知识图谱-生物信息学-医学顶刊论文(Bioinformatics-2021)-MSTE: 基于多向语义关系的有效KGE用于多药副作用预测
MSTE: 基于多向语义关系的有效KGE用于多药副作用预测
论文标题: Effective knowledge graph embeddings based on multidirectional semantics relations for polypharmacy side effects prediction
论文期刊: Bioinformatics 2021
摘要
动机:多药联用是指多种药物联合使用治疗疾病。然而,它经常显示出很高的副作用风险。由于联合用药之间存在不必要的相互作用,多药联用的副作用会增加患病风险,甚至导致死亡。因此,获取丰富而全面的多药副作用信息是医疗保健行业的一项重要任务。
早期的传统方法使用机器学习技术来预测副作用。然而,为了提取药物的特征进行预测,他们往往付出昂贵的努力。随后,提出了几种基于KG的方法。据报道,它们的效果优于传统方法。然而,由于未能模拟药物之间副作用的复杂关系,它们仍然在性能上有很大局限性。
结果:为了解决上述问题,我们提出了一种新的模型,将复杂的副作用关系进一步融入到KGE中。我们的模型可以用更少的参数转换和传输多向语义,在大规模KG中具有更好的可扩展性。实验评价表明,我们的模型在ROC曲线下的平均面积和precision–recall曲线方面优于最先进的模型。
MSTE模型和神经网络等方法基本一致,都是学习已有药物网络的结构和药物之间的联系等来进行类比判断新药物组合,区别在于本模型提前把所有药物实体和副作用关系用sin重新进行了表示,得到\(s_{\bot},p_{\bot},o_{\bot}\),然后计算得分函数、损失函数并求梯度下降。
1.引言
“药物-药物”相互作用(DDI) 是指药物成分之间的药理作用,可能改变药物功能,导致药物不良反应(ADR) 和医疗事故。据报道,在美国,ADR每年造成约10万人死亡和4000次急诊室就诊。因此,预测潜在的DDI对于避免多重用药的负面副作用是很重要的。药理学分析可以识别有意(靶向)和非有意(非靶向)DDI。一般来说,在上市前的临床试验中可以发现不良反应;而只有在使用药物时才会发现一些严重的不良反应。然而,药物不良反应实验需要大量的人力和财力,要实现真正的临床试验是极其困难的。
为了解决这一问题,有人提出了自动分析方法。
传统的机器学习方法往往需要药物的众多特征。然而,很难从临床和实验室数据中提取这些特征。
为了克服这一缺陷,有人提出了一些KG方法。比如Decagon采用图模型,图模型的节点和边分别代表药物和ADR,因此,副作用预测问题可以表述为KG的链接预测问题。
其他方法通过整合多药副作用的语义来生成药物嵌入。其中,基于GCN和图注意网络具有最先进的性能。
尽管取得了一定的进步,但目前的方法仍然存在性能有限的问题。首先,他们未能对多药联用副作用的复杂关系进行建模。在图1中,知识图谱中有几个正确的三元组:①(drug1,ADR,drug2),②(drug1,ADR,drug3) 和 ③(drug2,ADR,drug4)。现有的方法将直接将ADR的语义传递给drug1、drug2、drug3 和 drug4。这可能会导致模型错误推断出 (drug3,ADR,drug4) (因为1和2、1和3都有ADR,所以2≈3,2和4有ADR,所以模型错误推断出3和4也有ADR)。这是因为得分函数通常被设计为学习药物的低维嵌入,而不考虑复杂的关系。然而,多药联用副作用的知识图谱具有大量的多对多关系。例如,TWOSIDES是一个广泛使用的数据集,其中每个DDI至少有900个相关药物组合。第二,现有的模型很少考虑语义从实体到关系的传递。通过关系学习的低维嵌入不能从药物中获取足够的信息,导致预测出药物之间不存在的多药联用副作用。
简单来说,之前的方法都只考虑语义从关系到实体,不考虑实体到关系的语义传递,因此不能表示药物之间的复杂关系。
为了解决上述问题,我们提出了一种新的模型,称为多向语义传输嵌入(MSTE)。我们将药物对及其副作用建模为知识图,其中节点和边分别表示药物和药物之间的副作用。副作用被定义为三元组\((s,p,o)\)。\(s\)和\(o\)代表三元组中无序的两种药物。\(p\)代表同时使用两种药物引起的副作用。该模型使用一个非线性函数\(f(s,p)\)来传递\(s\)的药物语义和\(p\)的语义和对药物\(o\)的副作用,由于两个节点的位置无序,药物\(o\)的语义和\(p\)的副作用可以通过一个非线性函数\(f(o,p)\)传递给药物\(s\),双重的药物语义可以通过\(f(s,o)\)传递到\(p\)的副作用。因此,我们的模型进一步考虑了从实体到关系以及图中实体之间的语义信息。与其他只考虑从关系到实体的语义信息的模型相比,我们所学习的嵌入向量能够更好地捕捉知识图中药物之间的语义信息。这就是为什么其他模型有类似于图1的不正确推论,但我们的模型可以很好地避免它们。此外,在表1中,与现有模型相比,我们的模型具有更少的参数,从而在大规模知识图中具有更好的可扩展性。综上所述,我们的主要贡献如下:
简单来说,我们的方法考虑了实体(即药物)\(s\)或\(o\)到关系(即副作用)\(p\)的语义传递,因此能表示药物之间的复杂关系。
- 我们提出了一种新的模型MSTE,该模型考虑了药物与副作用之间的相互语义信息,能够有效地模拟药物副作用之间的复杂关系。
- 与现有模型相比,该模型参数少,在大规模知识图中表现出更好的可扩展性。
- 与基线相比,我们的模型提高了多药副作用的预测性能,并在TWOSIDES和DrugBank两个基准数据集上取得了最好的结果。
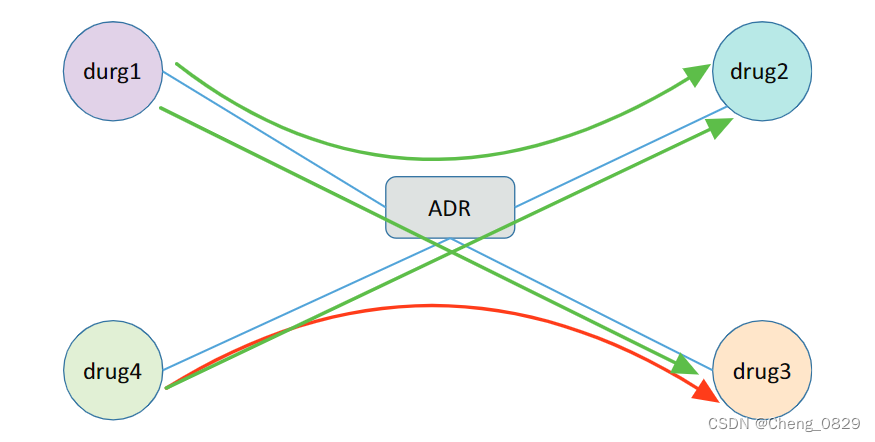
图1. 预测副作用的示例:绿色箭头表示已知正确的三元组,红色箭头表示不正确的推断
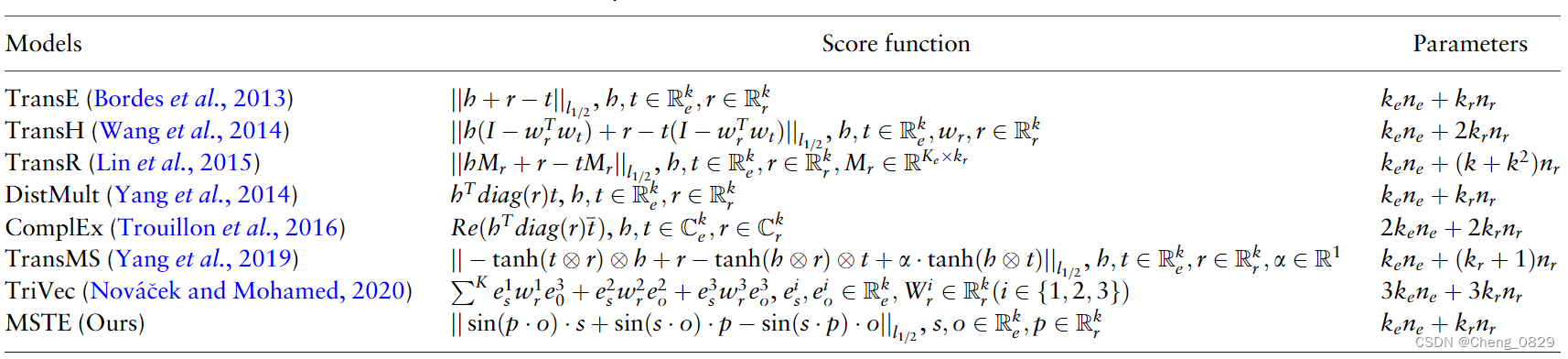
表1:模型评分函数及其参数个数。
注: 我们比较了各模型的得分函数及其参数个数。\(n_e\)和\(n_r\)分别表示KG中的实体和关系的数量。\(\mathbb{R}\)表示实数字段,\(\mathbb{C}\)表示复数字段。\(k_e\)和\(k_r\)表示实体和关系的嵌入大小,\(\alpha\)表示TransMS中每个关系向量的一个附加维度。对于TransE、DistMult、ComplEx、TransMS、TriVec和我们的模型,\(k_e=k_r\)。
2.相关工作
2.1 KGE
KG是以\((s,p,o)\)形式存储事实的结构化知识库,其中\(s\)和\(o\)表示实体,\(p\)表示实体之间的关系。
通过将KG三元组中的实体建模为节点,将关系建模为边,形成了一种能够有效表示实体之间关系的图结构。它在各个行业都具有重要的意义。KG用于下游任务,如推荐系统、信息提取、药物相互作用预测等,并取得了一定的进展。
KGE是指将KG中的实体和关系嵌入到一个低维的向量空间中,通过一个评分函数学习嵌入向量的每一维的值。在KGE模型中,根据不同的任务定制评分函数,真三元组得分高,假三元组得分低。该模型使用评分函数的结果来推断三元组是否为真。一般来说,我们可以将KGE模型大致分为三类:基于平移的模型、双线性模型和基于神经网络的模型。
2.2.1 基于平移的模型
基于平移的模型使含义相似的单词具有相似的表示。
其中最具代表性的是TransE,它通过关系将语义从头实体平移到尾实体。它可以正式地表达为\(s+p≈o\),且得分函数为\(S_p(s,o)=||s+p-o||_{l1/l2}\)。其他基于平移的模型如TransH、TransR和TransMS,都是为了弥补TransE在处理复杂关系(即1-N、N-1和N-N)方面的不足。这些模型使用基于距离的评分函数。此外,RotatE将实体和关系投影到复向量空间,以有效地对几种关系模式进行建模:对称/反对称、反转和合成。
2.2.2 双线性模型
双线性模型是用于KGE的另一种有效模型。基于乘积的得分函数可以匹配实体的潜在语义和向量空间表示中包含的关系。这些模型中最具代表性的是RESCAL,它将三元组投影到3维二元张量中,并将得分函数定义为\(S_p(s,o)=s^TM_po\)。这样,模型才能很好地表达其内在结构。由于RESCAL的计算复杂性,DisMult假设\(M_p\)是一个对角矩阵,因此它的得分函数可以定义为\(S_p(s,o)=s^Tdiag(p)o\)。此外,其他一些双线性模型包括ComplEx和ANALOGY。
2.2.3 神经网络
基于神经网络的模型已被广泛用于知识图的嵌入,并取得了很好的效果。他们使用神经网络模型来学习实体和关系之间的交互。例如,ConvE和ConvKB使用CNN模型来定义得分函数。
2.2 现有DDI预测方法
多药联用药物副作用预测是药理学中的一个重要研究课题,对联合用药、降低药物开发成本具有重要的现实意义。传统的多药副作用预测研究依赖于对预期药物诱导效应的药理学分析。用这种方法分析的药物对是有限的,它们受到实验室的限制。此外,许多潜在的严重副作用很难探测到。最近,研究人员专注于开发计算方法来预测药物组合之间可能的相互作用。我们将这些方法分为三类:基于相似度的方法、基于传统机器学习的方法和基于神经网络或KGE的方法。
2.2.1 基于相似度的方法
基于相似度的方法是早期的多药联用副作用预测方法。受基于内容的推荐系统的启发,一些方法使用基于相似性的思想,将要预测的药物对与当前已知的相互作用药物对的相似性进行比较。由于对象是多药联用的副作用,因此相似性函数也被扩展到比较两对药物(一对预测药物和一对已知的相互作用药物)。这些方法有助于更好地了解联合用药的副作用,但也有一定的局限性。它们需要大量详细的药物信息作为模型输入,如药物靶点、药物副作用等,而这些信息通常无法获得。
2.2.2 机器学习方法
传统的基于机器学习的方法使用不同的机器学习分类器来解决ADRs的预测问题。有人提出了一种结合药物显性特征的基于机器学习的ADRs预测方法,并对Logistic回归、K-均值、朴素贝叶斯、随机森林和支持向量机等算法进行了比较。有人使用两种机器学习方法:决策树和归纳逻辑编程,在综合药物和目标描述符的基础上探索了频繁的副作用概况。FS-MLKNN是一种基于特征选择的多标签k近邻方法,把副作用预测当作了一个多标签学习任务。
2.2.3 基于神经网络或KGE的方法
基于神经网络或知识图嵌入的方法是近年来比较流行的方法。Node2vec模型学习药物在网络中的嵌入,并使用一个线性层来预测关系。KGNN模型是一个端到端的KG神经网络框架,它可以有效地捕捉药物及其潜在邻域,并通过挖掘它们在KG中的关联关系来自动从数据中提取药物特征,而不需要了解药物的化学结构和特殊的药物表达。Decagon使用GCN将副作用预测转化为链接预测问题并进行求解。GraIL模型使用局部子图来归纳知识图上的关系。Conv-LSTM模型利用ComplEx模型学习嵌入向量,然后利用卷积-LSTM网络和经典机器学习预测方法对药物对相互作用进行预测,取得了较好的效果。此外,CNN被用来预测药物对中DDIs的类型和概率。DeepDDI开发了一个计算框架,通过使用药物的名称和结构作为输入,准确预测药物对和“药物-食品”成分对之间的相互作用,并使用具有优化预测性能的深度神经网络。SkipGNN使用两个GNN来聚合信息以预测DDIs。TriVec模型是一种新的KGE方法,它使用嵌入向量来预测多药副作用。他们将多药不良反应数据建模为KG,然后使用基于张量分解的方法执行链接预测任务。最近,GFAN是一个图特征注意网络,通过强调不同的靶基因来解释多药副作用的预测,主要是为了解决预测的可解释性问题。有人提出了一个模型,通过增加一个新的关系图注意力网络,为多层图中的不同关系分配不同的权重,来提高GCN在链接预测任务中的性能。他们都在公开的多药副作用网络上实现了最先进的性能。
综上所述,我们可以知道,传统的实验方法需要大量的人力和财力。基于相似性的方法、传统的基于机器学习的方法和神经网络方法都需要大量的详细药物信息作为模型输入。例如,目前最先进的模型GFAN使用了DDI网络结构信息和靶基因信息。有人融合了包含目标蛋白质信息的异质网络信息。因此,这类模型需要使用DDI网络以外的信息,这在一定程度上限制了模型的使用。此外,常见的KG方法通常忽略了数据集中的复杂关系,很少考虑将语义信息从实体传递到关系。这可能会导致关系学习的低维嵌入不能从药物中获得足够的信息,从而影响实验的准确性。
为了解决这些问题,我们提出了一个新的模型MSTE来预测多药联用的副作用。我们的模型仅使用DDI网络信息,而且考虑了多药联用副作用KG的特殊性。针对知识图谱中复杂的副作用关系。它考虑了将语义从实体传递到关系,以转换关系的嵌入,使副作用的低维向量能够很好地捕捉药物对的语义。
3.材料与方法
3.1 预备知识
我们可以将多药联用的副作用数据表示为知识图,两种药物代表三元组中的实体,药物之间的副作用代表三元组之间的关系。多药联用的副作用预测任务可以描述为给定两种药物,预测它们之间的副作用。这样,我们就可以将该任务转化为知识图的关系预测任务,即链接预测任务。在KG中,缺少有效的三元组是一个常见的问题。手动查找所有的有效三元组是不切实际的。因此,通过已知链接来预测实体之间未知的可能关系是非常重要的。这项任务的挑战在于,我们不仅需要预测两种药物之间是否有副作用,还需要预测两种药物之间的副作用是什么。因此,我们可以很容易地将多药不良反应预测任务转化为知识图的链接预测任务。
我们在图2中解释了转换后的多药联用副作用预测任务。当预测多药联用副作用时,我们需要使用与这些药物和副作用相关的其他已知三元组来学习药物和副作用的嵌入向量。然后将学习到的向量组合成新的多药副反应三元组,然后通过评分函数对其进行评分。根据得分,得到组合的三元组为真的概率。得分越高,三元组为真的可能性就越高,这意味着当同时服用药物时,发生此类副作用的可能性就越大。至于预测阈值,我们遵循最近的一项工作,该工作考虑了训练集的正负比,并使用动态方法生成阈值。我们对最终的预测分数从大到小进行排序,由于训练集中样本的正负比为1:1,因此在排序的分数中选择中位数作为阈值。也就是说,我们预测得分上半部分为真的三元组。类似的做法在KGE领域也非常常见。因此,我们使用这种方法来解决多药联用的副作用预测问题。在图2中,每对药物之间存在多个副作用关系,虚线表示我们需要预测的关系。因此,多药副反应的预测问题可以被当作知识图中的链接预测问题来解决。在已有的工作中,KGE方法具有最先进的性能。
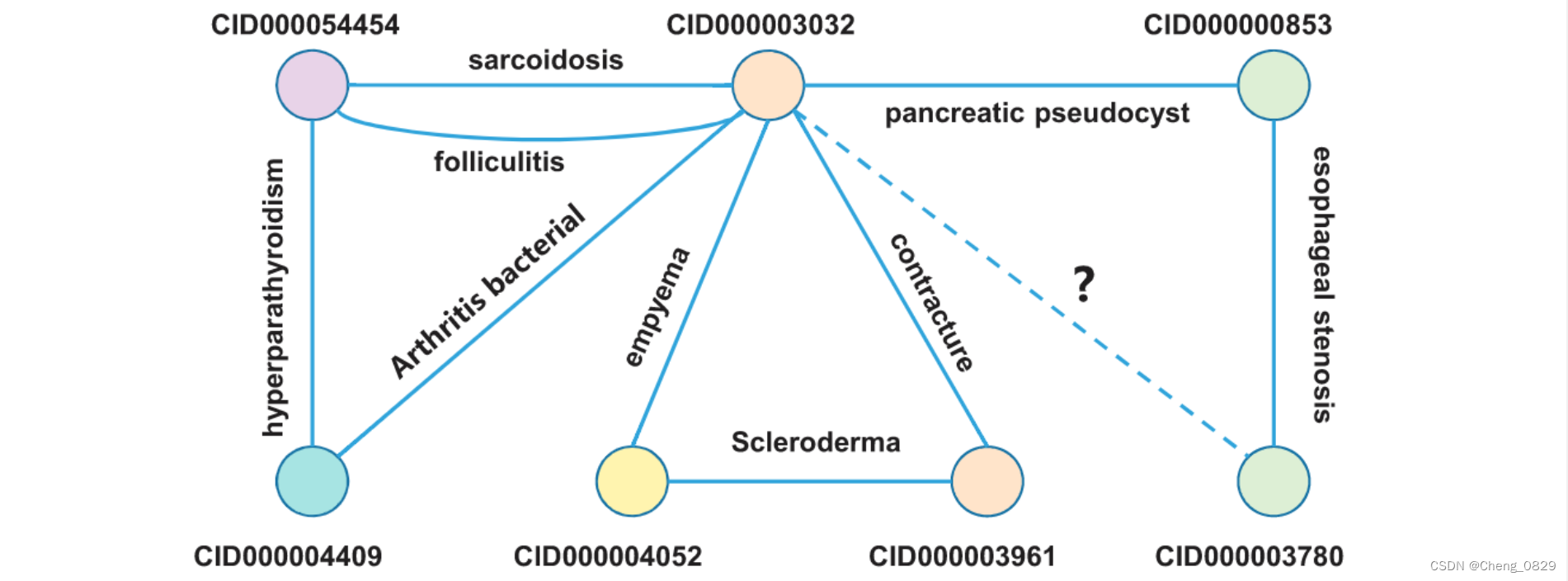
图2:部分知识图谱展示。节点代表药物,边代表副作用。实线代表已知链接(图中只画了一小部分),虚线代表需要预测的链接
3.2 需要解决的问题
通过将多药副作用数据建模为知识图,数据可以以三元组格式存储,如\((drug_i,side_{effect},drug_j)\),其中\(drug_i\)和\(drug_j\)的位置是无序的。为了体现这一特点并节省存储空间,我们将药物不良反应数据中的药物顺序按照药物编码的顺序进行排序。也就是说,\(drug_i\)的编码位于\(drug_j\)的编码之前(我们假设\(i<j\))。对于多药联用副作用的每一个三元组,不仅有从药物到副作用的语义信息,而且还有药物对之间的语义信息。大多数以前的方法忽略了多药联用副作用数据中复杂的多对多关系,导致预测结果较差。因此,我们提出了一个新的模型来解决这一问题。我们的模型使用一个非线性函数把\(drug_i\)(\(drug_j\))的语义和\(side_{effect}\)传递给\(drug_j\)(\(drug_i\)),并将\(drug_i\)和\(drug_i\)的语义信息传递给\(side_{effect}\)。信息传递的过程体现在将这些语义信息转化为权重。在这些权重的约束下,嵌入向量可以反映不同维度上三元组的不同组合的不同重要性,能够有效地处理KG中存在的多向语义关系。
3.3 MSTE模型
如上所述,我们提出了一种基于KGE的MSTE模型。其目标是对KG中实体和关系之间的交互进行建模,并传递实体和关系之间的多向语义。我们通过评分函数对数据集中的样本进行评分,学习实体和关系的特征向量,用于ADRs预测。图3说明了我们模型的预测流程。
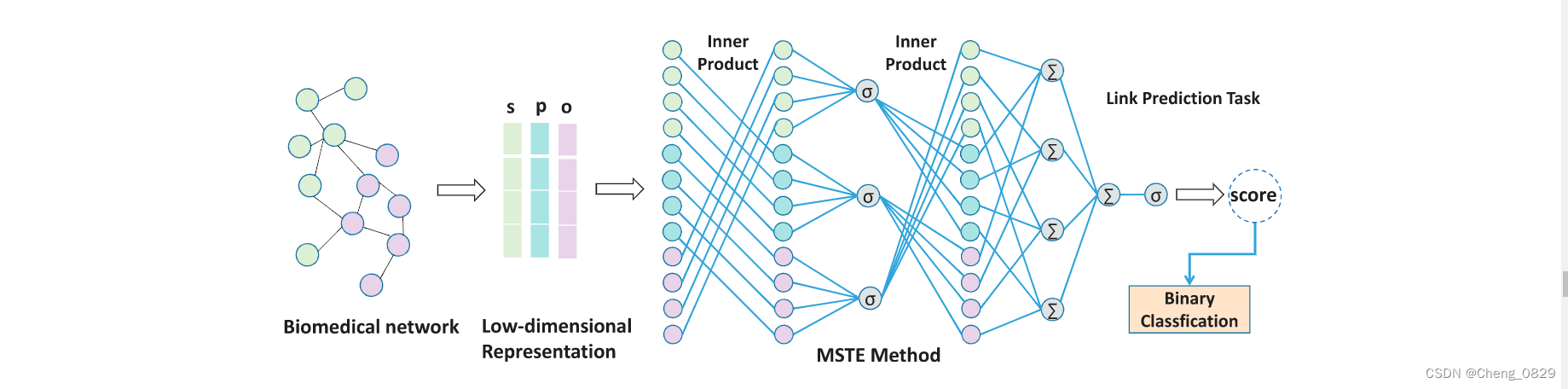
图3. 模型的预测流程。
1.多药副作用网络以三元组格式存储结构化数据,并将其建模为知识图谱。
2.在初始化实体和关系的嵌入后,使用本文提出的MSTE来学习图中药物和副作用的低维嵌入,将多药副作用预测任务转化为KG链接预测。
3.在训练过程中不断更新药物和副作用的嵌入,最终有效学习DDI网络的结构信息,挖掘药物和副作用的潜在语义特征,有效完成预测任务。图的第一部分的边代表副作用,第二部分是实体和关系的低维嵌入,在图中展示了4维,在实验中有200维。第三部分是我们模型的网络结构示意图。
首先,我们考虑了数据集的特征。由于多药不良反应数据集的规模庞大,在数据集如TWOSIDES中,每种DDI类型至少有900种药物组合,数据中存在大量的多对多关系。此时,对于KG中的关系向量,对于不同的药物组合,向量的每个特征应该根据不同的药物对具有不同的权重,这有助于区分药物对之间是否存在当前的副作用。相应地,我们从KG中多向语义复杂关系的特点入手。我们在学习实体和关系的低阶向量的过程中,传递药物对和副作用之间的语义信息。因此,学习后的低阶向量可以更好地处理多药联用药物副作用预测的任务。通过使用非线性函数\(f(drug_i,side_{effect})\),将\(drug_i\)和\(side_{effect}\)的语义传递给\(drug_j\)。因为节点具有相同的状态,所以我们可以通过非线性函数\(f(side_{effect},drug_j)\)将\(side_{effect}\)和\(drug_j\)的语义传递给\(drug_i\)。用\(f(drug_i,drug_j)\)作为副作用向量的权值,可以使\(side_{effect}\)的关系更好地了解双药联合的特点,从而提高预测的准确性。
MSTE模型用于处理多药联用ADRs数据中复杂副作用的预测问题。该模型首先将药物对\(drug_i、drug_j \in E^k\)和副作用的实体向量投影为\(side_{effect} \in R^k\),其中k代表嵌入维度,并通过非线性函数实现语义的相互传递。通过实验发现,大多数非线性函数具有相似的效应,它们的目的是将非线性引入到模型中。因此,我们在{ReLu,cos,tan,tanh,Softmax,sin}中选择了效果略好的sin。因此,使用语义信息作为权重后的药物和副作用向量可以表示为:
\( \bullet \space s_{\bot}=f(p\cdot o) \cdot s \\ \bullet \space p_{\bot}=f(s\cdot o) \cdot p \\ \bullet \space o_{\bot}=f(s\cdot p) \cdot o \)
其中,“·”表示Hadamard乘积;\(f\)表示非线性函数(我们使用sin作为这个非线性函数);我们的模型使用TransE作为得分函数。因此,模型的得分函数可以表示为:
这里,\(s\)和\(o\)分别表示\(drug_i\)和\(drug_j\);\(p\)表示副作用;由于多药联用副作用KG的特殊性,对\(drug_i\)和\(drug_j\)按照药品编码的顺序进行了分类。\(drug_i\)的代码位于\(drug_j\)的代码之前,因此三元组\((s,p,o)\)和\((o,p,s)\)不会同时出现在数据集中。处理后的数据集与传统的知识图统一,节省了不必要的存储空间,防止了数据泄露问题。KG中存在的三元组的得分应该高于不存在的三元组的得分。
3.4 模型训练
由于数据中不包含负样本,因此模型必须在训练过程中自动生成负样本。为了训练该模型,我们遵循了几种有效的生成负样本的方法。对于每个副作用,随机生成数据中不存在的药物对的组合。在准备好负样本之后,我们可以如下设计损失函数:
这里,\(S_p(s,o)\)表示三元组的分数;\(E\)表示正类样本;\(s\)和\(o\)表示药物实体,(s',p,o')是负类样本;\(\operatorname{mean}\)表示训练样本的平均损失;\(\sigma\)是激活函数,我们使用\(softplus\)函数;\(\gamma\)是固定边距。该模型通过不断优化损失函数来学习药物和副作用的嵌入向量,并将学习到的嵌入向量用于预测任务。
在初始化带有随机噪声的嵌入向量后,通过训练数据的迭代来更新它们。在每个epoch中,训练数据被分成小批,并在每一批上逐个进行学习。该模型通过最小化损失函数来学习关系和实体的嵌入。
结论
在本文中,我们提出了一种新的KGE方法,称为MSTE,用于预测多药联用的副作用。利用KG对ADRs数据进行建模,将ADRs预测问题转化为KG链接预测问题。该模型利用KGE,利用一个非线性函数传递药物对和副作用之间的语义,以提高预测性能。我们还进行了广泛的实验,以显示与最先进的模型相比,我们的性能更好。此外,与GFAN等模型相比,我们的模型只使用了DDI网络信息,而他们的模型需要靶基因信息等其他信息作为辅助信息输入到模型中。我们的模型比他们使用的图注意网络更简单,因此我们的模型更具可扩展性和可用性。未来,研究人员可以考虑使用更有效的负采样法来提高预测结果。此外,我们的模型现在没有考虑药物的元数据。这一领域的研究人员可考虑使用来自元数据的外部信息来进一步改进学习阶段。

