
hadoop学习记录
一、Hadoop学习
Hadoop由hdfs和MapReducer组成,hadoop是主流的大数据基础架构
Hdfs是hadoop的一种分布式文件系统
MapReducer是hadoop的分布式计算方法
二、hadoop环境配置
配置jdk和hadoop
链接:https://blog.csdn.net/sujiangming/article/details/88047006
三、MapReducer工作原理
map task
程序根据inputformat将输入文件分为多个spilts,每个spilts作为一个map task的输入,map的进行处理,将结果传给reduce
reduce task
四、Java编程
Hadoop的java编程运行步骤:
1、编写Java程序
任务:分析电商平台日志,计算商品每个用户浏览次数,id为用户id
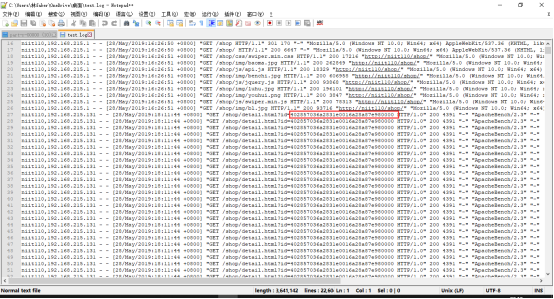
可以看出主要商品页面点击,只改变用户id,所以可以利用正则表达式截取文本,然后计算文本出现的次数。
编程实现:
导入jar包:hadoop-2.7.3是hadoop压缩包解压后的文件
hadoop-2.7.3\share\hadoop文件夹中的common 、hdfs、 mapreduce文件夹中的jar包和每个lib文件夹中的jar包导入
MyMaper类,实现map功能,将数据分散,然后传入MyReducer中;
import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将text数据类型转变为String类型 String formtValue=value.toString(); //用正则表达式截取指定字符间的文本 Pattern p = Pattern.compile("id=(.*?) HTTP"); Matcher m = p.matcher(formtValue); while (m.find()) { //将数据传给下个阶段 //m.group(1)文本不包含指定字符,若为m.group(0),则文本包含指定字符 context.write(new Text(m.group(1)),new IntWritable(1)); } } }
MyReducer类,实现Reducer功能,然后将数据结果传入下一阶段;
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override //key相同的使用同一个对象 protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int count=0;//每个单词出现次数 for(IntWritable value:values) { //mapper阶段的每个单词次数相加 count+=value.get(); } //将数据传入下一阶段 context.write(new Text(key), new IntWritable(count)); } }
MyJob类,主要是控制map和Reducer的输出格式和启动程序
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyJob { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1、创建程序入口及获取配置文件对象 Configuration configuration=new Configuration(); Job job=Job.getInstance(configuration); job.setJarByClass(MyJob.class); //2、指定Job的map的输出及输出类型 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //3、指定Job的reduce的输出及输出类型 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //4、指定Job的输入文件及输出结果的路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //5、执行程序 job.waitForCompletion(true); } }
2、打包成jar包
右键点击项目名,点击Export,然后选择JAR file格式,点击下一步,点击浏览,设置jar包保存位置及文件名,再点击下一步,再点击一次下一步,选择main calss ,就是MyJob类
3、Jar包上传至CentOS系统中
利用WinSCP上传至CentOS系统,https://winscp.net下载地址
4、将处理数据先上传至CentOS系统上,再上传至hdfs文件系统上。(centOS系统和hdfs文件系统)
处理数据上传方式同jar包上传一样;
上传至hdfs文件系统命令:
hdfs dfs -put 文件 上传目录
如:hdfs dfs -put mm.txt /input/
没有/input目录需创建
hdfs dfs -mkdir /input
5、运行jar文件
运行jar文件命令:
hadoop jar test.jar 测试数据 结果目录
如:hadoop jar test.jsr /input/mm.txt /result/mytestresult/
补充:
centOS相关指令:
mkdir 目录 创建文件夹
rm -rf 目录 删除文件夹及其文件
rm -f 文件路径 删除指定文件
Ifconfig 查看ip信息
hdfs dfs -put 文件(local) 上传目录(hdfs) 上传文件至hdfs
hdfs dfs -get 文件(hdfs) 下载目录(local)
hadoop jar test.jar 测试数据 结果目录 运行jar包
参考链接:https://www.cnblogs.com/riordon/p/4605022.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号