每日总结
词频统计
WordCountMapper:
package com.atguigu.hdfs;
import java.io.IOException;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//super.map(key, value, context);
//String[] words = StringUtils.split(value.toString());
String[] words = StringUtils.split(value.toString(), " ");
for(String word:words)
{
context.write(new Text(word), new LongWritable(1));
}
}
}
WordCountReducer
package com.atguigu.hdfs;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text arg0, Iterable<LongWritable> arg1, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//super.reduce(arg0, arg1, arg2);
int sum=0;
for(LongWritable num:arg1)
{
sum += num.get();
}
context.write(arg0,new LongWritable(sum));
}
}
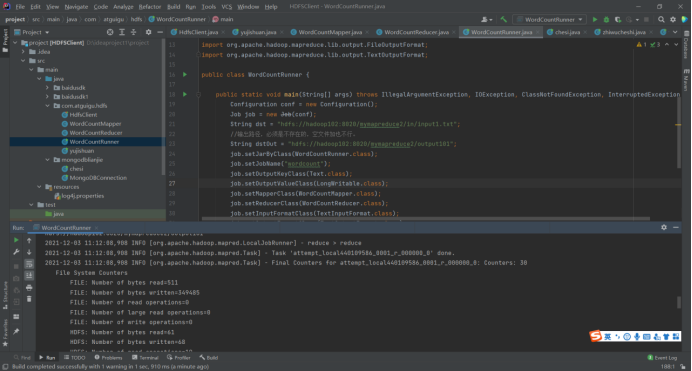
WordCountRunner
package com.atguigu.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCountRunner {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
String dst = "hdfs://hadoop102:8020/mymapreduce2/in/input1.txt";
//输出路径,必须是不存在的,空文件加也不行。
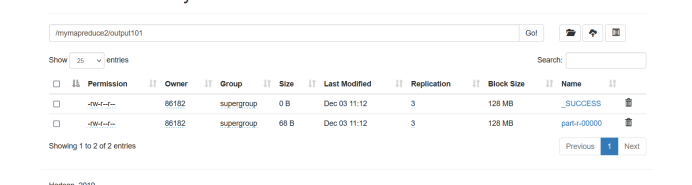
String dstOut = "hdfs://hadoop102:8020/mymapreduce2/output101";
job.setJarByClass(WordCountRunner.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
job.waitForCompletion(true);
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号