
基于RocketIO的高速串行协议设计与实现
随着对信息流量需求的不断增长, 传统并行接口技术成为进一步提高数据传输速率的瓶颈。过去主要用于光纤通信的串行通信技术—SERDES正在取代传统并行总线而成为高速接口技术的主流。SERDES 是串行器)SERializer)和解串器)DESerializer)的简称, 其串行频率已从第一代的2.5G/3.125G 到现在发展到上10GHz。同时SERDES 设计已逐渐IP 化, 并作为IP 核嵌入到需要高速I/O 接口的大规模集成电路中。RocketIO 正是Xilinx 公司嵌入到Virtex- II Pro 系列FPGA 的SERDES。
本文就是把RocketIO 作为串行协议的物理层, 来实现板间的高速串行数据传输。文章首先对RocketIO 进行了简单的介绍, 然后提出采用该SERDES 设计协议的要点, 最后在Virtex-II Pro 系列FPGA 上实现了一个简单的串行通信协议并给出了仿真结果。
1 RocketIO 简介
RocketIO是集成在Virtex- II Pro 系列FPGA 中的灵活、功能可配置的千兆位级串行收发器。串行传输速度在600M/bps~
3.125G/bps,可选8B/10B 编解码, 可编程逗点检测, 这些特点使其可以理想的应用于需要高速串行传输的场合, 图1 为其结构框图:
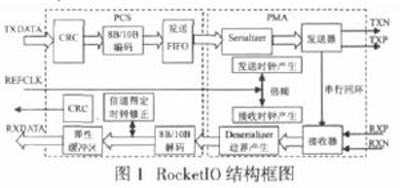
从上图看到, RocketIO 主要由PMA)Physical Media Attachment)和PCS)Physical Coding Sublayer)两部分组成, 其中PMA部分主要包括串行器和解串器、发送和接收缓冲区、高速时钟产生器和线路时钟恢复单元; PCS 部分主要包括8B/10B 编解码、弹性缓冲区)支持信道绑定和时钟修正)和CRC32 校验。
其工作原理是: 在发送端按照一定的算法产生的CRC 校验码被插入到欲发送的并行数据中)数据可以是8 位、16 位、32
位), 数据经过8B/10B 编码, 被写入发送端FIFO , 转换成串行差分数据发送出去。接收端接收到的串行差分信号被写入接收端缓冲, 经过串并转换变成并行数据, 再经过8B/10B 解码, 被写入弹性缓冲, 做CRC 检验后并行输出。这其中, 很多功能是可配置的, 如CRC 校验, 8B/10B 编解码等, 可以将它们加入到数据链路中, 也可以旁路掉。
2 简单协议的定制
下面我们利用RocketIO 的串行和解串功能定制一个简单的点对点通信协议, 实现两板间基于数据包的高速串行通信。假
设我们需要在两板间实现2Gb/s 的串行传输速度, 系统的输入输出数据为16 位, 不考虑两板间的时钟偏差, 若采用8B/10B 作为线路编码机制, 则系统工作频率在100MHz。针对这个需求,协议需要定义的内容有: 数据帧结构, 对齐和idle)空闲)字符。其实它们就是数据流中的控制信息, 我们称之为协议原语。本协议数据包的结构由帧头、数据帧、帧尾组成。由于协议是实现两板间点对点的简单通信, 数据帧并不复杂, 没有帧地址、校验码等其他数据域, 只是将外来数据添加了帧头和帧尾。
将数据封装成帧, 使得接收方能正确识别一次数据传输的开始和结束, 也便于对数据传输进行控制和差错检测, 同时便
于对协议功能进行扩展。我们借助于8B/10B 编码标准[4]中的K 字符来定义SF)帧开始)、EF)帧结束)、idle 字符等协议原语。如表1 所示)这些K 字符的选取完全是自定的。):

再来考虑数据帧的大小, 两板间是2Gb/s 的速率, 由于采用8B/10B 编码, 有效载荷速率为1.6Gb/s。这其中包含了数据帧、idle 字符和对齐字符, 而数据帧中又有帧头)2 字节)、帧尾)2 字节)的开销。当然这样看来, 数据帧越大, 开销就越小, 但是能插入相邻数据帧的时钟修正字符或对齐字符就越少, 因此, 这两者需要有个折衷。例如: 如果两板要求实现恒定的1.5Gbps 的数据流传输, 则本协议能承受的开销为6.25%, 则此时协议的数据帧至少为64 字节, 且需为偶数个字节)因为协议没有考虑填充功能)。由于本协议只是利用RocketIO 设计一简单的协议。帧的大小在本文没有严格要求, 在这里提出来只是为读者在实际设计时提供参考。
考虑了上面的事情, 我们就基本上完成了简单协议的定制了, 至于流控, 错误检测等等功能在此不做考虑。所以, 实际线
路的码流如图2 所示。

3 协议的实现
由于协议的大部分功能由物理层的RocketIO 来完成, 我们只需在其外围接口贴加一些自定义逻辑即可实现。本设计所有
逻辑代码均用Verilog 硬件语言描述, 实现该协议的结构框图如图3 所示:
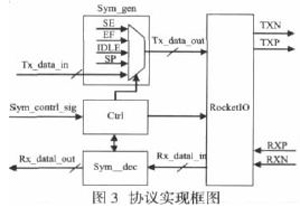
整个框架, 包括发送数据流产生模块Sym_gen,接收数据流解析模块Sym_dec, 对整个发送接收进行控制的Ctrl 模块和物
理层RocketIO。它们是这样协同工作的: 系统输入的16 位数据经Sym_gen 模块转换成协议定制的码流, 通过RocketIO 的并串转换由差分端口输出; 从差分端口输入的串行数据流经过RocketIO 的串并转换变成16 位数据, 经数据流解析模块
Sym_dec 去除码流中的idle 字符、帧头、帧尾、同步字符, 得到系统所需数据。
数据流产生模块实际上就是一个多路选择器, 它在不同的时间内选择将帧头)SF)、帧尾)EF)、idle 字符、同步字符分别输
出; 而这个时间上的控制就是由控制模块Ctrl 实现的, Ctrl 还肩负起复位, 启动RocketIO 并完成通道建立。下面来看该模块是怎样实现通道建立的, 图4 通过状态转移图的方式表明了通道的建立。
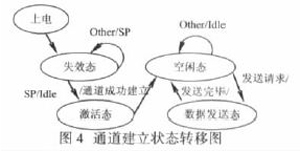
在系统上电的时候要确定链路是否已经工作, 这需要有个链路初始化过程。我们是通过利用收发双方交互系统定义的命
令来实现, 从图4 中看到: 失效态是系统上电或复位后的状态。处于该状态下的系统将不断发送同步字符命令, 用以向链路另一端表明自己的状态。在该状态下发端若接收到了同步字符, 则它将转入激活态, 在该状态下的发端将不断发送空闲字符, 同时发出信号表明通道已经建立, 并转入空闲态等待数据的发送, 当发完一帧数据时又会回到空闲态, 等待下一帧数据的发送。
4 设计仿真结果
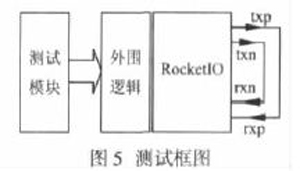
在Xilinx 公司集成开发环境ISE 下, 调用其中的Smartmodel模型, 用Modelsim 对整个协议进行仿真。仿真测试时将
RocketIO 的差分输入输出端口用大约0.5 米长的一对铜线对接, 形成自回环测试方式, 如图5 所示, 测试模块采用一个16
位数据宽的ROM, 通过该ROM来实现系统数据的输入。
将整个工程下载到FPGA 里)FPGA 采用Xilinx 公司Virtex-II Pro 系列XC2VP20- 6FF1152 型号, 其片内包括了8 个RocketIO, 系统时钟采用100MHz 晶振, 16 位数据经8B/10B 编码后, 其串行速率达到2Gbps.), 下载后, 用Xilinx 自带的逻辑分析工具chipscope 在线分析, 结果如图6 所示)为节省篇幅, 文中将发送端和接收端数据图拼接在一起, 图6 上部分为发送端,下部为接收端)。
从图中上部TX_DATA_OUT 看到在没有数据发送时通道被Idle 字符填充, 发送数据时, 数据添加了帧头)fdfd)、帧尾)
5c5c), 为了能显示整个数据帧, 发送时特意将数据长度缩短了。从图6 抓取的数据看到, 从发送端发出的数据0102, 0304,
0506, 0708, 090A, 0B0C, 0D0E, 1123 在打包后, 在接收端解包,最后实现了无误传输。

5 结论
在系统级互连中, 高速串行技术正成为业界趋势, 本文利用Xilinx 公司Virtex- II Pro 系列FPGA 中的SERDES 硬核——RocketIO 定制了一个在两板间实现简单高速通信的串行协议,通过上板调试实现了两板间2Gbps 串行数据的无误传输, 但是仅限于数据帧的简单传输, 没有完善的控制和检错机制。虽然如此, 但也让我们看到了RocketIO 在设计高速串行传输系统的优势, 我们可以很方便的用它来设计更复杂、更高速率的串行通信协议。
本文作者创新点: 将RocketIO 引入到高速串行通信中, 用它作为协议的物理层大大加快了串行协议设计进程。因此可以
把精力投入到协议链路层上, 来实现更多功能, 更复杂的串行通信协议。
转载:http://xilinx.eetrend.com/article/3488

 浙公网安备 33010602011771号
浙公网安备 33010602011771号