
寒假学习进度
行动算子
(1)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// //两两聚合
// val i: Int = rdd.reduce(_+_)
// print(i)
// //方法将不同分区的数据采集到driver端内存中,形成数组
// val ints: Array[Int] = rdd.collect()
// println(ints.mkString(","))
//数据源中的数据个数
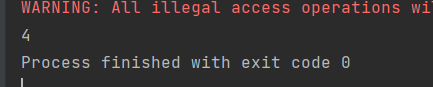
val l: Long = rdd.count()
print(l)
//
// //数据源中的第一个
// val i: Int = rdd.first()
// //获取多少个数据
// val ints: Array[Int] = rdd.take(3)
// print(ints.mkString(","))
// //先排序,然后在取数据
// val ints: Array[Int] = rdd.takeOrdered(3)
// print(ints.mkString(","))
sc.stop()
}

(2)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//(初始值)(分区内规则,分区外规则)
//aggregate的初始值会参与分区内的计算,并且参与分区间的计算
//aggregatebykey的初始值会参与分区内的计算
// val i: Int = rdd.aggregate(0)(_ + _, _ + _)
// println(i)
//fold是aggregate的简化
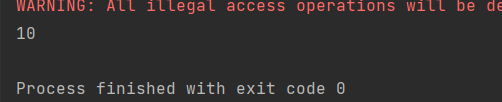
val i: Int = rdd.fold(0)(_ + _)
println(i)
sc.stop()
}
(3)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// val rdd = sc.makeRDD(List(1, 2, 3, 4))
//统计数据出现的次数
// val intToLong: collection.Map[Int, Long] = rdd.countByValue()
// print(intToLong)
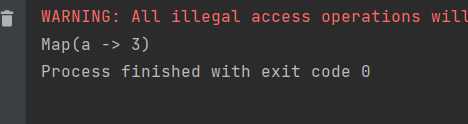
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3)))
val stringToLong: collection.Map[String, Long] = rdd.countByKey()
print(stringToLong)
sc.stop()
}
(4)
//groupby:
def wordcount1(sc:SparkContext)={
val fileRDD: RDD[String] = sc.textFile("D:\\qq text\\1791028291\\FileRecv\\《飘》英文版.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
val group: RDD[(String, Iterable[String])] = wordRDD.groupBy(word => word)
val wordcount: RDD[(String, Int)] = group.mapValues(iter => iter.size)
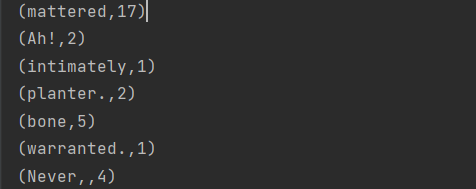
wordcount.collect().foreach(println)
}
//reduceByKey
def wordcount2(sc:SparkContext)={
val fileRDD: RDD[String] = sc.textFile("D:\\qq text\\1791028291\\FileRecv\\《飘》英文版.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
val wordmap: RDD[(String, Int)] = wordRDD.map((_, 1))
val group: RDD[(String, Int)] = wordmap.reduceByKey(_ + _)
group.collect().foreach(println)
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App