
hibernate学习---检索优化
Hibernate框架对检索进行了优化,前面我们将CURD的时候提到了load和get的区别,当时仅仅说了load为延迟加载,get为立即加载,当检索的记录为空的时候load报错(不是在执行load方法的时候报的错,是执行后面的操作报的错),get返回null。
其实load就是对检索的一种优化,它的作用是当程序执行检索代码的时候,在缓存中没有的前提下,不会立即去数据库中查询,而是等真正用到的时候才会去查询,这是一种懒加载策略。
下面我们要讲的内容有:
- 当前对象的检索优化
- 关联对象的检索优化
当前对象的检索优化:
当前对象:这个概念存在于单表查询,可以认为是我们直接查询的对象(多表查询中我们有关联查询)。
当前对象的检索优化很简单,就是我们不使用get进行查询,使用load进行查询。我们的映射配置文件中有一个属性就是用来设置懒加载的:

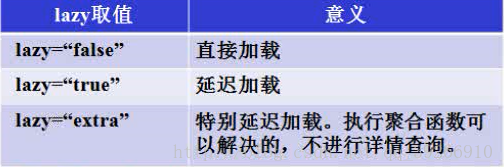
这个lazy属性默认是true(我们不设置的时候),即当我们使用load进行查询的时候是进行懒加载的,当配置文件设置lazy设置为false的时候,即使使用load也是立即加载,还有一个为extra叫做特懒加载(能用聚合函数查询就不进行详情查询)。
上面就是对当前对象的检索优化,很简单。
但是我们要知道load底层的原理是什么,为什么当查询的记录不存的时候会报错:
Hibernate的load是通过动态代理获得我们想要查询的对象的,当执行load时候,它获得的是代理类对象,此时并没有真正执行查询语句,当真正需要数据的时候(例如前台请求,或者我们测试的时候输出结果),查询语句才会执行。所以当我们执行查询语句的时候才会真正调用真实对象的查询方法,并为代理对象初始化(需要查询的值)。
为啥会出错呢?
我们来看看出错的地方:
这个是实现动态代理类的invoke方法:
public Object invoke( final Object proxy, final Method thisMethod, final Method proceed, final Object[] args) throws Throwable { if ( this.constructed ) { Object result; //调用父类的invoke方法 result = this.invoke( thisMethod, args, proxy ); //处理特殊返回结果 if ( result == INVOKE_IMPLEMENTATION ) { //最重要,这里最终会调用到获取最终数据的方法 Object target = getImplementation(); ...... //使用反射调用最终对象的最终方法,如xxx.getName()之类 returnValue = thisMethod.invoke( target, args ); }
public final Object getImplementation() { initialize();//初始化对象,或者叫实例化对象 return target; } public final void initialize() throws HibernateException { if (!initialized) { target = session.immediateLoad(entityName, id);//调用session,立即加载相应对象 initialized = true; checkTargetState();//这个方法检查是否为空 } }
private void checkTargetState() { if ( !unwrap ) { if ( target == null ) { getSession().getFactory().getEntityNotFoundDelegate().handleEntityNotFound( entityName, id );//这里就是报错的根源 } } }
以上的具体分析在我查到的一篇博客内有详细解答:
https://www.iflym.com/index.php/code/201112050001.html
关联对象的检索优化:
关联对象的检索优化分为两种:
- 多端加载优化
- 单端加载优化
我们先来说多端加载优化(我们下面所说的对一方查询都是使用HQL):
所谓多端关联加载对象是指一方为主加载对象,而多端为从加载对象,对于多方加载时所进行的延迟加载配置。
既然是“一”方为主加载对象,那么就需要在“一”方进行配置,在进行配置之前我们先来看两组属性:

lazy我们都知道,fetch是什么呢(字面意思是:拿来取来)。
这个是fetch在配置文件中的位置,是set标签内的属性。
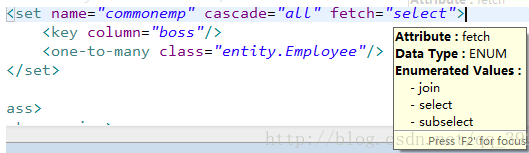
①当它为join的时候采用迫切左外连接(是立即加载,当配置这个属性的时候lazy失效)。当查找一方的时候因为我们使用的是左外连接(多表查询),所以效率上肯定比查找两张表的速度更快,即当查询一方的时候,多方的详情数据也被查询出来了。
②当fetch为select时,lazy为false时,采用普通select查询,当查询一方的时候,也会顺带将多方检查了,且都是通过直接查询加载的方式;lazy为true时,先查一方,多方为懒加载。
③当fetch为subselect时候,如果“一”里面有很多条记录,例如有三个部门,每个部门里面有十个员工,如果fetch为select,当遍历这些部门和员工的时候,每次都要先查询部门,然后再查询员工;但是如果使用子查询的话(fetch=“subselect”),只会查询一次部门详情,后面查询员工的时候不用再次查询部门,因为部门作为子查询进行。
说完多端加载优化我们再来说单端加载优化:
单端加载优化和多端加载优化用到的是同样的属性,但是它的属性取值不同且,配置是放在多方的。
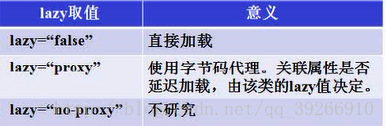

单端的配置在many-to-one标签中配置fetch
①当fetch=“join”时,和多端一样,lazy失效,使用的是迫切左外连接。
②当fetch=“select”时也是采用普通select查询。
当lazy为proxy时候和no-proxy,它们的使用决定代理方式(懒加载方式),是否为懒加载还要看“一”方的配置。
关于检索优化就说到这里。
版权声明:本文为博主原创文章,如需转载请表明出处。 https://blog.csdn.net/qq_39266910/article/details/78626965

