

mysql学习
安装:https://blog.csdn.net/qq_37350706/article/details/81707862
mysql8.0官方中文文档:https://dev.mysql.com/doc/refman/8.0/en/mysql-nutshell.html
窗口函数学习:https://blog.csdn.net/m0_38063172/article/details/83789830
窗口函数运用:https://blog.csdn.net/zhangshk_/article/details/82756557
事务:在mysql中只有使用了Innodb的数据引擎的数据库才支持
保证成批的SQL语句(insert,update,delete)要么全部执行,要么全部不执行
事务的满足条件(ACID):原子性,一致性、隔离性、持久性
原子性:一个事务中操作要么全完成、要么全部不完成,发生错误时Rollback到事务开始前状态
一致性:事务开始前,和开始之后,数据库的完整性没有被破坏,表示写入的资料必须完全符合预设规则
隔离性:允许多个并发事务同事对数据进行读写和修改能力
持久性:事务处理结束后,对数据的修改是永久的
mysql中默认是自动提交事务,可通过set autocommit =0 来禁止自动提交
set autocommit=1 启动自动提交
begin开启事务
rollback回滚事务,回到事务开启之前
commit提交,确认事务
存储过程:
格式:create procedure pro_name (参数) 特性描述 routine_body
参数:in、out、inout name type
特性描述:language sql 说明后面部分是sql语句组成
[not] deterministic说明执行结果是确定的,not deterministic说明执行结果是非确定的
contains sql说明子程序包含sql语句
no sql说明子程序不包含sql语句
reads sql date 说明子程序中包含读数据语句
modifies sql date说明子程序包含写数据语句
sql security 指明谁有执行权限,definer只有定义者有,invoker调用者有
例:
create procedure num_from_employee(in emp_id int, out count_num int) reads sql date
begin
select count(*) into count_num from employee where d_id=emp_id;
end
执行过程
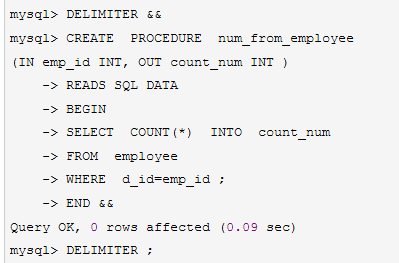
说明:mysql的默认结束符是;,存储过程中的sql语句需要用分号;来结束,为了避免冲突可以用delimiter 改变sql的结束符,如delimiter &&,存储过程执行完之后再改变回来
函数
格式:create function name(参数)returns type 特性描述 routine_body
参数:name type
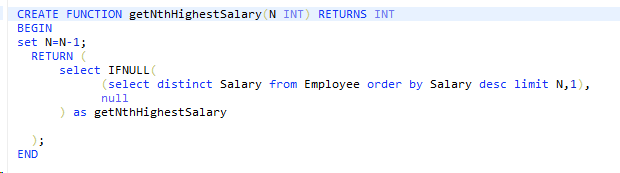
变量的使用:
使用 declare定义变量:declare name[...] type [default value]
DECLARE关键字是用来声明变量的;var_name参数是变量的名称,这里可以同时定义多个变量;type参数用来指定变量的类型;DEFAULT value子句将变量默认值设置为value,没有使用DEFAULT子句时,默认值为NULL
如:declare a int default 10;
为变量赋值:使用set ,一个set语句可以为多个变量赋值,使用,分开
如set a=10,b=20;
定义条件和处理程序:用于事先定义执行过程中可能遇到的问题,并在处理程序中定义解决问题的办法
格式:declare condition_name condition for condition_value
condition_value:
sqlstate sqlstate_value、mysql_error_code
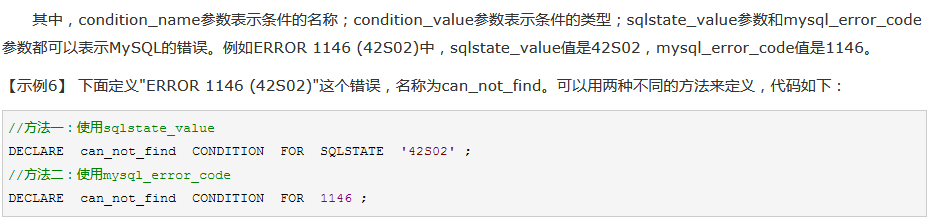
定义处理程序:
mysql中的用户变量:
mysql变量分为两类:用户变量、系统变量
用户变量:局部变量、会话变量
系统变量:全局变量、会话变量
ps:用户定义的会话变量和系统定义的会话变量有什么区别?
局部变量用于SQL的语句块中,如存储过程中的begin和end中,作用域仅限于改语句块,生命周期也限于该存储过程
如:create procedure add(in a int ,out b out)
begin
declare c int default 0;#局部变量
set c=a+b;
select c as c;
end&&
会话变量:服务器对每个客户端连接维护的变量,作用域和生命周期限于当前客户
。。。。。
窗口函数:
语法:函数名(变量) over子句
over关键字用于指定函数的窗口范围,支持一下四种语法来设置窗口
window给窗口指定一个别名
partition指定分组字段
order by指定排序字段
frame当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用
select* from (select row_number() over w as row_num,order_id,user_no,amount,create_date from order_tab window w as (partition by user_no order by amount desc))t;
https://www.cnblogs.com/DataArt/p/9961676.html
索引
mysql索引:可以提高检索速度
单列索引:一个索引只包含一列,一个表可以有多个单列索引
组合索引:一个索引包含多个列
临时表
只对当前连接有效,关闭连接之后自动删除并释放空间:create temporary table tmp_table1(int id,string name);
使用show tables无法查看到临时表,断开此次连接之后,临时表自动删除
匹配模式:like 或 not like
_匹配单个字符
%匹配任意数量字符
-------------------------------------------------------------
正则表达式:REGEXP_LIKE
. 匹配任意单个字符
[xyz] 匹配[ ]中的任意字符,如[0-9]表示匹配数字,[a-z]表示匹配字母
* 匹配任意个数量,如a*表示匹配任意个数量的a,[0-9]*表示匹配任意个数字,.*表示匹配任意个数量的字符
^b 匹配以b开头
$b 匹配以b结尾
select * from pet where regexp_like(name,'^b'); 表示查询所有名字以b开头的
order by 根据某个记录进行排序 desc 降序,asc 升序
group by 根据某个记录进行分分组
partition by
having:对前面筛选出的结果再次进行筛选
select distinct Email from Person group by Person.Email having count(Email)>1;
where
列属性:
primary 主键 :create table tab(id int,name varchar(10),primary key(id));
unique 唯一约束,使某字段的值不能重复复
null:当前列可以为空
default默认值:create table tab (add_time timestamp default current_timestamp);
auto_increment自动增长,必须为primary或者unique,且只能存在一个列自动增长
comment注释内容:create table tab(id int)comment "注释内容";
foreign key外键约束:用于限定主表与从表数据完整性 alter table tab constraint 't1_t2_fk' foreign key(t1_id) references t2(t2_id)
将t1的外键t1_id关联t2_id,外键还可以通过constraint指定名字
存在外键的表为从表,外键指向的表为主表
指定主键的删除(on delete)和更新(on uodate)时外键的操作,如果不指定,主表的操作是拒绝的
1.cascade,级联操作,主表更新,从表更新,主表删除,从表删除
2.set null:主表主键更新时从表的外键被设置为null,主表主键删除时,从表外键设置为null,此时从表的外键不能有not null约束
3.restrict:拒绝主表的删除和更新操作
范式:
第一范式:字段具有原子性,不能再分
第二范式:满足第一范式为前提,不能出现部分依赖
第三范式:满足第二范式,不能出现传递依赖
MYSQL中的表连接方式:外连接、内连接、交叉连接、自连接
https://blog.csdn.net/qiushisoftware/article/details/80489128
外连接分为:左外连接、右外连接、全外连接
1.左外连接:将左边表的数据全部显示,右外表中条件不符合的显示为null
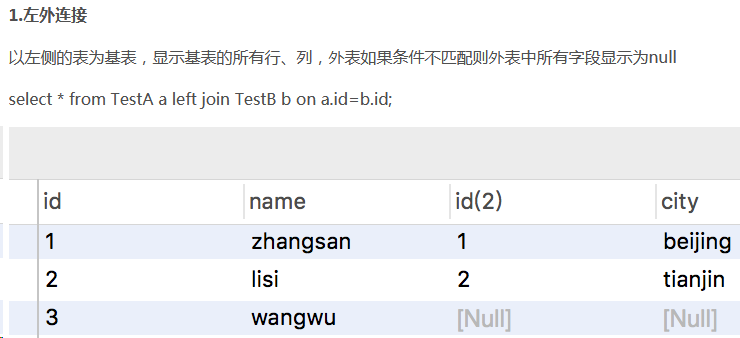
2.右外连接:将右边表的数据全部显示,左外表中条件不符合的显示为null

3.全连接:所有表的所有行、列都会显示,彼此条件不满足的值为null(mysql不支持,但可以通过union实现)

内连接:查询结果仅仅包含满足条件的行,内连接inner join 可简写为join
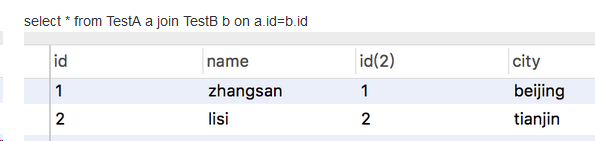
交叉连接:笛卡尔积连接,左右表的元组任意组合,一般情况没有意义
连接过程中的on和where
on表示建立连接的关系
where对建立连接关系进行筛选
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 在使用left jion时,on和where条件的区别如下:
1、on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉
以下为练习:

IFNULL的使用:
IFNULL(exp1,exp2),如果查询结果为空返回exp2,不为空时返回exp1
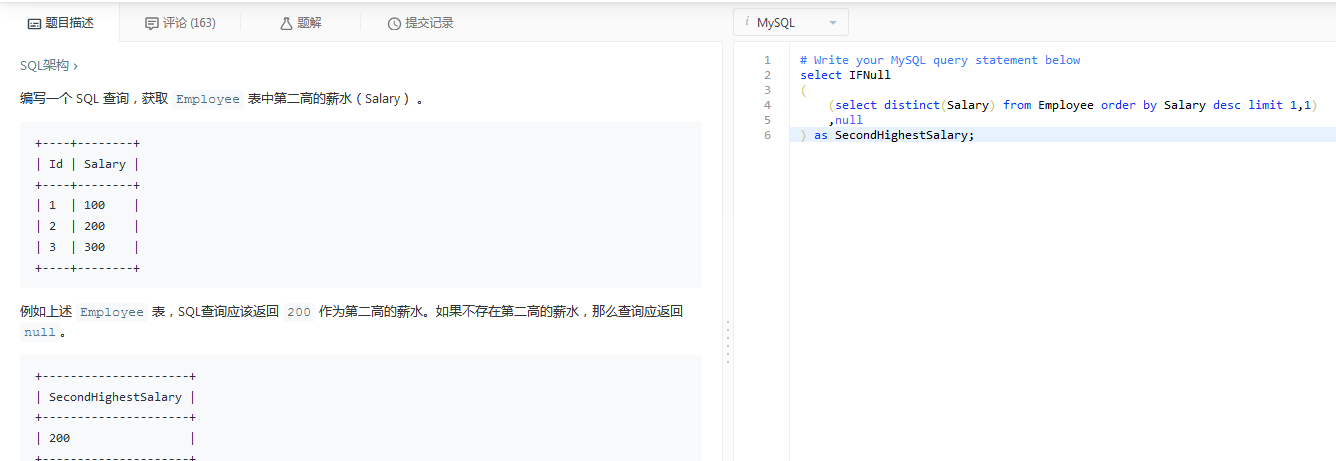
使用DATEDIFF来表示来个日期类型的数据的天数差:DATEDIFF(date1,date2)=n

hiving对聚合函数的操作结果进行筛选,where在聚合函数之前进行筛选
判断奇数以及不等于

使用case then 来判断:
case的使用格式:
case case_expression
when exp1 then com1
when exp2 then com2
else com
end
例如将男改为1,女改为2
case sex
when "男" then 1
when "女" then 2
end
________________________________
case score
when score>90 then "优秀"
when score<60 then "及格"
else “良好”
end
if(exp,exp1,exp2)如果exp为真则返回exp1,否则返回exp2

select a.Name as Employee from Employee a join Employee b on a.ManagerId=b.Id where a.Salary > b.Salary;

