每日总结
Mapreduce实例——倒排索引
依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-app</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
实验代码:
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyIndex {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("InversedIndexTest");
job.setJarByClass(MyIndex.class);
job.setMapperClass(doMapper.class);
job.setCombinerClass(doCombiner.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in1 = new Path("hdfs://hadoop102:8020/mymapreduce2/in/goods3");
Path in2 = new Path("hdfs://hadoop102:8020/mymapreduce2/in/goods_visit3");
Path in3 = new Path("hdfs://hadoop102:8020/mymapreduce2/in/order_items3");
Path out = new Path("hdfs://hadoop102:8020/mymapreduce2/out7");
FileInputFormat.addInputPath(job, in1);
FileInputFormat.addInputPath(job, in2);
FileInputFormat.addInputPath(job, in3);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, Text> {
public static Text myKey = new Text();
public static Text myValue = new Text();
//private FileSplit filePath;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath = ((FileSplit) context.getInputSplit()).getPath().toString();
if (filePath.contains("goods")) {
String val[] = value.toString().split("\t");
int splitIndex = filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
} else if (filePath.contains("order")) {
String val[] = value.toString().split("\t");
int splitIndex = filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
public static class doCombiner extends Reducer<Text, Text, Text, Text> {
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
public static class doReducer extends Reducer<Text, Text, Text, Text> {
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
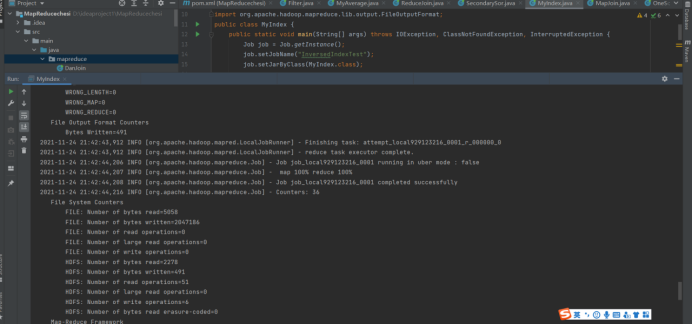
}
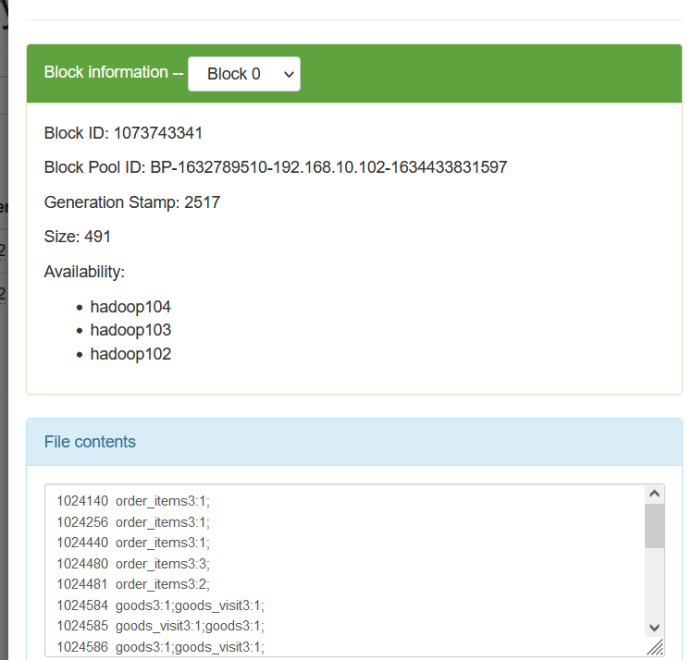

 浙公网安备 33010602011771号
浙公网安备 33010602011771号