
大数据开发面试
①hbase的写入速度下降造成的原因是什么,怎么解决?
②zookeeper的结构,在Hadoop集群中的作用
zookeeper在hadoop集群中可以实现高可用,使active namenode和standby nanemode通过jrounalnode通信,保持同步信息,避免单点故障
此篇关于zookeeper在hadoop和hbase中的应用:https://blog.csdn.net/zhang123456456/article/details/78008626
③hbase以可否以时间戳作为row key,会存在什么问题,怎么解决?
https://www.cnblogs.com/duanxz/p/4660784.html
④数据倾斜?提供一种解决方案;什么是负载均衡?
MapReduce是分布式计算框架,将任务程序分别分配到多个节点来来执行,如果某个节点处理数据过大则影响整个集群的效果,所以需要将数据均匀的分配到每个reduce,保证个节点处理速度相差不大。
解决数据倾斜:
①自定义分区类:通常是按照map的hashcode来进行分区,所以map相同的会分到同一个区然后在一个reduce中处理
②重新设计key:在map阶段给key追加个随机数,再reduce阶段之后再把reduce去掉,这样大量相同key的几率比较小
③添加reducetask数量来处理啊reduce任务
负载均衡:
⑤sql应用的窗口函数
⑥block大小是128M,怎么存储一个142M的文件
分成两个数据块:一个block1(128M),一个block2(14M);
然后namenode返回可用的datanode用于存储数据块,默认副本数是3,所以根据机架感知分别存储到三个节点上,保证数据安全可靠
block1:host1,host2,host5
block2:host3、host4、host6
机架感知:副本1存在和client同一个节点,副本2存在不同机架的一个节点,副本3放在和副本2同一个机架的不同节点上
⑦hbase表:用户ID,登录时间戳login_time,统计每个用户在0-6、6-12、12-18、18-24的登录次数?
⑧配置免密登录
⑨hadoop集群中各角色的作用?
分布式文件系统:hdfs
namenode主节点,存储元数据(数据块的存储位置信息,大小)
secondarynamenode辅助节点,用于合并fsimage和edits文件,减少namenode的启动时间
datanode数据节点:用于存储数据
分布式计算框架:mapreduce
map
reduce
资源管理器:yarn
resourcemanager:分配资源
nodemanager:响应resourcemanager的安排。为程序提供资源
各角色的作用:
namenode:接受客户端的请求;管理元数据的信息;为数据块的副本存储分配节点
secondarynamenode:帮助namenode合并元数据,减少namenode的压力
datanode:处理客户端的读写请求;存储数据块,进行副本的复制
补充:mapreduce各阶段详解
①combinner阶段:(可选)是一个本地的reduce,在map计算出中间结果之前将相同的key进行一个简单的合并,减轻了map到reduce阶段的数据传输量,也减轻了map端到reduce端shuffle阶段的数据拉取量(本地化磁盘IO)combinner必须保证不影响reduce的输出结果,如求取最大值、最小值、求和可以使用,求平均值则不行。
②partitioner阶段:mapper输出将不同的key分区发送到不同的reduce,reduce运行之后按分区存储计算结果,默认的分区方式:key的hashcode/numreducetask
③shuffle阶段:将map的输出结果作为reduce的输入的过程,包括:输出、排序、溢写、合并等步骤。
map的输出结果通常是一个非常大的文件不可能将所有中间结果都保存到磁盘,map写入磁盘是一个十分复杂的过程,map在输出时会在内存中开启一个环形内存缓冲区,默认大小100M,阈值为0.8,达到阈值就把数据写到磁盘,写入磁盘前还会有排序操作,这个过程叫做spill,如果有combinner函数,还会执行combiner,每次spill的时候都会有一个溢出文件,等map输出完成之后再合并这些溢出文件。这个阶段还有partitioner,partition与map阶段的输入分片相似,一个partition对应一个reduce
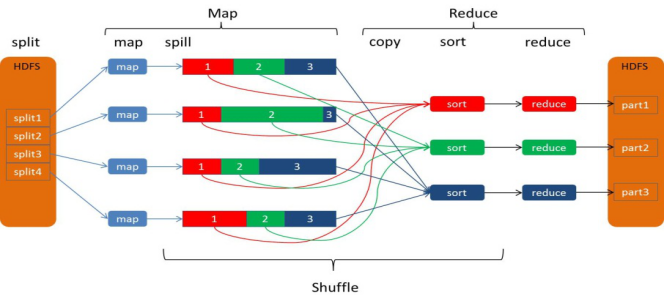
Map-Shuffle:
写入之前先进行分区Partition,用户可以自定义分区(就是继承Partitioner类),然后定制到job上,如果没有进行分区,框架会使用 默认的分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
将分完区的结果<key,value,partition>开始序列化成字节数组,开始写入缓冲区。
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存—>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
溢写spill线程启动后,开始对key进行排序(Sort)默认的是自然排序,也是对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序)。
如果客户端自定义了Combiner之后(相当于map阶段的reduce),将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量(Combiner使用一定得慎重,适用于输入key/value和输出key/value类型完全一致,而且不影响最终的结果)
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做Merge,最终结果就是一个group({“aaa”,[5,8,3]})
集合里面的值是从不同的溢写文件中读取来的。这时候Map-Shuffle就算是完成了。
一个MapTask端生成一个结果文件。
shuffle阶段的详细讲解:https://www.cnblogs.com/edisonchou/p/4298423.html
自定义输入函数、分区函数
二次排序:先按第一列排序再按第二列排序
读取二进制文件
mapreduce性能调优
小文件合并
大数据面试题:https://www.cnblogs.com/gala1021/p/8552850.html
------------------------------------------------------------------------------------------------------------------
珍爱网深大大数据开发现场笔试
hbase的二级索引实现方式
mysql联合索引,以下不正确的是
分解质因数,手写代码
多用户访问服务器,怎么让同一用户访问某一固定服务器
创建对象的方式,哪些不调用构造函数
常用的设计模式及使用场景,手写代码
mysql三张表的各种查询
hdfs工作原理
mapreduce执行过程
堆区及栈区的区别
thread中run()和main的执行顺序:
main(){
thread.run()
print(za);
}
Thread(){
print(“ZA”)
exit(0)}
spark能完全脱离Hadoop?
hadoop利用hive能实现增删改查功能?
hdfs以流的方式上传文件?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号