

hadoopMR自定义输入格式
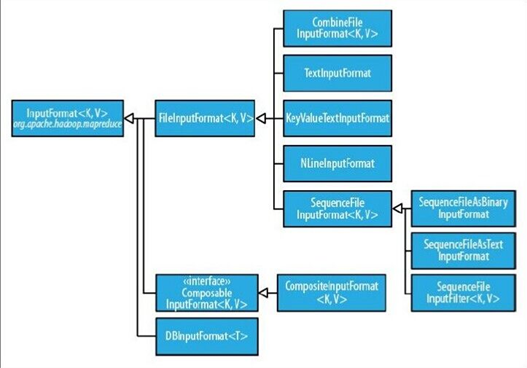
输入格式
1、输入分片与记录
2、文件输入
3、文本输入
4、二进制输入
5、多文件输入
6、数据库格式输入
详细的介绍:https://blog.csdn.net/py_123456/article/details/79766573
1、输入分片与记录
1、JobClient通过指定的输入文件的格式来生成数据分片InputSplit。
2、一个分片不是数据本身,而是可分片数据的引用。
3、InputFormat接口负责生成分片。
InputFormat 负责处理MR的输入部分,有三个作用:
验证作业的输入是否规范。
把输入文件切分成InputSplit。
提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理。
2、文件输入
抽象类:FilelnputFormat
1、FilelnputFormat是所有使用文件作为数据源的InputFormat实现的基类。
2、FilelnputFormat输入数据格式的分片大小由数据块大小决定。
FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类如TextInputFormat进行实现的。
3.文本输入
| TextInputFormat: | 默认的输入方式,key是该行的字节偏移量,value是该行的内容<LongWritable,Text> |
| KeyValueTextInputFormat |
job.getConfiguration().setStrings(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, ":");//默认的分隔符‘\t’,可以设置分割符,分割之后以分割符前的作为key,分隔符后的作为vallue 如果不设置分隔符则key为一整行内容,value为空<Text,Text> |
| NlineInputFormat |
NLineInputFormat.setNumLinesPerSplit(job, 3);// 设置每次读3行内容为mapper输入<Text,IntWritable>,key和value与TestInputFormat一样 |
4、二进制输入
SequenceFileInputFormat 将key和value以sequencefile格式输入。<Text,IntWritable>
先使用二进制输出格式输出一个二进制文件再作为输入文件
5.多文件输入
在一个MapReduce作业中所有的文件由一个mapper来处理不能满足不同文件格式需求,可以指定不同的文件由不同的mapper来处理,然后输出一样的类型给reduce
like:
MultipleInputs.addInputPath(job,OneInputpath,TextInputFormat.class,OneMapper.class)
MultipleInputs.addInputPath(job,TowInputpath,TextInputFormat.class,TowMapper.class)
(addInputPath()只能指定一个路径,如果要想添加多个路径需要多次调用该方法:)
2、通过addInputPaths()方法来设置多路径,多条路径用分号(;)隔开
String paths = strings[0] + "," + strings[1];
FileInputFormat.addInputPaths(job, paths);
6。数据库输入:DBInputFormat
用于使用JDBC从关系数据库中读取数据,DBOutputFormat用于输出数据到数据库,适用于加载少量的数据集
(DBInputFormat map的输入(Longwriatble,Dbwritable的实现类)
自定义输入格式要点:
1自定义一个MyRecordReader类继承抽象类:RecordReader,
每一个数据格式都需要有一个recordreader,主要用于将文件中的数据拆分层具体的键值对,Textinputformat中默认的recordreader值linerecordreader
2自定义inputFormat继承Fileinputformat类,重写inputformat中的cretaeRecordReader()方法,返回自定义的MyRecordReader类
3.job.setInputformatclass(自定义的Inputformat.class)
代码:
package com.neworigin.RecordReaderDemo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.LineReader;
public class MyRecordReader {
static Path in=new Path("file:///F:/安装/java工程/RecordReaderDemo/data/in/test.txt");
static Path out=new Path("file:///F:/安装/java工程/RecordReaderDemo/data/out");
//自定义Recordreader
public static class DefReadcordReader extends RecordReader<LongWritable ,Text>{
private long start;
private long end;
private long pos;
private FSDataInputStream fin=null;
private LongWritable key=null;
private Text value=null;
private LineReader reader=null;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
FileSplit filesplit=(FileSplit)split;
//
start=filesplit.getStart();
end=filesplit.getLength()+start;
//
Path path = filesplit.getPath();
Configuration conf = new Configuration();
//Configuration conf = context.getConfiguration();
FileSystem fs=path.getFileSystem(conf);
fin=fs.open(path);
reader=new LineReader(fin);
pos=1;
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int kkk = reader.readLine(value);//获取当前行内容的偏移量
System.out.println(kkk);
if(key==null)
{
key=new LongWritable();
}
key.set(pos);
if(value==null)
{
value=new Text();
}
// value.set(pos);
if(reader.readLine(value)==0)
{
return false;
}
pos++;
return true;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
if(fin!=null)
{
fin.close();
}
}
}
//自定义输入格式
public static class MyFileInputFormat extends FileInputFormat<LongWritable,Text>{
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
DefReadcordReader reader = new DefReadcordReader();//返回自定义的recordReader类
return reader;
}
@Override
protected boolean isSplitable(JobContext context, Path filename) {
// TODO Auto-generated method stub
return false;
}
}
public static class MyMapper extends Mapper<LongWritable,Text,LongWritable,Text>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context)
throws IOException, InterruptedException {
context.write(key,value);
}
}
//根据奇偶数行来分区
public static class MyPartition extends Partitioner<LongWritable,Text>{
@Override
public int getPartition(LongWritable key, Text value, int numPartitions) {
if(key.get()%2==0)
{
key.set(1);
return 1;
}
else
{
key.set(0);
return 0;
}
}
}
public static class MyReducer extends Reducer<LongWritable,Text,Text,IntWritable>{
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
Text write_key=new Text();
IntWritable write_value=new IntWritable();
int sum=0;
for (Text value:values)
{
sum+=Integer.parseInt(value.toString());
}
if(key.get()==0)
{
write_key.set("奇数行之和");
}
else
{
write_key.set("偶数行之和");
}
write_value.set(sum);
context.write(write_key, write_value);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(conf);
if(fs.exists(out))
{
fs.delete(out);
}
Job job = Job.getInstance(conf,"MyRedordReader");
job.setJarByClass(MyRecordReader.class);//打包运行时需哟啊
FileInputFormat.addInputPath(job, in);
job.setInputFormatClass(MyFileInputFormat.class);
//job.setInputFormatClass(KeyValueTextInputFormat.class);
//conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(MyPartition.class);
job.setReducerClass(MyReducer.class);
job.setNumReduceTasks(2);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, out);
//TextInputFormat
System.exit(job.waitForCompletion(true)?0:1);
}
}

