

linux配置hadoop集群
①安装虚拟机
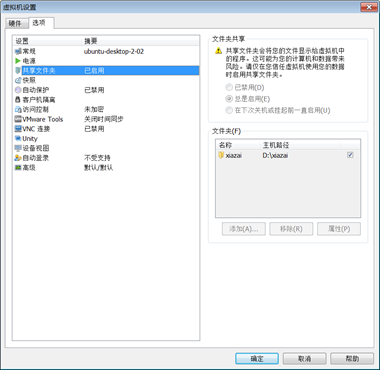
②为虚拟机添加共享文件
右击已经安装好的虚拟机
设置—>选项—>共享文件
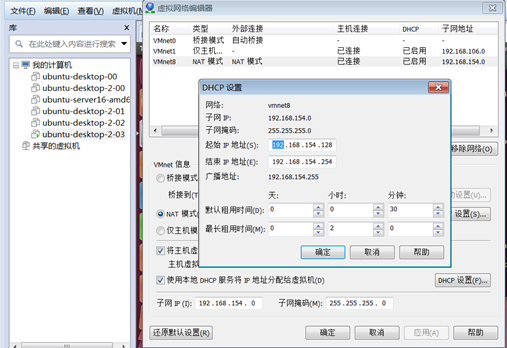
③配置映射
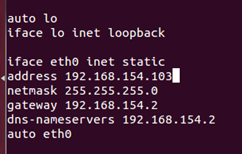
sudo nano /etc/network/interfaces

重启网络:sudo /etc/init.d/networking restart(如果网络重启失败则重启虚拟机:sudo reboot)
sudo nano /etc/hostname
s100
sudo nano /etc/hosts
|
192.168.154.100 s100 |

在windows下c:/windows/system32/driver/etc/host

本地连接虚拟机:ping s100
④搭建集群
创建一个文件夹放置集群:
sudo mkdir -p /home/neworigin/data
修改data文件夹的权限:
配置java环境:
将本地的jdk压缩包拷贝到虚拟机:cp /mnt/hgfs/本地路径 /data/
解压:tar -xzvf jdk.tar.gz
配置jdk路径:sudo nano /etc/environment
JAVA_HOME=/data/jdk
PATH=":/data/jdk/bin"
使环境变量生效:soirce /etc/environment
查看版本:java -version

配置hadoop;
拷贝本地的安装包:cp /mnt/hgfs/本地路径 /data
解压:tar -xzvf hadoop-2.7.0.tar.gz
配置路径:sudo nano /etc/environment
HADOOP_HOME=/data/hadoop-2.7.0.tar.gz
PATH=":/data/hadoop-2.7.0/bin:/data/hadoop-2.7.0/sbin"
查看hadoop中的文件:ls -l /data/hadoop-2.7.0/etc/hadoop
修改配置文件:core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml

