ELK知识点及问题记录
1. 操作
1.1. 线程池配置
thread_pool:
write:
size: 30
queue_size: 1000
1.2. es恢复参数优化
PUT /_cluster/settings
{
"persistent" : {
"cluster" : {
"routing" : {
"allocation" : {
"cluster_concurrent_rebalance" : "6",
"node_concurrent_recoveries" : "8"
}
}
},
"indices" : {
"recovery" : {
"max_bytes_per_sec" : "500mb"
}
}
}
2. 问题记录
2.1. filebeat往logstash传输数据报错
报错信息:
filebeat:
2021-11-19T10:50:43.056+0800 ERROR pipeline/output.go:121 Failed to publish events: write tcp 192.168.11.178:53849->192.168.31.180:5046: write: connection reset by peer
2021-11-19T10:50:43.095+0800 ERROR pipeline/output.go:121 Failed to publish events: write tcp 192.168.11.178:43347->192.168.31.180:5047: write: connection reset by peer
logstash:
[2021-11-19T11:22:18,817][WARN ][logstash.filters.grok ][log02] Timeout executing grok '%{IPORHOST:clientip} (%{IPORHOST:ip}|-) (%{DATA:remoteUser}|-) \[%{HTTPDATE:httpDate}\] \"%{WORD:method} %{DATA:request} %{NOTSPACE:httpVersion}\" %{NUMBER:statusCode} (?:%{NUMBER:bodyBytesSent}|-) \"(?:%{DATA:httpReferrer}|-)\" %{QS:agent} \"(%{XFORWARDEDFOR:xforwardedfor}|-)\" (%{BASE16FLOAT:requestTime}|-) (%{UPSTREAMADDR:upstreamAddr}|-) (%{HOSTORPORT:serverHost}|-) (%{UPSTREAMTIMES:upstreamResponseTime}|-)' against field 'message' with value 'Value too large to output (566 bytes)! First 255 chars are: 168.158.194.146 10.181.2.116 - [19/Nov/2021:00:06:24 +0800] "GET /index.html HTTP/1.1" 200 76163 "-" "colly - https://github.com/gocolly/colly/v2" "192.168.31.199'!
问题原因
logstash的grok正则和实际的内容不匹配,导致logstash hang住,不再接受filebeat过来的请求;另外grok正则的效率hui影响filebeat传输的速率
2.2. index read-only
报错信息:
[2021-07-19T15:48:04,802][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
[2021-07-19T15:48:04,802][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
[2021-07-19T15:48:04,802][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
[2021-07-19T15:48:04,802][INFO ][logstash.outputs.elasticsearch] Retrying individual bulk actions that failed or were rejected by the previous bulk request. {:count=>1225}
问题原因:
内存不足;磁盘不足
解决方式:
curl -XPUT IP:9200/_all/_settings -H 'Content-Type: application/json' -d '
{
"index" : {
"blocks" : {
"read_only_allow_delete" : "false"
}
}
}'
2.3 failed to parse field [host] of type [text]
filebeat 将一个 [host] 对象添加到事件中,该对象包含名为 [host][name] 的字段,该字段包含主机的名称。其他一些输入将 [host] 字段添加到事件中,该字段包含主机的名称。
在 elasticsearch 中,字段在某些文档中不能是对象,而在其他文档上不能是字符串。你必须选择一个或另一个。如果您选择字符串并尝试添加[host]是对象的文档,那么您会收到您看到的确切错误消息。
{"type"=>"illegal_argument_exception", "reason"=>"mapper [host] of different type, current_type [keyword], merged_type [ObjectMapper]"}
在索引中,字段类型是"keyword"(即字符串),但您正在尝试插入文档,它将是一个对象。
您需要决定是要让 [host] 成为对象还是字符串。如果您希望它是一个对象,并且您的输入生成一个字符串(例如,syslog输入),那么
if ! [host][name] { mutate { rename => { "[host]" => "[host][name]" } } }
可能是一个解决方案。如果您希望它是一个字符串,并且您的输入产生一个对象(例如,节拍输入),那么
mutate { replace => { "[host]" => "[host][name]" } }
可能是一个解决方案。请注意,这是替换,而不是重命名,因此参数顺序的含义是相反的。
如果你的输入生成了一个对象,并且你希望它是一个对象,那么只需滚动到一个新索引可能是一个解决方案。
2.4 grok ruby正则失败,但时候看不到完整日志
为题:在使用logstash做日志字段正在分割的时候,我们经常会遇到下面的情况,导致我们的logstash性能下降:
发现有日志匹配失败,但是日志里面又不能把完整的日志打印出来,对于大流量环境我们很难定位到我们需要的这个日志,来重新兼容我们的正则表达式

解决:
这里的日志截断是在 vendor/bundle/jruby/2.5.0/gems/logstash-filter-grok-4.2.0/lib/logstash/filters/grok.rb 这个文件中写死的,不同版本路径会有区别,可通过下面的找到这个文件
]# grep ' First 255 chars' * -r
vendor/bundle/jruby/2.5.0/gems/logstash-filter-grok-4.2.0/lib/logstash/filters/grok.rb: "Value too large to output (#{value.bytesize} bytes)! First 255 chars are: #{value[0..255]}"
可以看到文件里对value进行了截断,我们只需要把这部分内容修改下
# old
"Value too large to output (#{value.bytesize} bytes)! First 255 chars are: #{value[0..255]}
# new
"Value too large to output (#{value.bytesize} bytes)! First 255 chars are: #{value}
2.5 kibana不能监控ES
问题kibana不能监控ES,进入不到monitoring页面
并且ES报如下错误:
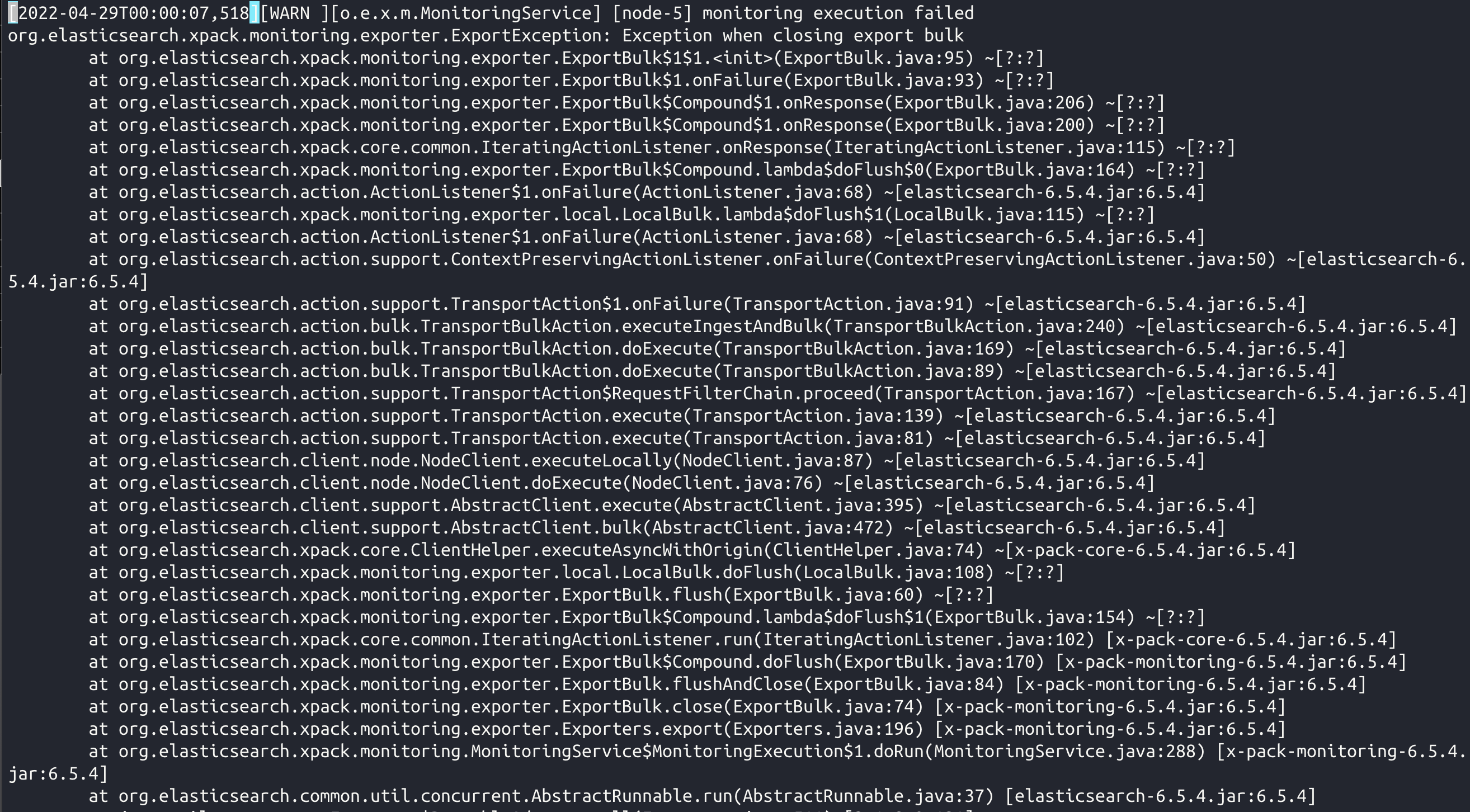
经过排查kibana日志发现有如下报错
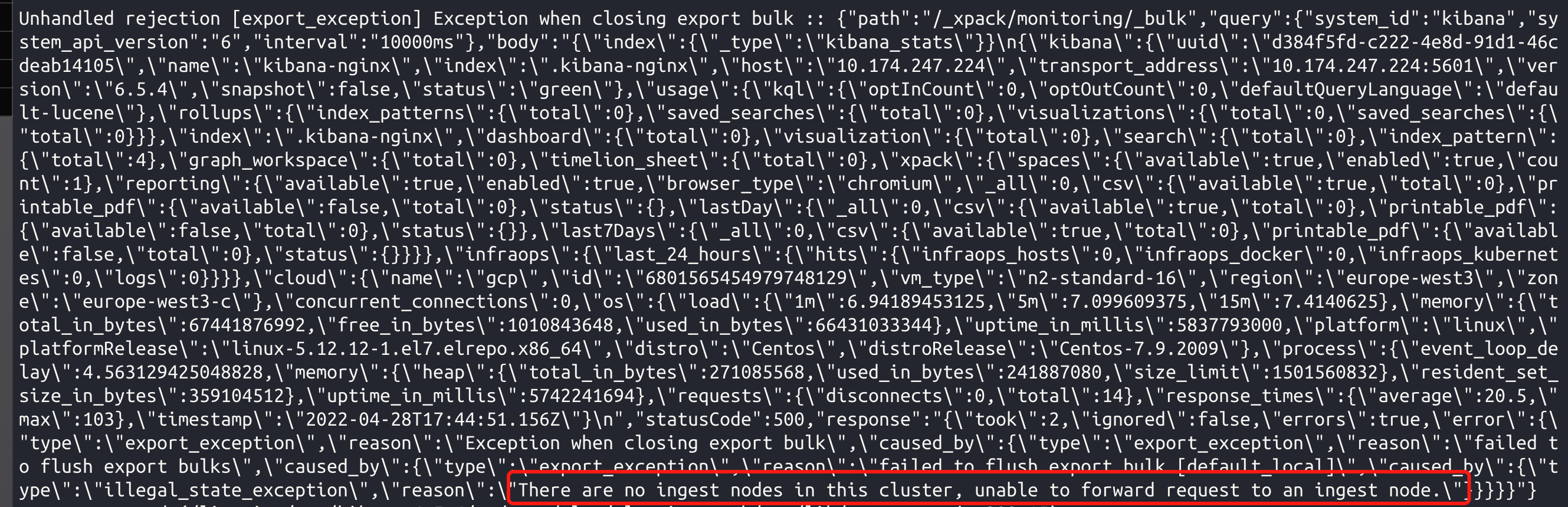
查看内容应该是没有ingest节点
加入ingest节点后正常
这样就可以打印完整的日志,方便我们对有问题的内容进行兼容啦!
3. 知识点
3.1. 写数据的底层原理
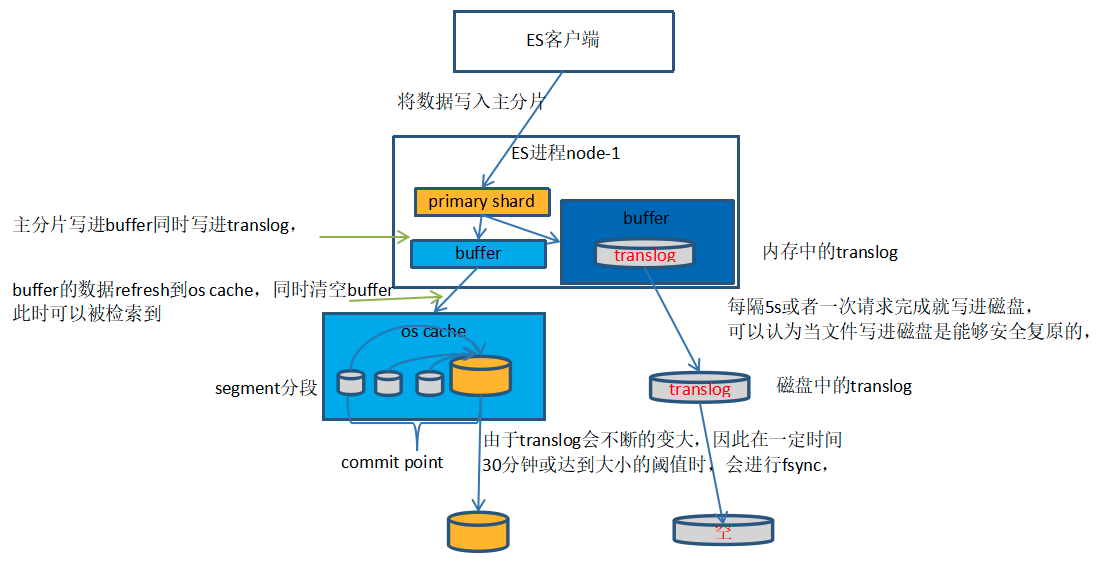
1、数据先被写进内存buffer,同时这一操作也写进translog中,这时的数据还不可被检索到。
2、每隔1s(这个时间可以调整)进行一次refresh,将buffer内1s的数据写进os cache中,构成一个segment分段,同时清空buffer,这时数据可以被检索到,但由于数据仍然在内存中,若发生故障,数据是可以丢失的。
3、不断地重复上面的步骤,不断产生新的segment,translog也不断的变大。
4、当时间达到30分钟或者translog足够大的时候,进行一次fsync,将内存中所有的segment都写进磁盘中,并删除translog,重新生成新的translog。
由上面可以看得出来,文件存储在内存以及os cache中是不安全的,因此ES引入translog来记录两次fsync之间的操作,以便发生故障,也能恢复数据。
但translog也是存在内存中的,发生故障依然会丢失数据,因此每隔5s或一次请求完成后,translog就会写进磁盘,被写进磁盘后就可以认为是安全复原的,因此只有当translog写入磁盘后,ES才能向客户端反馈成功的信息。
另外每隔1s就产生一个segment,很快分片内就有大量的segment,而搜索时会搜索所有的segment,影响性能,因此ES会自动合并大小相似的segment,同时删除合并的旧segment
3.2. 删除/更新的底层原理
ES的索引是不能改的,删除和更新都不是直接在原索引中执行
每一个segment都会维护一个del文件,用来记录删除的文档。用户发出删除请求后,文档并没有真正被删除,而是del文件中记录被删除的文档,但该文档依然能被检索到,只是在最后过滤掉,当segment合并时,才会真正地删除del标志的文档。
更新文档,首先获取原文档的版本号,然后将修改后的文档和版本号一起写进,这过程和新增相同,同时旧文档也被标志成删除文档,同样能被检索到,只不过最终被过滤掉而已

