每日总结
Mapreduce实例——排序
依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-app</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
实验代码:
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
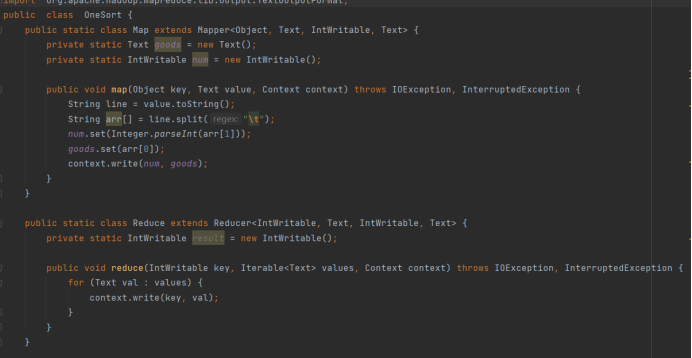
public class OneSort {
public static class Map extends Mapper<Object, Text, IntWritable, Text> {
private static Text goods = new Text();
private static IntWritable num = new IntWritable();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String arr[] = line.split("\t");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num, goods);
}
}
public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text> {
private static IntWritable result = new IntWritable();
public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text val : values) {
context.write(key, val);
}
}
}
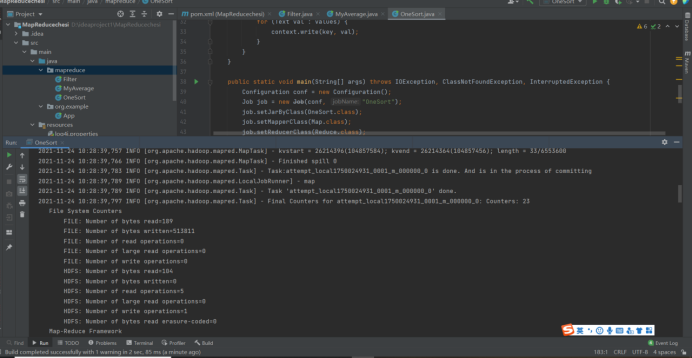
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf, "OneSort");
job.setJarByClass(OneSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
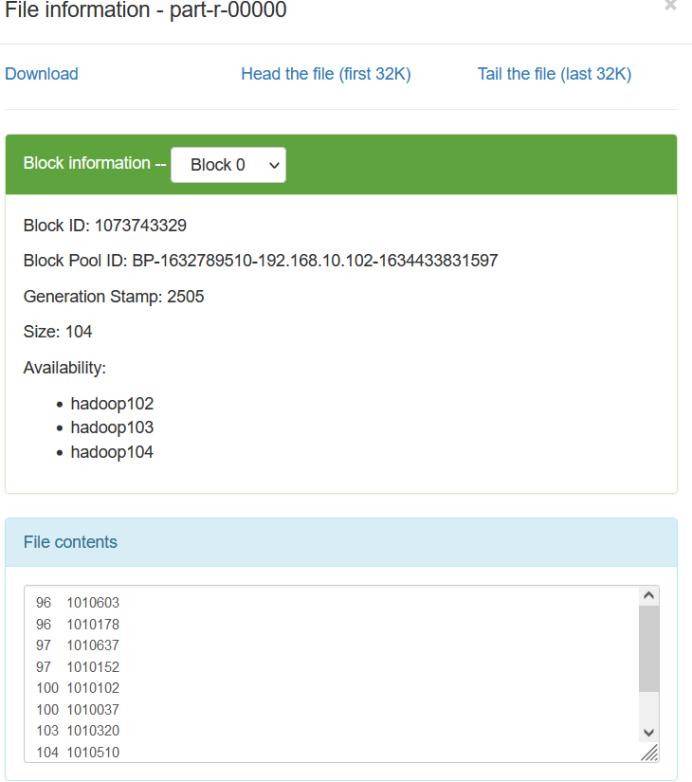
Path in = new Path("hdfs://hadoop102:8020/mymapreduce2/in/goods_visit1");
Path out = new Path("hdfs://hadoop102:8020/mymapreduce2/out2");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号