

概述:
MySQL 复制是将一台服务器数据库的数据复制到另外一台或多台服务器数据库当中,他主要通过将数据以日志的方式进行网络传输,然后通过在slave 读取日志消息,与主库进行同步。
MySQL复制支持两种复制类型:基于语句的复制(SBR),它复制整个SQL语句;和基于行的复制(RBR),它仅复制更改的行。您还可以使用第三种混合混合复制(MBR)。
MySQL支持两种复制模式:基于二进制日志文件位置进行复制,全局事务标识符进行复制(在5.6版本当中推出了 GTID 复制)。
关于复制的更多资料可以去看一下官方文档 https://dev.mysql.com/doc/refman/5.7/en/replication.html
复制的优点
- 读写分离,分散负载以提高性能,写入与更新在主库上面进行,读取在一台或多台从库进行。
- 提高安全性 ,在MySQL数据库可能因为某个原因宕机的时候,我们可以进行主从切换,让MySQL 继续运行,防止系统瘫痪。 在数据备份的时候,因为数据已经复制到slave,并且slave可以暂停复制,所以在副本上运行备份服务而不会破坏相应的源数据等。
- 需要进行数据分析的时候,可以将一台从库上进行,而不会影响源的性能。
- 方便拓展,可以方便的通过添加从库来负载,但是多个从库不能过多的连接一台主库,这样主库的压力就会增大,网络带宽的压力也会增大。
复制解决的问题
- 使用复制进行备份
- 处理slave 意外停止
- 不同的master 和 slave 存储引擎中使用复制
- 使用复制进行从库拓展
- 故障转移期间切换源
- 不同的数据库复制到不同的slave
- 半同步复制
- 延迟复制
- 提高复制性能
- 设置复制以使用加密的连接
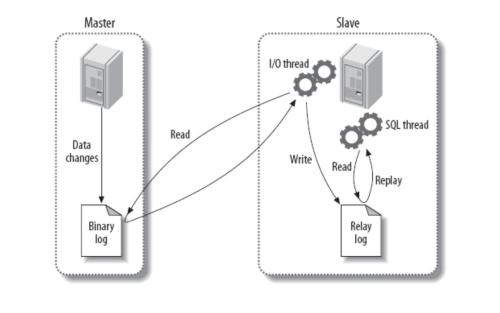
复制如何工作
- 在主库把数据更改记录到二进制日志中(Binary Log)中。(这些记录被称作二进制日志事件)
- 备库通过 I/O 线程将主库上的日志复制到自己的中继日志中
- 备库通过SQL线程读取中继日志的事件,将其重放到备库数据之上。
配置复制
1. 在每台服务器上创建复制账号,并赋予 REPLAITION SLAVE 权限,然后刷新权限。
CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com'; flush privileges;
2. 配置主库和备库的配置文件
# master
server_id = 2 log_bin = mysql-bin
...
# slave
server_id = 3
log_bin = mysql-bin
relay-log = /data/relaylog // 中继日志
...
对于复制,有几种情况:
(1) 待复制的master 没有新增数据,例如新安装的MySQL 实例。这种情况可以跳过恢复过程
(2) 待复制的master 存在数据,这时需要将这些数据也同步到slave上,并且获取master 上binlog 当前的坐标,只有slave和master的数据能匹配上,slave重放relay log 时才不会出错。
关于第一种情况,这里不在叙述,第二种情况有几种方法,例如使用 mysqldump、冷备份、xtrabackup等工具,这其中又需要考虑是MyISAM表还是InnoDB表。
获取master 二进制日志坐标
如果master 是全新的数据库实例,或者在此之前没有开启binlog,那么他的坐标位置是position=4。之所以是4而不是0,是因为binlog的前四个记录单元是每个binlog文件的头部信息。
如果master 已有数据,或者说之前开启了binlog 日志,并写入或修改过数据库,那么我们需要手动获取position。为了安全以及数据的同步,必须先锁表。(刷新所有表并阻止写入,这里使用 flush tables语句的客户端保持运行状态,以使读锁保持有效,如果退出客户端,则锁将会失效)
# 使用命令行客户端连接到 master, 并使用以下命令
flush tables with read lock;
# 重新开启一个会话,使用一下SQL 语句确定当前二进制文件的名称和位置
show master status;
备份master数据到slave 上
1、方式一:使用冷备份直接copy。这种情况只适用于没有新写入操作。严谨一点,只适合拷贝在没有完成前master不能有写入操作。
如果要复制所有的数据库,那么可以拷贝整个data目录
如果要复制的是某个或某几个库,直接拷贝相关目录即可。但注意,这种冷备份的方式只适合MyISAM表和开启了innodb_file_per_table=ON的InnoDB表。如果没有开启该变量,innodb表使用公共表空间,无法直接冷备份。
如果要冷备份InnoDB表,最安全的方法是先关闭master的MySQL,而不是通过锁表来操作。
如果没有设计到InnoDB表,可以直接在锁表后,进行冷copy,最后释放锁
# 锁表 flush tables with read lock; #查看日志信息,和坐标位置等 show master status; # 远程推送 rsync -avz /data 192.168.8.100:/ # 释放锁 unlock tables;
如果设计到了InnoDB表,建议关闭MySQL。因为是冷备份,所以slave 也应该关闭
mysqladmin -uroot -p shutdown
然后拷贝data 目录到slave上(当然,有些文件是不用拷贝的,比如master上的binlog、mysql库等)。
# 将master的datadir(/data)拷贝到slave的datadir(/data) shell> rsync -avz /data 192.168.100.150:/
需要注意,在冷备份的时候,需要将备份到目标主机上的DATADIR/auto.conf删除,这个文件中记录的是mysql server的UUID,而master和slave的UUID必须不能一致。
然后重启master和slave。因为重启了master,所以binlog已经滚动了,不过这次不用再查看binlog坐标,因为重启造成的binlog日志移动不会影响slave。
2、使用mysqldump工具创建要复制的所有数据库的转储。推荐使用,尤其是使用InnoDB。
# 将所有的数据库转储到名为dbdump.db 文件当中。关于 mysqldump 数据备份如果不懂可以去官网查看文档。
shell> mysqldump --all-databases --master-data > dbdump.db
注意,--master-data选项将再dump.db中加入change master to相关的语句,值为2时,change master to语句是注释掉的,值为1或者没有提供值时,这些语句是直接激活的。同时,--master-data会锁定所有表(如果同时使用了--single-transaction,则不是锁所有表,详细内容请参见mysqldump)。
因此,可以直接从dump.db中获取到binlog的坐标。记住这个坐标。
shell> grep -i -m 1 'change master to' dump.db -- CHANGE MASTER TO MASTER_LOG_FILE='master-bin.000002', MASTER_LOG_POS=154;
然后将dump.db拷贝到slave上,使用mysql执行dump.db脚本即可。也可以直接在master上远程连接到slave上执行。例如:
shell> mysql -uroot -p -h 192.168.100.150 -e 'source dump.db'
3、使用xtrabackup 进行备份恢复
这是三种方式中最佳的方式,安全性高、速度快。因为xtrabackup备份的时候会记录master的binlog的坐标,因此也无需手动获取binlog坐标。
xtrabackup详细的备份方法见:xtrabackup
注意:master和slave上都安装percona-xtrabackup。
以全备份为例:
innobackupex -u root -p /backup
备份完成后,在/backup下生成一个以时间为名称的目录。其内文件如下:
[root@xuexi ~]# ll /backup/2018-05-29_04-12-15 total 77872 -rw-r----- 1 root root 489 May 29 04:12 backup-my.cnf drwxr-x--- 2 root root 4096 May 29 04:12 backuptest -rw-r----- 1 root root 1560 May 29 04:12 ib_buffer_pool -rw-r----- 1 root root 79691776 May 29 04:12 ibdata1 drwxr-x--- 2 root root 4096 May 29 04:12 mysql drwxr-x--- 2 root root 4096 May 29 04:12 performance_schema drwxr-x--- 2 root root 12288 May 29 04:12 sys -rw-r----- 1 root root 22 May 29 04:12 xtrabackup_binlog_info -rw-r----- 1 root root 115 May 29 04:12 xtrabackup_checkpoints -rw-r----- 1 root root 461 May 29 04:12 xtrabackup_info -rw-r----- 1 root root 2560 May 29 04:12 xtrabackup_logfile
其中xtrabackup_binlog_info中记录了binlog的坐标。记住这个坐标。
shell> cat /backup/2018-05-29_04-12-15/xtrabackup_binlog_info master-bin.000002 154
然后将备份的数据执行"准备"阶段。这个阶段不要求连接mysql,因此不用给连接选项。
innobackupex --apply-log /backup/2018-05-29_04-12-15
最后,将/backup目录拷贝到slave上进行恢复。恢复的阶段就是向MySQL的datadir拷贝。但注意,xtrabackup恢复阶段要求datadir必须为空目录。否则报错:
shell> innobackupex --copy-back /backup/2018-05-29_04-12-15/ 180529 23:54:27 innobackupex: Starting the copy-back operation IMPORTANT: Please check that the copy-back run completes successfully. At the end of a successful copy-back run innobackupex prints "completed OK!". innobackupex version 2.4.11 based on MySQL server 5.7.19 Linux (x86_64) (revision id: b4e0db5) Original data directory /data is not empty!
所以,停止slave的mysql并清空datadir。
shell> innobackupex --copy-back /backup/2018-05-29_04-12-15/ 180529 23:55:53 completed OK!
恢复完成后,MySQL的datadir的文件的所有者和属组是innobackupex的调用者,所以需要改回mysql.mysql。
chown -R mysql.mysql /data
启动slave,并查看恢复是否成功。
shell> service mysqld start shell> mysql -uroot -p -e 'select * from backuptest.num_isam limit 10;'
3. 启动复制
mysql> change master to
master_host='192.168.8.113',
master_user='username',
master_password='123456',
master_port=3306,
master_connect_retry=10,
master_log_pos=0,
master_log_file='mysql-bin-000001';
启动IO线程和SQL线程
# 一次性启动、关闭
start slave;
stop slave;
# 单独启动
start slave io_thread;
start slave sql_thread;
到这里主从复制就完成了。oh
完成之后可以在slave 查看信息,通过 show slave status\G
主从延迟解决的思路
slave通过IO线程获取master的binlog,并通过SQL线程来应用获取到的日志。因为各个方面的原因,经常会出现slave的延迟(即Seconds_Behind_Master的值)非常高(动辄几天的延迟是常见的,几个小时的延迟已经算短的),使得主从状态不一致。
一个很容易理解的延迟示例是:假如master串行执行一个大事务需要30分钟,那么slave应用这个事务也大约要30分钟,从master提交的那一刻开始,slave的延迟就是30分钟,更极端一点,由于binlog的记录时间点是在事务提交时,如果这个大事务的日志量很大,比如要传输10多分钟,那么很可能延迟要达到40分钟左右。而且更严重的是,这种延迟具有滚雪球的特性,从延迟开始,很容易导致后续加剧延迟。
所以,第一个优化方式是不要在mysql中使用大事务,这是mysql主从优化的第一口诀。
在回归正题,要解决slave的高延迟问题,先要知道Second_Behind_Master是如何计算延迟的:SQL线程比IO线程慢多少(其本质是NOW()减去Exec_Master_Log_Pos处设置的TIMESTAMP)。在主从网络状态良好的情况下,IO线程和master的binlog大多数时候都能保持一致(也即是IO线程没有多少延迟,除非事务非常大,导致二进制日志传输时间久,但mysql优化的一个最基本口诀就是大事务切成小事务),所以在这种理想状态下,可以认为主从延迟说的是slave上的数据状态比master要延迟多少。它的计数单位是秒。
1.从产生Binlog的master上考虑,可以在master上应用group commit的功能,并设置参数binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count,前者表示延迟多少秒才提交事务,后者表示要堆积多少个事务之后再提交。这样一来,事务的产生速度降低,slave的SQL线程相对就得到缓解。
2.再者从slave上考虑,可以在slave上开启多线程复制(MTS)功能,让多个SQL线程同时从一个IO线程中取事务进行应用,这对于多核CPU来说是非常有效的手段。但是前面介绍多线程复制的时候说过,没有掌握多线程复制的方方面面之前,千万不要在生产环境中使用多线程复制,要是出现gap问题,很让人崩溃。
3.最后从架构上考虑。主从延迟是因为slave跟不上master的速度,那么可以考虑对master进行节流控制,让master的性能下降,从而变相提高slave的能力。这种方法肯定是没人用的,但确实是一种方法,提供了一种思路,比如slave使用性能比master更好的硬件。另一种比较可取的方式是加多个中间slave层(也就是master->slaves->slaves),让多个中间slave层专注于复制(也可作为非业务的他用,比如用于备份)。
4.使用组复制或者Galera/PXC的多写节点,此外还可以设置相关参数,让它们对延迟自行调整。但一般都不需要调整,因为有默认设置。
还有比较细致的方面可以降低延迟,比如设置为row格式的Binlog要比statement要好,因为不需要额外执行语句,直接修改数据即可。比如master设置保证数据一致性的日志刷盘规则(sync_binlog/innodb_flush_log_at_trx_commit设置为1),而slave关闭binlog或者设置性能优先于数据一致性的binlog刷盘规则。再比如设置slave的隔离级别使得slave的锁粒度放大,不会轻易锁表(多线程复制时避免使用此方法)。还有很多方面,选择好的磁盘,设计好分库分表的结构等等,这些都是直接全局的,实在没什么必要在这里多做解释。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号