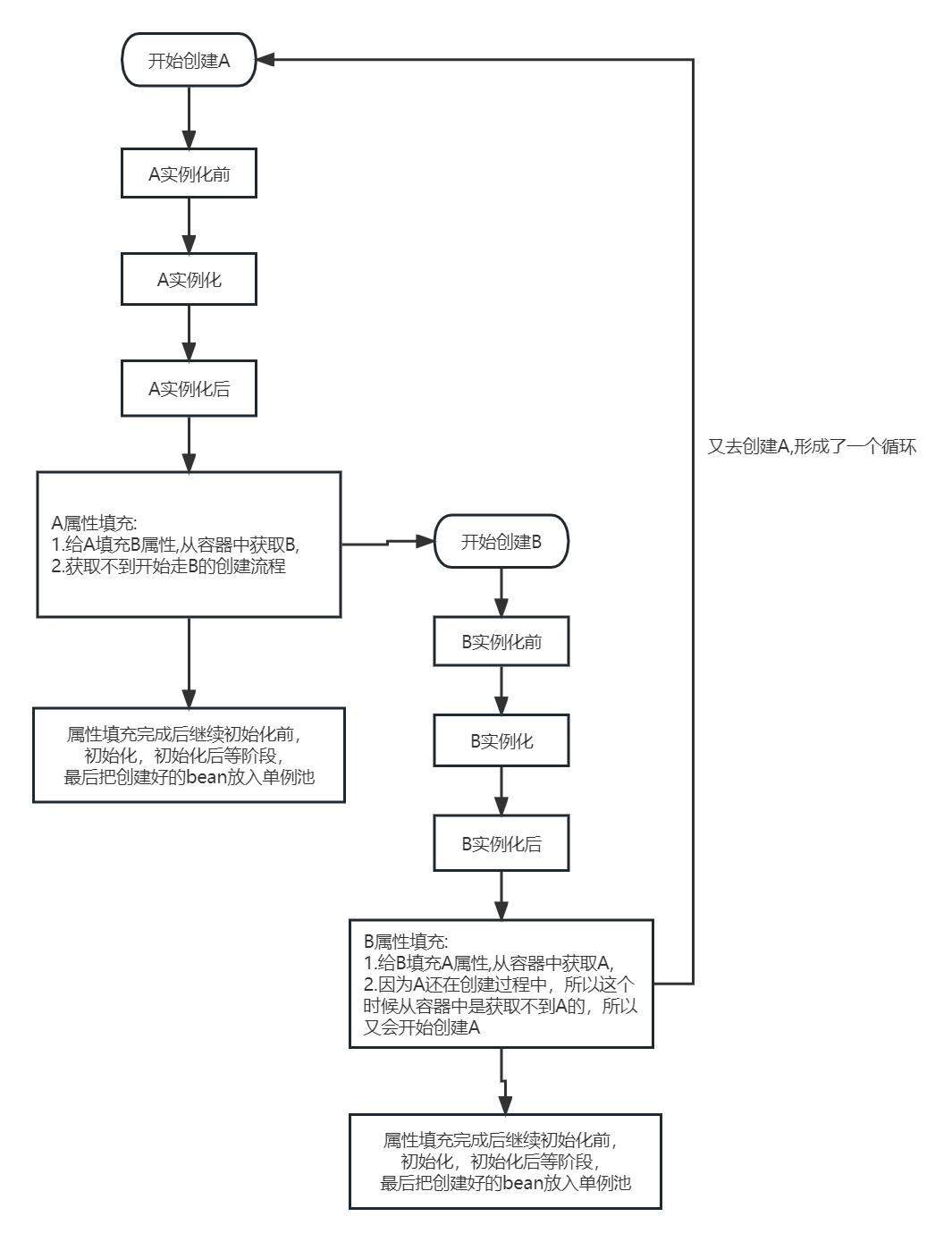
这就是循环依赖问题,下面来看下spring中如何解决循环依赖
三、spring中解决循环依赖问题的原理
在早期版本的spring中会有循环依赖问题,后来的spring中使用三级缓存解决了这种依赖注入形成的循环依赖。
先来看下三级缓存都指的是什么,这三个缓存都定义在DefaultSingletonBeanRegistry中
/** Cache of singleton objects: bean name to bean instance. */
// 一级缓存,存储所有的单例bean,从容器中获取单例bean时最终就是从这个map中获取
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
// 三级缓存,ObjectFactory可以看做是一个lambda表达式,存储获取bean对象的表达式,从三级缓存中获取到这 // 个表达式后执行就会得到一个半成品bean
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
// 二级缓存,存储哪些需要提前向外暴露供其他bean的使用的半成品bean
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
要理解三级缓存的作用需要先对spring创建bean的过程有较深入的了解,首先在ApplicationContext类型的spring容器启动过程中会创建所有的单例bean,这里的创建bean其实就是调用其内部beanfactory容器的
getBean(String name)方法。触发的入口是在AbstractApplicationContext.refresh方法。
下面先简单描述下spring创建bean的过程
(1) 开始创建A
(2) 调用beanfactory.getBean('A')从容器中获取A
(3) 从一级缓存(单例池中获取A)
(4) 获取不到 调用beanFactory.createBean方法创建bean
(5) 实例化前,实例化A得到A的普通对象,把A的普通对象用一个lambad表达式包装后放入三级缓存,三级缓存中放的是一个lambada表达式,
实例化后
(6) 开始A的属性填充
(7) 填充属性B, 从容器中获取B,调用beanfactory.getBean('B')
(8) 从一级缓存(单例池中获取B),获取不到执行beanFactory.createBean 开始创建B
(9) B的实例化前,实例化,包装后放入3三级缓存,实例化后 ,属性填充
(10) 填充B中的属性A,从容器中获取A,即调用beanfactory.getBean('A')
(11) 这个时候就能在getBean方法中判断出产生了循环依赖
然后就会先从一级缓存获取,
获取不到就从二级缓存获取;
再从三级缓存获取到包装A普通对象的lambda表达式并执行得到提前暴露的bean A,
然后删除三级缓存,
把bean A 放入二级缓存
返回bean A
(12) 这样beanfactory.getBean('A')拿到了A,所以可以完成B中对A的属性填充
(13) B中其他属性的填充
B执行初始化前
B执行初始化后
(14) B创建完成,
把B放入一级缓存,
清除二级和三级缓存
因为这个创建B的流程是在给A中填充B
的时候调用beanfactory.getBean('B')
触发的,所以会回到A的创建流程中把A的
B属性填充完
填充A的其余属性
(15) A初始化前,A初始化,A初始化后
(16) A创建完成,把A放入一级缓存,
清除二级缓存和三级缓存中的A
至此,A和B都创建完成了
以上这些步骤描述了A和B有循环依赖时是spring是如何创建的,三种缓存是怎样配合起来工作的。
接下来来分析下为什么需要三种缓存,先来看下三级缓存。
首先可以注意到三级缓存中存储的时候key是beanName,value是一个lambda表达式,这个表达式包装了bean的普通对象,从三级缓存中获取对象时会先得到这个表达式然后执行得到提前暴露的bean对象。
为什么需要用一个表达式包装呢?这是为了提前进行动态代理。在没有循环依赖问题时,动态代理是在bean生命周期的初始化后阶段进行的,最终放入容器中的是代理对象,对其他bean属性注入时注入的也是代理对象。但在有循环依赖问题时spring会提前暴露半成品bean给其他的bean以打破循环,就是上边的三级缓存,如果不通过三级缓存提前进行动态代理给其他bean中注入的就成了bean对象本身而不是代理对象,这就是三级缓存的作用:提前进行动态代理。
那么为什么需要二级缓存呢? 单看上面的流程,引入三级缓存后就可以打破循环并很好的解决了动态代理的问题,二级缓存是为了在一个bean跟多个bean有循环依赖时保证只进行一次动态代理。
假设 A依赖B,A依赖C,B依赖A,C依赖A,这样A同时和B、C两个bean有循环依赖,A需要进行动态代理,先按上边的流程走一下,
(1) 创建A时先实例化A把A的实例包装后放入三级缓存,
(2) 对A属性注入发现需要B,开始创建B,实例化B包装后放入三级缓存
(3) 对B属性注入发现需要A,从容器中获取A
(4) 从三级缓存获取到A提前进行冬天代理得到proxy1注入给B
(5) 把B的流程走完,回到A中
(6) 把A的属性B填充完,继续填充C,开始创建C,实例化C包装后放入三级缓存
(7) 对C属性注入发现需要A,从容器中获取A
(8) 从三级缓存获取到A提前进行冬天代理得到proxy2注入给C
注意看这里的第8步又新生成了一个代理对象,这样就会造成B中的A和C中的A的不是同一个,二级缓存就是为了解决这个问题。在第4步生成代理对象proxy1后把proxy1放入二级缓存并删除三级缓存,然后第8步时就会从二级缓存中获取到proxy1,这样就保证了A的代理对象只有一个。
四、总结
一级缓存中放的是最终创建好的单例对象,三级缓存中放的是包装后的半成品bean,从三级缓存中获取时可以提前进行动态代理,二级缓存中放的是从三级缓存中获取时提前进行动态代理后生成的代理对象。


