
一、
''' 一、结合函数的返回值编写一本案例 需要用到return关键字返回结果 1、先确定好账号=## 密码=## 2、如果账号等于##,密码=##,返回return后面的值,如果错误,返回return的值,如果有多个返回结果,用token关键字 如果有多个返回结果,用token关键字 如果token等于成功登陆,进入界面,如果失败,输出 重新登陆 最后输出结果 '''
def user(username='chen',passwork='xin'):
if username=='chen' and passwork=='xin':
return '登陆成功'
else:
return '登陆失败'
def name(token):
if token=='登陆成功':
print('进入界面')
else:
print('请登录')
if __name__ == '__main__':
name(token=user())
执行以上代码,输出结果:

二、
'''
二、在一个Python的文件中,当全局变量名称与局部变量名称一致的时候,在Python文件中调用,那个优先级高?在函数内部,那个优先级高?
1、全局变量名称与局部变量名称一致的时候,在Python文件中调用,全局变量优先级高
2、全局变量名称与局部变量名称一致的时候,在函数内部调用,局部变量优先级高
思路:先创建一个变量,之后在函数的的内部创建一个相同的变量,运行
'''
name='username'
def fun():
name='username,work'
print(name)
if __name__ == '__main__':
fun()
执行以上代码,输出结果为:

三、
#三、、结合hashlib编写一个md5的加密的案例 '''思路:先导入hashlib库,再导入urllib库中的parse关键字, 1,先创建一个字典 2、用字典中的sorted关键字对字典进行acll的排序 3、把排序后的字典处理成key-value的形式 4、用关键字hashlib进行md5加密 5、换算成编码的方式 6、返回值为编码的的字符串方式 7、输入结果 '''
import hashlib
from urllib import parse
def nameMd5():
dict0={'name':'chen','age':100,'adderss':'beijing'}
datas=dict(sorted(dict0.items(),key=lambda item:item[0]))
datas=parse.urlencode(datas)
i=hashlib.md5()
i.update(datas.encode('utf-8'))
return i.hexdigest()
if __name__ == '__main__':
print(nameMd5())
执行以上代码,输出结果为:

四、
#四、对字典dict1={"name":"wuya","age":18,"work":"测试工程师","salary":1990}进行ascll码的排序
#1、排序的时候用到sored关键字排序,排序的时候按照首字母的顺序排列
dict1={"name":"wuya","age":18,"work":"测试工程师","salary":1990}
print(dict(sorted(dict1.items(),key=lambda item:item[0])))
执行以上代码,,执行结果为:
五、
#列表lists=["Go","Pyhton","Java","Net"]进行循环输出 #需要用到for循环列表的对象进行循环输入 lists=["Go","Pyhton","Java","Net"] def lieBiao(): for item in lists: print(item) if __name__ == '__main__': lieBiao()
执行以上代码,执行结果为:
六、
#列表里面添加新的元素,会使用到哪些方法,结合案例代码来举例 #往列表 里面添加有两种方法,第一个是append(在最后添加),第二个是insert(按照搜索引添加) list1=[34,54,65,7687,43] print(list1.append(100)) print(list1) print(list1.insert(3,'go')) print(list1)
执行以上代码,结果为:
七、
'''七、列表与元组的区别是什么? 1、列表: 1、列表是存储数据的 2、列表是可变化的:增删改查 元组: 1、不改变 2、不能增加和删除元组里面的内容 区别:列表是可变化的,元组是不可变的 '''
八、
#八、break怎么理解?结合案例代码说明 #思路,break时停止循环的意思 str1="打死都考了多少" while True: for item in str1: print(item) break
执行以上代码,输出结果为:
九、
#continue怎么理解?结合案例代码说明 #continue是继续的意思 :如 while True: cooerss=int(input("输入年龄:\n")) if cooerss<10: print('表示儿童') continue elif cooerss>=10 and cooerss<25: print("表示少年") continue elif cooerss>=25 and cooerss<50: print("表示中年") continue else: print('未知') break
执行以上代码,输出结果为:
十、
'''十、结合函数形式,编写一个登录注册的案例 1、首先,创建一个函数名,在变量名称填写登陆、注册、退出,并写上对应的序号,如,如果变量的名称是1,所对应的是登陆,如果名称是2,对应的是注册,如果是3对应的是退出,如果不是请继续 2、先注册,账户和密码,用with 和w 的方式清空并写入新的内容 3、登陆,用with和r的方式里面的内容读取出来,绕后用|划分开,以索引的方式填写账号,后填写密码,如果照顾好和密码正确,输出登陆,如果错误,输出”请重新登陆“''' #结合函数形式,编写一个登录注册的案例
import sys
def denglu():
username=input('输入账号:\n')
password=input('数入密码:\n')
with open('chen.tst','r') as d:
userInfo=d.read()
lists=userInfo.split('|')
if lists[0]==username and lists[1]==password:
print('登陆')
else:
print('输入账号密码错误')
def zhuce():
username=input('输入账号:\n')
password=input('输入密码:\n')
temp=username+'|'+password
with open('chen.tst','w') as d:
d.write(temp)
def fun():
while True:
try:
c=int(input("1、登陆,2、注册,3、退出:\n"))
if c==1:
denglu()
elif c==2:
zhuce()
elif c==3:
sys.exit()
else:continue
except Exception as x:
continue
if __name__ == '__main__':
fun()
执行以上代码,输出结果为:

十一、
'''十一、怎么理解序列化和反序列化?结合案例说明
1、首先,创建一个函数名,在变量名称填写登陆、注册、退出,并写上对应的序号,如,如果变量的名称是1,所对应的是登陆,如果名称是2,对应的是注册,如果是3对应的是退出,如果不是请继续
2、先注册,账户和密码,用序列化的方式把账号和密码写进去,
3、登陆,用反序列化的方式把文件里面的内容读取出来,绕后用|划分开,以索引的方式填写账号,后填写密码,如果照顾好和密码正确,输出登陆,如果错误,输出”请重新登陆“'''
import sys
import json
def out():
username= input('输入账号:\n')
password= input('数入密码:\n')
return username,password
def denglu():
username,password=out()
userword=json.load(open('chen.txt'))
lists=userword.split('|')
print('ok:',lists)
if lists[0]==username and lists[1]==password:
print('登陆')
else:
print('输入账号密码错误')
def zhuce():
username,password=out()
temp=username+'|'+password
json.dump(temp,open('chen.txt','w'))
def fun():
while True:
try:
c=int(input("1、登陆,2、注册,3、退出:\n"))
if c==1:
denglu()
elif c==2:
zhuce()
elif c==3:
sys.exit()
else:continue
except Exception as x:
continue
if __name__ == '__main__':
fun()
执行以上代码,输出结果:
十二、
'''十二:怎么理解针对文件的序列化和反序列化 1、反序列化就是读取文件里面的内容,用到 =json.dump() 2、序列化就是把内容写道文件里面去,json.dump(temp ,op()) 3、反序列化是在函数外面输出,序列化是在函数里面输出''' import json def work(): name='Holle chen' json.dump(name,open('ccct.tet','w')) name=json.load(open('ccct.tet')) print(name) if __name__ == '__main__': work()
执行以上代码,输出结果为: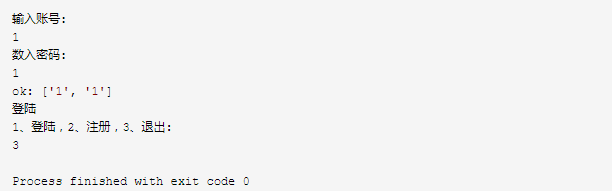
十三、
#举例说名os模块对路径的处理 import os print('查看路径的方法:',os.__all__) print('获取绝对路径:',os.path.abspath('c/Users')) print('对路径分割:',os.path.split('c/Users')) print('判断是不是目录:',os.path.isdir('c/Users')) print('获取当前路径:',os.path.dirname(__file__)) print('获取当前路径的上一级路径:',os.path.dirname(os.path.dirname(__file__))) print('获取当前路径的上上级路径:',os.path.dirname(os.path.dirname(os.path.dirname(__file__)))) base_dir=os.path.dirname(os.path.dirname(os.path.dirname(__file__))) #获取logout的路径 print(os.path.join(base_dir,'函数','logout'))
执行以上代码,结果如下:
查看路径的方法: ['altsep', 'curdir', 'pardir', 'sep', 'pathsep', 'linesep', 'defpath', 'name', 'path', 'devnull', 'SEEK_SET', 'SEEK_CUR', 'SEEK_END', 'fsencode', 'fsdecode', 'get_exec_path', 'fdopen', 'popen', 'extsep', '_exit', 'DirEntry', 'F_OK', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'R_OK', 'TMP_MAX', 'W_OK', 'X_OK', 'abort', 'access', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'device_encoding', 'dup', 'dup2', 'environ', 'error', 'execv', 'execve', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'link', 'listdir', 'lseek', 'lstat', 'mkdir', 'open', 'pipe', 'putenv', 'read', 'readlink', 'remove', 'rename', 'replace', 'rmdir', 'scandir', 'set_handle_inheritable', 'set_inheritable', 'spawnv', 'spawnve', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'symlink', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'unsetenv', 'urandom', 'utime', 'waitpid', 'waitstatus_to_exitcode', 'write', 'makedirs', 'removedirs', 'renames', 'walk', 'execl', 'execle', 'execlp', 'execlpe', 'execvp', 'execvpe', 'getenv', 'supports_bytes_environ', 'spawnl', 'spawnle'] 获取绝对路径: C:\Users\Administrator.lwp-PC\PycharmProjects\untitled\函数\c\Users 对路径分割: ('c', 'Users') 判断是不是目录: False 获取当前路径: C:\Users\Administrator.lwp-PC\PycharmProjects\untitled\函数 获取当前路径的上一级路径: C:\Users\Administrator.lwp-PC\PycharmProjects\untitled 获取当前路径的上上级路径: C:\Users\Administrator.lwp-PC\PycharmProjects C:\Users\Administrator.lwp-PC\PycharmProjects\函数\logout Process finished with exit code 0
十四、
#使用datetime的模块,在当前时间基础上增加10天 #思路:先要导入datetime和time,根据要加的天数添加
import datetime import time #在当前基础时间添加10天 print(datetime.datetime.now()+datetime.timedelta(days=10))
执行以上代码,输出结果为:
十五、
'''十五、举例说明函数的动态参数的应用 1、当函数类型不确定的时候或者数据个数不确定的时候使用动态参数 2、使用*确定是哪种数据类型,*是元组,**是字典,可以查看数据类型 3、后面 确定好数据类型后,可以对进行添加的数据判断是那个数据类型,如:''' def age(*args,**kwargs): print(args) print(type(args)) print(kwargs) print(type(kwargs)) age((1,2,34,56,89),name='xin',age='89') if __name__ == '__main__': age()
执行以上代码,结果为: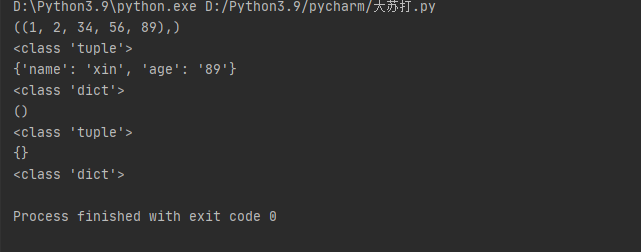

 浙公网安备 33010602011771号
浙公网安备 33010602011771号