
Row_Number() over( PARTITION By cno ...)
转自:https://blog.csdn.net/qq_25237107/article/details/64442969
1.在 MSSQL,oracle 有partition by 的用法
create table score
(
sno varchar(20) ,
cno varchar(20),
degree int
)
insert into score (sno ,cno ,degree ) values ('001','a',100)
insert into score (sno ,cno ,degree ) values ('002','a',99)
insert into score (sno ,cno ,degree ) values ('003','a',98)
insert into score (sno ,cno ,degree ) values ('004','a',97)
insert into score (sno ,cno ,degree ) values ('001','b',100)
insert into score (sno ,cno ,degree ) values ('002','b',100)
insert into score (sno ,cno ,degree ) values ('003','b',99)
insert into score (sno ,cno ,degree ) values ('004','b',98)
insert into score (sno ,cno ,degree ) values ('001','c',100)
insert into score (sno ,cno ,degree ) values ('002','c',100)
insert into score (sno ,cno ,degree ) values ('003','c',99)
insert into score (sno ,cno ,degree ) values ('004','c',98)
select * from
(
select *,ROW_NUMBER () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3
select * from
(
select *,rank () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3
select * from
(
select *,dense_rank () over(PARTITION BY cno order by degree desc) as pm from score
) x
where x.pm <=3
2.在 mysql中 没有 ROW_NUMBER()over(partition by ... order by ...) 这种写法
需要用其他 替代方法:
方法一:
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`subject_id` char(10) DEFAULT NULL,
`student_id` char(10) DEFAULT NULL,
`score` float DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
INSERT INTO score
select NULL,'1','001',100
UNION
SELECT NULL,'1','002',90
UNION
SELECT null,'1','003',80
UNION
select null,'1','004',99
UNION
select null,'1','005',78
UNION
select null,'1','006',89
UNION
select NULL,'1','001',100
UNION
SELECT NULL,'1','002',90
UNION
SELECT null,'1','003',80
UNION
select null,'1','004',99
UNION
select null,'1','005',78
UNION
select null,'1','006',89
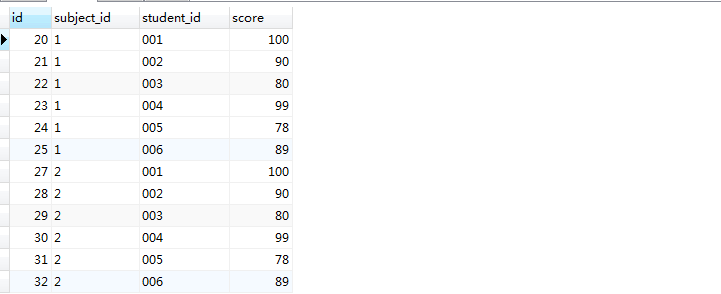
2.
相当于自身全连接:
SELECT AA.*,BB.* FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
ORDER BY AA.subject_id,AA.score DESC
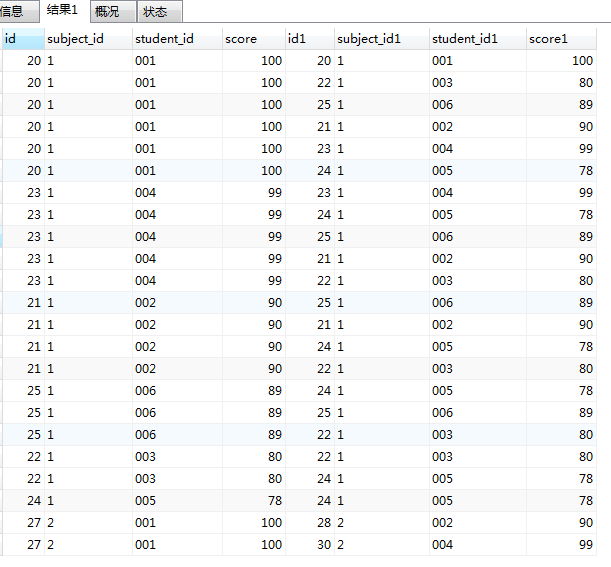
3. group by 之
SELECT AA.*,BB.* FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
GROUP BY AA.student_id,AA.subject_id,AA.score
ORDER BY AA.subject_id,AA.score DESC
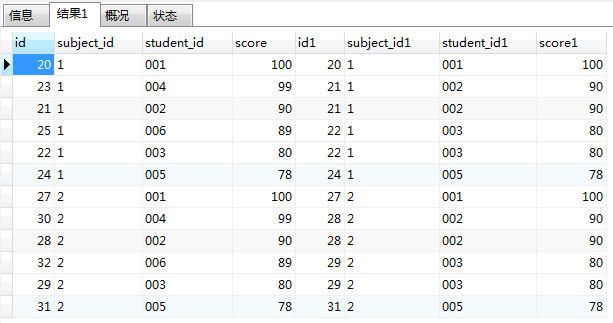
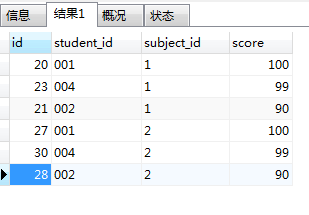
4.having 之
SELECT AA.id,AA.student_id,AA.subject_id,AA.score FROM score AA JOIN score BB
on AA.subject_id=BB.subject_id AND AA.score>=BB.score
GROUP BY AA.student_id,AA.subject_id,AA.score
HAVING count(AA.subject_id)>=4
ORDER BY AA.subject_id,AA.score DESC
注意: mysql 与 MSsql 之 group by 是不相同的
mysql 使用 group by 后 select 可以 全部字段. mssql 是不行的
方法二:
Mysql 分组聚合实现 over partition by 功能
转自:https://www.cnblogs.com/zhwbqd/p/4205821.html
https://blog.csdn.net/zzm628/article/details/52181382
mysql中没有类似oracle和postgreSQL的 OVER(PARTITION BY)功能. 那么如何在MYSQL中搞定分组聚合的查询呢
先说结论: 利用 group_concat + substr等函数处理
例如: 订单表一张, 只保留关键字段
| id | user_id | money | create_time |
| 1 | 1 | 50 | 1420520000 |
| 2 | 1 | 100 | 1420520010 |
| 3 | 2 | 100 | 1420520020 |
| 4 | 2 | 200 | 1420520030 |
业务: 查找每个用户的最近一笔消费金额
单纯使用group by user_id, 只能按user_id 将money进行聚合, 是无法将最近一单的金额筛选出来的, 只能满足这些需求, 例如: 每个用户的总消费金额 sum(money), 最大消费金额 max(money), 消费次数count(1) 等
但是我们有一个group_concat可以用, 思路如下:
1. 查找出符合条件的记录, 按user_id asc, create_time desc 排序;
select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by ord.user_id asc , ord.create_time desc
| user_id | money | create_time |
| 1 | 100 | 1420520010 |
| 1 | 50 | 1420520000 |
| 2 | 200 | 1420520030 |
| 2 | 100 | 1420520020 |
2. 将(1)中记录按user_id分组, group_concat(money);
select t.user_id, group_concat( t.money order by t.create_time desc ) moneys from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and ord.create_time > 0 order by ord.user_id asc , ord.create_time desc) t group by t.user_id
| user_id | moneys |
| 1 | 100,50 |
| 2 | 200,100 |
3. 这时, 如果用户有多个消费记录, 就会按照时间顺序排列好, 再利用 subString_index 函数进行切分即可
完整SQL, 注意group_concat的内排序, 否则顺序不保证, 拿到的就不一定是第一个了
select t.user_id, substring_index(group_concat( t.money order by t.create_time desc ),',',1) lastest_money from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by user_id asc , create_time desc) t group by user_id ;
| user_id | moneys |
| 1 | 100 |
| 2 | 200 |
利用这个方案, 以下类似业务需求都可以这么做, 如:
1. 查找每个用户过去10个的登陆IP
2. 查找每个班级中总分最高的两个人
补充: 如果是只找出一行记录, 则可以直接只用聚合函数来进行
select t.user_id, t.money from (select ord.user_id, ord.money, ord.create_time from orders ord where ord.user_id > 0 and create_time > 0 order by user_id asc , create_time desc) t group by user_id ;
前提一定是(1) 只需要一行数据, (2) 子查询中已排好序, (3) mysql关闭 strict-mode
参考资料:
http://dev.mysql.com/doc/refman/5.0/en/sql-mode.html#sql-mode-strict
http://dev.mysql.com/doc/refman/5.0/en/group-by-functions.html#function_group-concat
有任何问题请不吝赐教, 谢谢!
posted on 2018-07-04 10:06 chengjunde 阅读(435) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号