
1、元组与列表的的区别是什么?
2、在列表中,append与insert的方法区别是什么?请举例说明
append是最后添加
insert是是根据索引位置添加
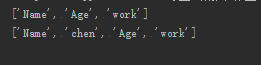
list1=['Name','Age']
list1.append('work')
print(list1)
list1.insert(1,'chen')
print(list1)
执行以上代码,执行介入如下:
3、在字符串中,判断字符串开头和字符串结束使用的方法是什么?请举例说明
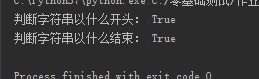
str1='what are you doing'
print('判断字符串以什么开头:',str1.startswith('w'))
print('判断字符串以什么结束:',str1.endswith('g'))
执行以上代码,结果如下:
4、请详细的描述变量的生命周期
变量在调用的时候会分配内存地址,调用结束会释放内存信息
5、请举例说明字符串格式化的使用
name = input("请输入你的姓名:\n")
age = input("请输入你的年龄:\n")
salary = float(input("请输入你的薪资:\n"))
isBoy = bool(input("男的还是女的?\n"))
print('my name is {0},and my age is {1},and my salary is {2},and'
' my sex is {3}'.format(name, age, salary, isBoy))
print('我的姓名:%s,我的年龄:%s,我的薪资:%s,我的性别:%s'
'' % (name, age, salary, isBoy))
print('我的姓名:{name},我的年龄:{age},我的薪资:{salary},我的性别:{isBoy}'
''.format(name=name, age=age, salary=salary, isBoy=isBoy))
执行以上代码,结果如下:

6、请举例说明列表中sort()方法的使用
list1=[33,455,65,7,87,98,3,54] list1.sort() print(list1)
执行以上代码,结果如下:

7、请举例说明列表切片的使用
list1=[33,455,65,7,87,98,3,54] #切片 (第几位到第几位)(显示第一位,不显示最后一位) print(list1[0:2]) #显示最后一位 print(list1[-1])
执行以上代码,结果如下 :

8、怎么获取列表中最后一位元素?举例说明
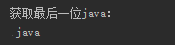
list1=[[33,455,65,7],['python','java']]
print('获取最后一位java:\n',list1[1][1])
执行以上代码,结果如下:
9、字典是有序的吗?
字典是无序的,这是字典的一个特性,它的第二个特性是字典可以使用key-value的方式来存储数据
9、针对字典以key排序举例说明
dict3={'name':'chen','age': 19,'address':'beijing','work':'tester','salary':10023}
print('对字典的key排序:\n',dict(sorted(dict3.items(),key=lambda item:item[0])))
执行以上代码。。结果如下:

10、针对字典以value排序举例说明
dict1={"name":"wuya","age":"18","address":"xian"}
print(dict(sorted(dict1.items(),key=lambda item:item[1])))
执行以上代码,输入结果为:

11、举例说明函数的定义和调用
函数的定义:把重复的代码单独分离出来,放在一个公共的地方,以后可以一致调用,就解决的多次重复编写
优势:
1、减少重复代码的使用
2、程序变得可扩展
3、程序变得可容易维护
函数的调用:
把一组语句的集合用函数名封装起来,如果想要执行这个函数,只需要调用这个函数名就可以
如:
def fun1():
print('holle')
def fun2():
print('chen')
if __name__ == '__main__':
fun1()
执行以上代码,结果如下:

12、详细描述形式参数与实际参数,并举例说明
形式参数:形式参数只有在函数在进行被调用的时候才会在内存中分配内存单元,在调用结束后,即刻释放所分配的内存单元。所以说,形式参数只有在函数内部是有效的。
实际参数:实际参数就是函数在被调用的时候,赋予形式参数具体的值,也就是实际参数
#形式参数 def add(a,b): print(a+b) #实际参数 add(a=23,b=3)
执行以上代码,结果如下:

13、举例说明默认参数的使用
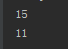
#默认参数 #默认参数要放在位置参数后面,当遇到带有默认值的参数时候,这个参数可以不传值 def func(a,b,c=10): print(a+b+c) func(2,3) func(2,4,5)
执行以上代码,结果如下:
14、什么情况下使用动态参数,举例说明?
1、当函数的形式参数不确定的时候
2、当函数形式参数的数据类型不确定的时候
*:代表的是元组
**:代表的是字典
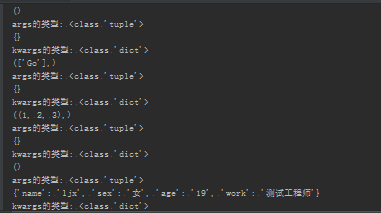
def func(*args, **kwargs):
print(args)
print('args的类型:', type(args))
print(kwargs)
print('kwargs的类型:', type(kwargs))
#形式参数为空
func()
#形式参数是列表
func(["Go"])
#形式参数是元组
func((1,2,3))
#形式参数是字典
func(name='ljx',sex='女',age='19',work='测试工程师')
执行以上代码,结果如下:
函数的形式参数也可以是函数:
#函数的形式参数也可以是函数
def fun1():
print("Holle chen")
def fun3(func):
print(func)
fun3(func=fun1())
执行以上代码,结果如下:

15、举例说明函数返回值的使用
#函数的返回值
def login(username,password):
if username=='chen' and password=='asd':
return 'denglu'
def profile(token):
if token=='denglu':
print('进入登陆')
else:
print('重新登陆')
if __name__ == '__main__':
profile(token=login(username='chen',password='asd'))
执行以上代码,结果如下:
16、怎么理解装饰器?请举例说明
可以用pycharm里面的 运行,查看相关的步骤:
运行,查看相关的步骤:
#outer装饰器的函数
def outer(func):
def inner(name):
print('holle')
return func(name)
#inner是inner()函数的对象
return inner
@outer
#被装饰的函数
def func1(name):
print()
func1(name='holle')
对以上代码的解释:
1、自动执行outer函数并且将其下面的函数名fun当作参数来传递
2、将outer函数的返回值(变量或者是函数),重新赋值给fun
3、一旦结合装饰器后,调用fun其实执行的是inner函数内部,原来的fun被覆盖
4、一旦这个函数被装饰器装饰之后,被装饰的函数重新赋值成装饰器的内层函数
执行以上代码,结果如下:
17、怎么理解Python中一切皆对象,这个对象具体是什么?
对象可以是变量,函数,类,只要符合python语法规则的都可以
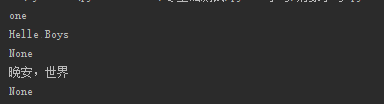
#变量
name='one'
#函数
def func():
print('Helle Boys')
#类
class Person(object):
def show(self):
print('晚安,世界')
#a是变量name
a=name
print(a)
#b是函数func的对象
b=func
print(b())
#c是类Person的的对象
c=Person
print(c().show())
执行以上代码,结果如下:
18、结合案例演示os库针对文件路径的处理
import os
# #获取当前路径
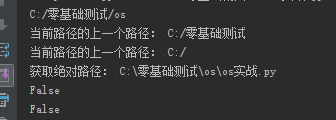
print(os.path.dirname(__file__))
# #获取当前的路径的上一个路径
print('当前路径的上一个路径:',os.path.dirname(os.path.dirname(__file__)))
# #获取当前路径的上一个路径的上一个路径
print('当前路径的上一个路径:',os.path.dirname(os.path.dirname(os.path.dirname(__file__))))
# #绝对路径
print('获取绝对路径:',os.path.abspath(__file__))
#获取当前目录下的文件
# print(os.system('date'))
# print(str(os.system('ls-la')).encode(('utf-8')))
#判断是否有目录
print(os.path.exists('usr/local'))
#判断是否是文件
print(os.path.isfile('usr/local'))
执行以上代码,结果如下:
19、结合文件IO操作演示文件模式w和a的区别
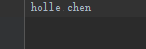
def fileW():
"""W模式"""
a=open('log.md','w')
a.write('holle chen')
a.close()
# fileW()
执行以上代码结果如下:创建一个log文件,并输入内容:
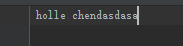
a模式:
def fileA():
a=open('log.md','a')
a.write('dasdasa')
a.close()
fileA()
执行以上代码,输入结果:
区别:
w:写,特点是先清空文件已有的内容,然后把新的内容填写进去
a:写,在文件已有内容的基础上增加新的内容
20、结合文件IO操作演示with上下文的使用
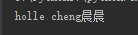
def filew():
with open('log.md','w') as f:
f.write('holle cheng')
# if __name__ == '__main__':
# filew()
def filea():
with open('log.md','a',encoding='utf-8') as f:
f.write('晨晨')
# if __name__ == '__main__':
# filea()
def readFile():
with open('log.md','r',encoding='utf-8') as f:
print(f.read())
if __name__ == '__main__':
readFile()
执行以上代码,结果如下:读取文件
21、怎么理解全局变量与局部变量
全局变量:在一个Python文件里面,定义的变量,可以把它理解为全局变量,在Python文件中,全局变量的优先级是高于 局部变量的
局部变量:在一个Python文件里面的函数里面,定义的变量,可以理解为局部变量,在函数内部,局部变量的优先级是高于全局变量的
在函数内部使用(引用)全局变量的时候,可以使用关键字global来引用,global申明全局变量
22、请描述全局变量与局部变量的优先级,举例说明
全局变量:在Python文件中,全局变量的优先级是高于 局部变量的
局部变量:在函数内部,局部变量的优先级是高于 全局变量的
局部变量:
name="123" def func(): name="456" print(name) func() print(name)
#在函数内部使用(引用)全局变量的时候,可以使用关键字global来引用,global申明全局变量 def fun(): global name name="kkk" print(name) fun()
执行以上代码,结果如下:

23、举例说明字符串中==,is,in的区别和应用
str7="chen"
str8="chen xin"
#in:判断的是两个对象中一个对象是否包含另外一个对象
if str7 in str8:
print("好的")
name1="123"
name2="123"
#is:判断的是两个对象的内存地址
if name1 is name2:
print("内存一致")
执行以上代码,结果如下:

24、列表lists=["Go","Pyhton","Java","Net"]进行循环输出
lists=["Go","Pyhton","Java","Net"] for item in lists: print(item)
执行以上代码,结果如下:

25、怎么理解序列化和反序列化?结合案例说明
序列化 :把python对象转换为字符串的数据类型,(把 python的数据类型(字典、元组,列表),转换为str数据类型的过程)
反序列化:就是把str的数据类型转换为python对象的过程(把str数据类型转换为python的数据类型(字典、元组,列表)的过程)
import json
list1=["Go","Http"]
list_str=json.dumps(list1)
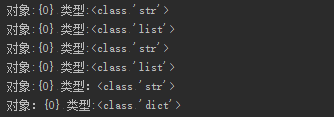
print('对象:{0}','类型:{1}'.format(list_str,type(list_str)))
str_list=json.loads(list_str)
print('对象:{0}','类型:{1}'.format(str_list,type(str_list)))
tuple1=("holle","work")
tuple_str=json.dumps(tuple1)
print('对象:{0}','类型:{1}'.format(tuple_str,type(tuple_str)))
str_tuple=json.loads(tuple_str)
print('对象:{0}','类型:{1}'.format(str_tuple,type(str_tuple)))
#字典和字符串之间的类型转换
dict1={'name':'chen','age':123}
dict_str=json.dumps(dict1)
print('对象:{0}','类型:{1}'.format(dict_str,type(dict_str)))
str_dict=json.loads(dict_str)
print('对象:{0}','类型:{1}'.format(str_dict,type(str_dict)))
执行以上代码,结果如下:
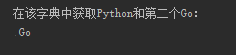
26、dict1={"data":[{"name":"wuya","datas":[{"first":"Go","second":["Python","Go","Java"]}]}]}在该字典中获取Python和第二个Go
dict1={"data":[{"name":"wuya","datas":[{"first":"Go","second":["Python","Go","Java"]}]}]}
print('在该字典中获取Python和第二个Go:\n',dict1['data'][0]['datas'][0]['second'][1])
执行以上代码,结果如下:
27、怎么理解break和continue,举例说明
break:跳出循环
continue:继续
while True:
score=int(input('输入学生成绩:\n'))
if score>=50 and score<=60:
print("成绩不合格")
elif score>=60 and score<=80:
print("成绩合格")
elif score>=80 and score<=100:
print("成绩优秀")
else:continue
执行以上代码,结果如下:

break:跳出循环
str1="火山为你洗浴!"
while True:
for item in str1:
print(item)
break
执行以上代码,输出结果:

28、字典data=["name":"lisi","work":"测试工程师","datas":[{"salary":1990.09,"age":19,"address":"西安市"},{"salary":1990,"age":20,"address":"兰州市"},{"salary":1990.09,"age":19,"address":[{"陕西省":[{"西安市":["雁塔区","临潼区"]}]}]}]]
输出“雁塔区”
data={"name":"lisi","work":"测试工程师","datas":[
{"salary":1990.09,"age":19,"address":"西安市"},
{"salary":1990,"age":20,"address":"兰州市"},
{"salary":1990.09,"age":19,"address":
[{"陕西省":[{"西安市":["雁塔区","临潼区"]}]}]}]}
print('获取雁塔区:\n',data['datas'][2]['address'][0]['陕西省'][0]['西安市'][0])
执行以上代码,结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号