设计一个A表数据抽取到B表的抽取过程
原题如下:
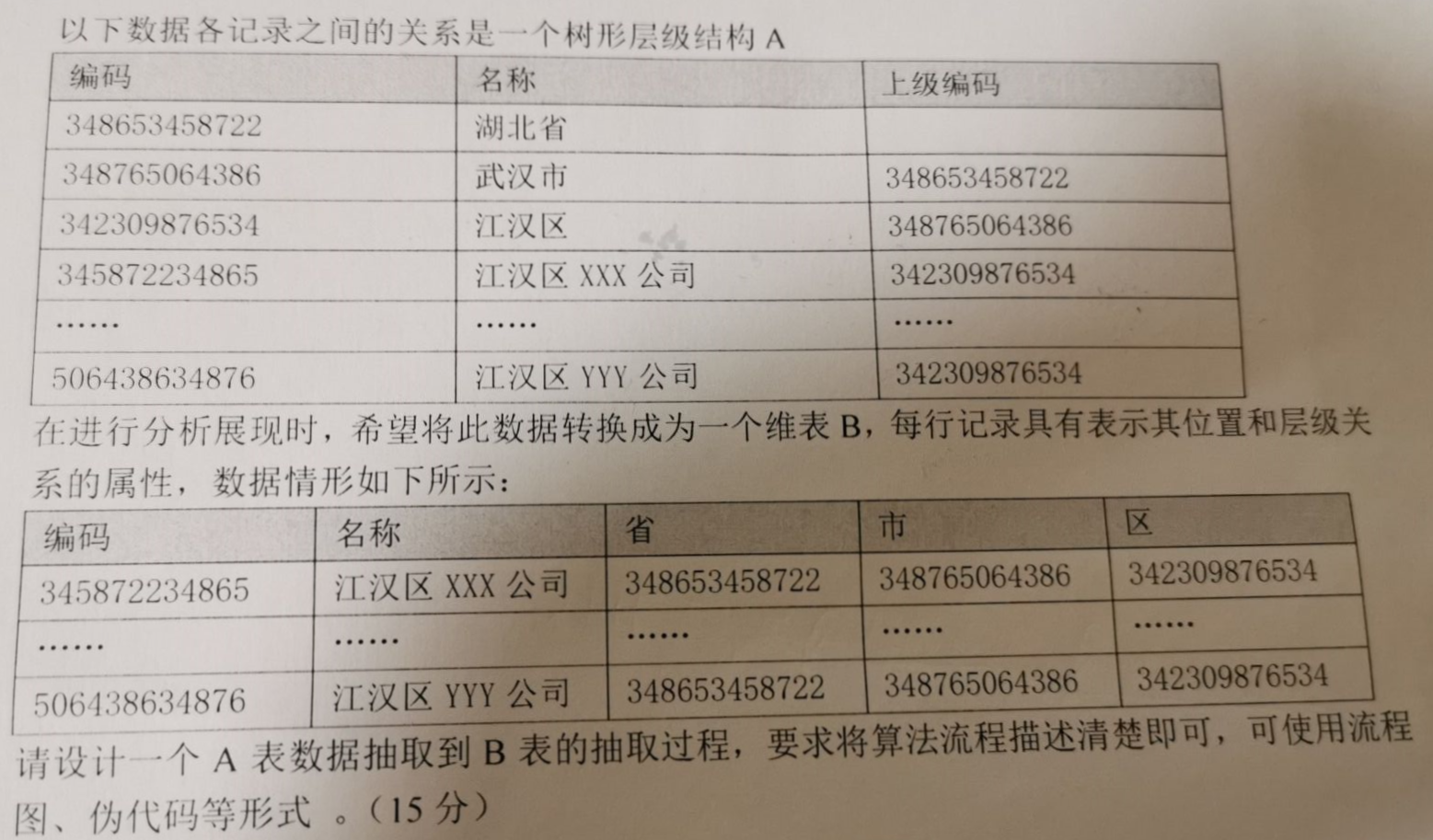
解题代码如下:
table1类:
1 @Data 2 @NoArgsConstructor 3 @AllArgsConstructor 4 public class table1{ 5 private String num; 6 private String name; 7 private String fatherNum; 8 }
table2类:
1 @Data 2 @NoArgsConstructor 3 @AllArgsConstructor 4 public class table2{ 5 private String num; 6 private String name; 7 private String sheng; 8 private String shi; 9 private String qu; 10 }
changeTable类:
1 @Data 2 @NoArgsConstructor 3 @AllArgsConstructor 4 class Node{ 5 //编号 6 private String num; 7 //名称 8 private String name; 9 //父节点 10 private Node fatherNum; 11 //子节点树 12 private List<Node> sonNum; 13 } 14 @Data 15 public class changeTable { 16 //零散节点,key为编号 17 private Map<String,Node> MapData = new HashMap<>(); 18 //结构同HashMap,list中存储的每个节点其形状都为树形,其中根为省节点 19 private List<Node> treeData = new ArrayList<>(); 20 //处理完后生成的新表 21 private List<table2> tab = new ArrayList<>(); 22 private void createTree(List<table1> datas) { 23 for(table1 data : datas) { 24 //为省列,直接添加到treeData中,形成树根 25 if(data.getFatherNum()==null) { 26 treeData.add(MapData.get(data.getNum())); 27 }else { 28 //当前节点中设置父亲点 29 MapData.get(data.getNum()).setFatherNum(MapData.get(data.getFatherNum())); 30 //父节点中设置孩子节点 31 List<Node> sonNum = MapData.get(data.getFatherNum()).getSonNum(); 32 sonNum.add(MapData.get(data.getNum())); 33 MapData.get(data.getFatherNum()).setSonNum(sonNum); 34 } 35 } 36 } 37 //生成零散节点,方便获取 38 private void createMap(List<table1> datas) { 39 for(table1 data:datas) { 40 MapData.put(data.getNum(), new Node(data.getNum(),data.getName(),new Node(),new ArrayList<Node>())); 41 } 42 } 43 //生成新表数据 44 private void createTable2() { 45 for(Node node : treeData) { 46 //node为树根,0为深度 47 createRow(node,0); 48 } 49 } 50 //使用深度优先遍历产生数据 51 private void createRow(Node node,int depth) { 52 //当能达到第三层(0层:省,1层:市,2层:区,3层:公司名),则新增数据 53 if(depth==3) { 54 table2 table2 = new table2(); 55 table2.setNum(node.getNum()); 56 table2.setName(node.getName()); 57 table2.setQu(node.getFatherNum().getNum()); 58 table2.setShi(node.getFatherNum().getFatherNum().getNum()); 59 table2.setSheng(node.getFatherNum().getFatherNum().getFatherNum().getNum()); 60 tab.add(table2); 61 }else { 62 //遍历当前节点子节点树 63 for(Node nod : node.getSonNum()) { 64 createRow(nod,depth+1); 65 } 66 } 67 } 68 public List<table2> getTable2(List<table1> dataList){ 69 createMap(dataList); 70 createTree(dataList); 71 createTable2(); 72 return tab; 73 } 74 }
Test类:
1 public class Test { 2 public static void main(String[] args) { 3 //模拟查询数据库 4 List<table1> dataList = new ArrayList<>(); 5 dataList.add(new table1("345872234865","江汉区XXX公司","342309876534")); 6 dataList.add(new table1("348724235332","长沙市","348653423233")); 7 dataList.add(new table1("348765064386","武汉市","348653458722")); 8 dataList.add(new table1("348652342344","岳麓区","348724235332")); 9 dataList.add(new table1("348653458722","湖北省",null)); 10 dataList.add(new table1("425232324523","岳麓区ZZZ公司","348652342344")); 11 dataList.add(new table1("348653423233","湖南省",null)); 12 dataList.add(new table1("342309876534","江汉区","348765064386")); 13 dataList.add(new table1("5065438634876","江汉区YYY公司","342309876534")); 14 //创建转换对象 15 changeTable changeTable = new changeTable(); 16 //得到转换结果 17 List<table2> table2s = changeTable.getTable2(dataList); 18 for(table2 tab :table2s ) { 19 System.out.println(tab); 20 } 21 } 22 }
算法解析:
注释已经解释的非常详细了,具体过程我就不再叙述了。
其中table1与table2是两个po对象,而@data注解相当于被注解类中所有成员加上了get、set方法,@NoArgsConstructor为无参构造方法,@AllArgsConstructor为全参构造方法。
运行结果:

注意:当数据非常多时,这种设计将不再适用,因为将所有数据加载到内存中会导致栈溢出。这时可以先将数据库中所有省列查询出来,(省列没有上级编号,这就是很好的查询条件);接着循环遍历省列,根据遍历的省查询出下面所有市;然后遍历查询出来的所有市得到市下面的所有区;然后遍历区下面的所有公司,最后组装数据。虽然性能远不如一次性导入数据,但针对于数据量大时是非常好的解决办法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号