
机器学习之随机森林(学习笔记)
1.随机森林算法采用Bootstrap(有放回的随机采样)采样从样本集中选出n个样本,但是更进一步,它从所以属性中随机选取K个属性,然后再选择最佳分割属性最为节点建立CART决策树。随机森林算法进行了两次采样。重复以上步骤k次,建立k棵CART决策树,这k颗CART决策树构成随机森林,通过投票的方式决定数据是属于哪一类的。
2.样本抽样(Bagging):
从原始的数据集中有放回的地随机抽取K个与原样本集同样大小的训练集{Tk,k=1,2...k},由每个训练样本Tk构造一棵决策树。
3.特征子空间抽样:
从全部属性中等概率随机抽取一个属性子集(通常取(|log2(M)|+1)个属性,M为特征总数),再从这个子集中选取一个最优属性来分裂节点。
4.随机森林的特点
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
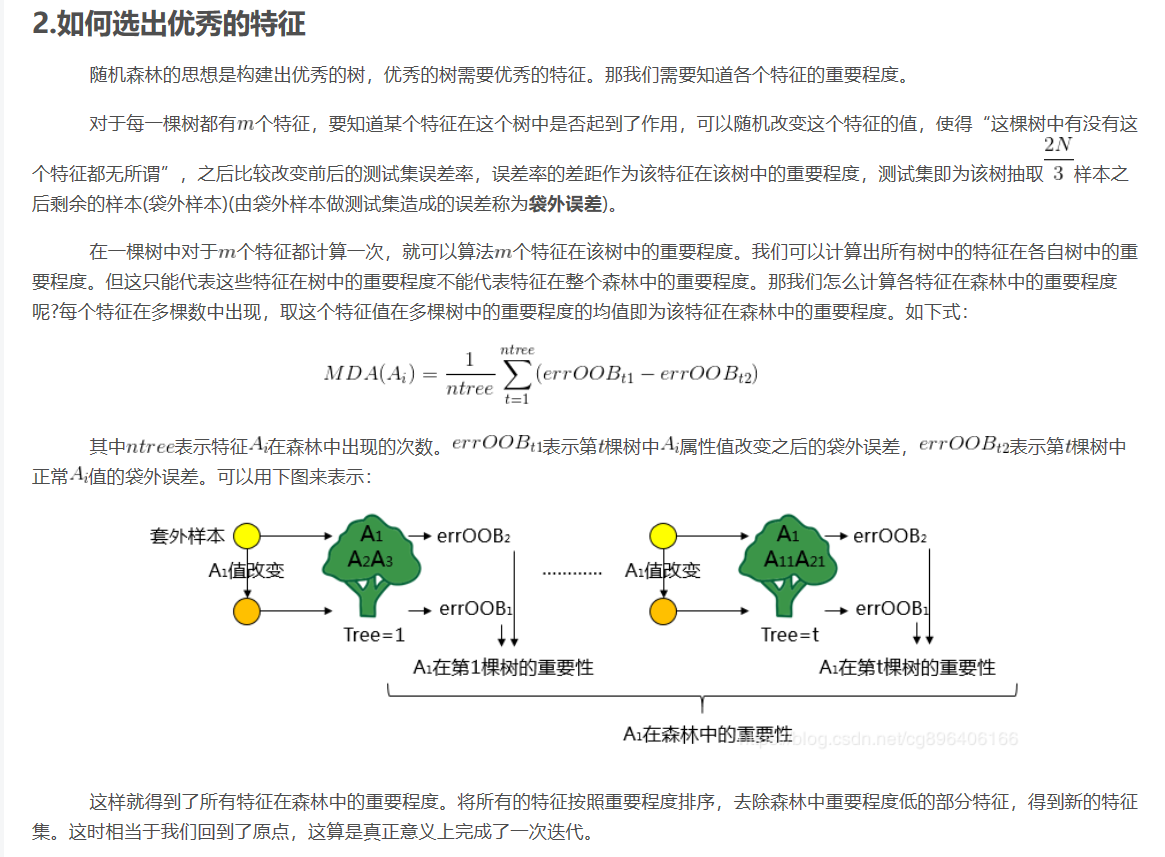
- 能够评估各个特征在分类问题上的重要性
- 在生成过程中,能够获取到内部生成误差的一种无偏估计
- 对于缺省值问题也能够获得很好得结果
5.随机森林如何选择优秀的特征:
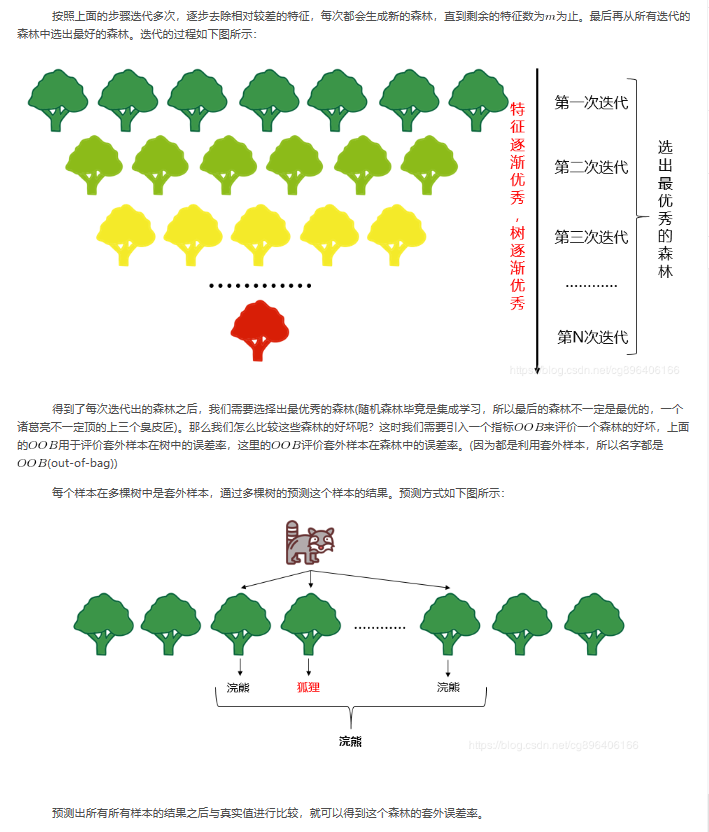
6.如何选择最优秀的森林:
7.随机森林分类器的相关参数介绍:
https://blog.csdn.net/w952470866/article/details/78987265
