哈希表(HashTable)
哈希表
哈希表:也叫做散列表。是根据关键字和值(Key-Value)直接进行访问的数据结构。也就是说,它通过关键字 key 和一个映射函数 Hash(key) 计算出对应的值 value,然后把键值对映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数(散列函数),用于存放记录的数组叫做 哈希表(散列表)。 哈希表的关键思想是使用哈希函数,将键 key 和值 value 映射到对应表的某个区块中。可以将算法思想分为两个部分:
- 向哈希表中插入一个关键字:哈希函数决定该关键字的对应值应该存放到表中的哪个区块,并将对应值存放到该区块中
- 在哈希表中搜索一个关键字:使用相同的哈希函数从哈希表中查找对应的区块,并在特定的区块搜索该关键字对应的值
哈希表的原理示例图如下所示:
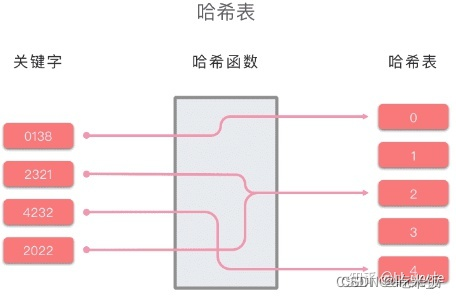
哈希函数
哈希函数:将哈希表中元素的关键键值映射为元素存储位置的函数。一般来说,哈希函数会满足以下几个条件:
- 哈希函数应该易于计算,并且尽量使计算出来的索引值均匀分布,这能减少哈希冲突
- 哈希函数计算得到的哈希值是一个固定长度的输出值
- 如果 Hash(key1) 不等于 Hash(key2),那么 key1、key2 一定不相等
- 如果 Hash(key1) 等于 Hash(key2),那么 key1、key2 可能相等,也可能不相等(会发生哈希碰撞)
在哈希表的实际应用中,关键字的类型除了数字类型,还有可能是字符串类型、浮点数类型、大整数类型,甚至还有可能是几种类型的组合。一般会将各种类型的关键字先转换为整数类型,再通过哈希函数,将其映射到哈希表中。 而关于整数类型的关键字,通常用到的哈希函数方法有:直接定址法、除留余数法、平方取中法、基数转换法、数字分析法、折叠法、随机数法、乘积法、点积法等。
哈希冲突处理
哈希冲突:不同的关键字通过同一个哈希函数可能得到同一哈希地址,即 key1 ≠ key2,而 Hash(key1) = Hash(key2),这种现象称为哈希冲突。
开放地址法
开放地址法:指的是将哈希表中的「空地址」向处理冲突开放。当哈希表未满时,处理冲突时需要尝试另外的单元,直到找到空的单元为止。H(i) = (Hash(key) + F(i)) \% m,i = 1, 2, 3, ..., n (n ≤ m - 1)
- H(i) 是在处理冲突中得到的地址序列。即在第 1 次冲突(i = 1)时经过处理得到一个新地址 H(1),如果在 H(1) 处仍然发生冲突(i = 2)时经过处理时得到另一个新地址 H(2) …… 如此下去,直到求得的 H(n) 不再发生冲突
- Hash(key) 是哈希函数,m 是哈希表表长,取余目的是为了使得到的下一个地址一定落在哈希表中
- F(i) 是冲突解决方法,取法可以有以下几种:
- 线性探测法:F(i) = 1, 2, 3, ..., m - 1
- 二次探测法:F(i) = 1^2, -1^2, 2^2, -2^2, ..., n^2(n ≤ m / 2)
- 伪随机数序列:F(i) = 伪随机数序列
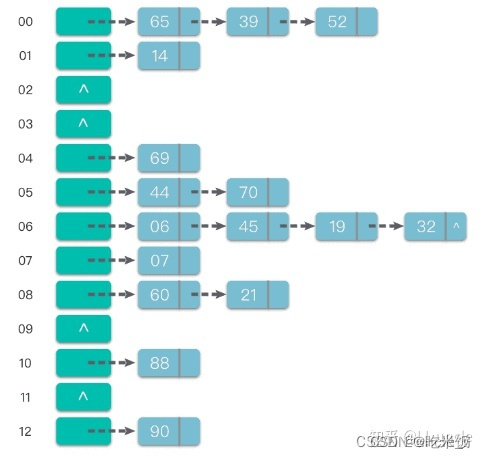
链地址法
链地址法:将具有相同哈希地址的元素(或记录)存储在同一个线性链表中。 链地址法是一种更加常用的哈希冲突解决方法。相比于开放地址法,链地址法更加简单。 假设哈希函数产生的哈希地址区间为 [0, m - 1],哈希表的表长为 m。则可以将哈希表定义为一个有 m 个头节点组成的链表指针数组 T。
-
这样在插入关键字的时候,只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将其以链表节点的形式插入到以 T[i] 为头节点的单链表中。在链表中插入位置可以在表头或表尾,也可以在中间。如果每次插入位置为表头,则插入操作的时间复杂度为 O(1)。
-
而在在查询关键字的时候,只需要通过哈希函数 Hash(key) 计算出对应的哈希地址 i,然后将对应位置上的链表整个扫描一遍,比较链表中每个链节点的键值与查询的键值是否一致。查询操作的时间复杂度跟链表的长度 k 成正比,也就是 O(k)。对于哈希地址比较均匀的哈希函数来说,理论上讲,k= n//m,其中 n 为关键字的个数,m 为哈希表的表长。
相对于开放地址法,采用链地址法处理冲突要多占用一些存储空间(主要是链节点占用空间)。但它可以减少在进行插入和查找具有相同哈希地址的关键字的操作过程中的平均查找长度。这是因为在链地址法中,待比较的关键字都是具有相同哈希地址的元素,而在开放地址法中,待比较的关键字不仅包含具有相同哈希地址的元素,而且还包含哈希地址不相同的元素。
Github Code
#pragma once
#include "RBTree.h"
template<typename Key, typename Value>
class HashTable {
private:
int M;
int size;
RBTree<Key, Value> *hashTable[];
int hash(Key key) {
return (hashCode(key) & 0x7fffffff) % M;
}
int hashCode(Key key) {
std::hash<Key> key_hash;
return key_hash(key);
}
public:
HashTable(int M) : M(M), size(0) {
*hashTable = new RBTree<Key, Value>[M]{};
for (int i = 0; i < M; ++i) {
hashTable[i] = new RBTree<Key, Value>();
}
}
HashTable() : M(97), size(0) {
*hashTable = new RBTree<Key, Value>[M]{};
for (int i = 0; i < M; ++i) {
hashTable[i] = new RBTree<Key, Value>();
}
}
int getSize() const {
return size;
}
void add(Key key, Value value) {
RBTree<Key, Value> *rbTree = hashTable[hash(key)];
if (rbTree->contains(key)) {
rbTree->set(key, value);
} else {
rbTree->add(key, value);
size++;
}
}
Value *remove(Key key) {
}
bool contains(Key key) {
return hashTable[hash(key)]->contains(key);
}
Value *get(Key key) {
return hashTable[hash(key)]->get(key);
}
void set(Key key, Value value) {
RBTree<Key, Value> *rbTree = hashTable[hash(key)];
if (!rbTree->contains(key)) {
throw key + "doesn't exist";
}
rbTree->set(key, value);
}
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号