
openpyxl读写Excel文件
安装
pip install openpyxl
一个简单的实例:
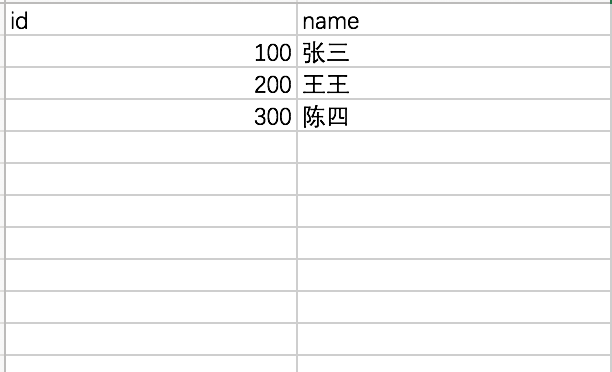
最初的表格
#!/usr/bin/env python # -*- coding:utf-8 -*- import openpyxl from openpyxl import Workbook from openpyxl import load_workbook import datetime file_name='/Users/chichi/Documents/TestStudy/TestExcel/data.xlsx' wb=load_workbook(file_name) ws=wb['Sheet1'] #直接根据位置进行赋值 ws['A5']=400 ws['B5']='杨四' #直接存储Python的时间类型变量 ws['A11'] = datetime.datetime.now() #cell方法通过输入参数row、column、value来操作单元格 ws.cell(row=6,column=1,value=500) ws.cell(row=6,column=2,value='程五') #读取数据 for row in ws.rows: # 返回的row是一个tuple对象 for cell in row: print 'row: %s column: %s value: %s' % (cell.row,cell.column,cell.value) # 保存文件 wb.save(file_name)
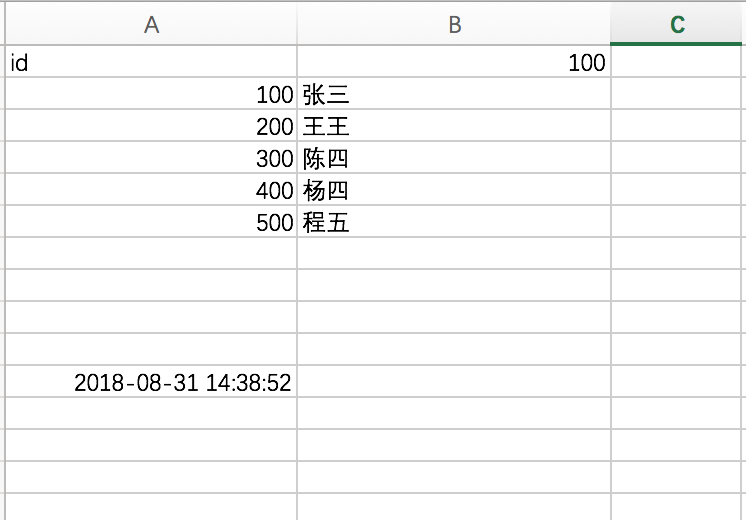
执行以上代码后的表格:
Excel文档名词解释:
一个Excel表格文件(xlsx)包含一个工作薄(workbook),一个工作薄可以包含多个工作表(worksheets)。用户正在查看的工作表是激活的工作表(active sheet)。
每个工作表都有行和列,行以数字1开始,列以字母A开始。一个工作表由单元格(cell)组成,单元格可以存储数字和字符串
Workbook属性
sheetnames: 返回所有WorkSheet的名字列表,类型为list
worksheets: 返回所有WorkSheet的列表,类型为list
active: 返回当前默认选中的WorkSheet
实例:
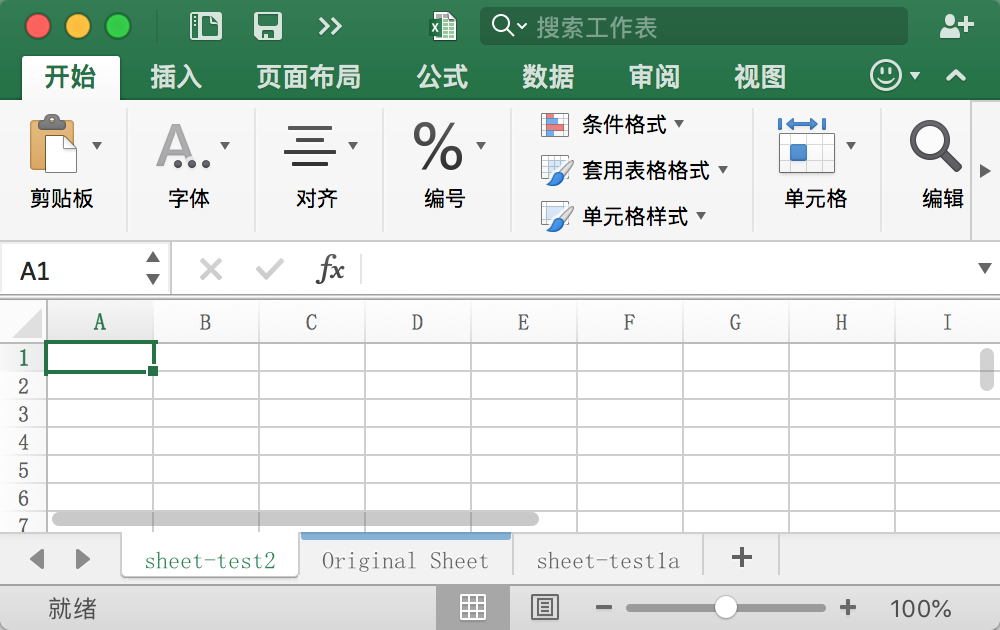
test.xlsx 表格如下
file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) print(wb.sheetnames) print(wb.worksheets) print(wb.active)
执行结果:
python /Users/chichi/Documents/TestStudy/TestOpenpyxl.py [u'sheet-test2', u'Original Sheet', u'sheet-test1a'] [<Worksheet "sheet-test2">, <Worksheet "Original Sheet">, <Worksheet "sheet-test1a">] <Worksheet "sheet-test2">
Workbook方法
get_sheet_names(): 同sheetnames
get_active_sheet(): 同active属性
get_sheet_by_name(name):根据名称获取WorkSheet
remove(worksheet): 删除一个WorkSheet,注意是WorkSheet对象,不是名字
save(filename): 保存到文件,记住有写入操作记得保存!!!file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) wb.remove(wb.get_sheet_by_name('sheet-test1a')) print (wb.get_sheet_names()) print (wb.get_active_sheet()) wb.save(file_name)
执行结果:
[u'sheet-test2', u'Original Sheet'] <Worksheet "Original Sheet">
如何创建一个Workbook对象?
# 利用openpyxl来创建Workbook对象无需新建文件,可以直接实例化一个Workbook对象即可
wb = Workbook()
dest_filename = '/Users/chichi/Documents/TestStudy/test.xlsx'
ws = wb.active
#每个workbook创建后,默认会存在一个worksheet,对默认的worksheet进行重命名
ws.title = "Original Sheet"
#再自行创建一个sheet-test
ws1 = wb.create_sheet("sheet-test1")
#对worksheet进行重命名
ws1.title = "sheet-test1a"
#指定插入worksheet的位置,第一个默认的worksheet 从0开始,在这之前插入sheet-test2
ws2 = wb.create_sheet("sheet-test2", 0)
ws.sheet_properties.tabColor = "1072BA"
# 查看一个workbook中全部的Worksheet的名称,返回值为List
print wb.sheetnames
# 通过遍历方式打印所有的sheetname
for sheet in wb:
print sheet.title
wb.save(filename = dest_filename)
执行结果:
[u'sheet-test2', u'Original Sheet', u'sheet-test1a']
sheet-test2
Original Sheet
sheet-test1a
WorkSheet属性
rows: 返回所有有效数据行,有数据时类型为generator,无数据时为tuple
columns:返回所有有效数据列,类型同rows
max_column:有效数据最大列
max_row:有效数据最大行
min_column:有效数据最小列,起始为1
min_row:有效数据最大行,起始为1
values:返回所有单元格的值的列表,类型为tuple
title:WorkSheet的名称
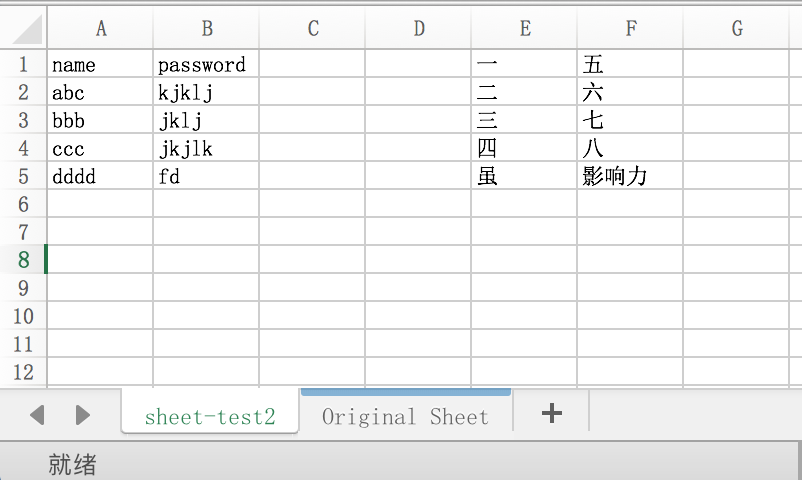
表格如下:
file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) ws = wb.active #打印出所有的单元格的值 for i in ws.rows: for j in i: print u"第%s行第%s列的值是%s:" %(j.row,j.column,j.value) print ws.rows print ws.columns print ws.max_column print ws.max_row print ws.title print ws.values
执行结果:
第1行第A列的值是name: 第1行第B列的值是password: 第1行第C列的值是None: 第1行第D列的值是None: 第1行第E列的值是一: 第1行第F列的值是五: 第2行第A列的值是abc: 第2行第B列的值是kjklj: 第2行第C列的值是None: 第2行第D列的值是None: 第2行第E列的值是二: 第2行第F列的值是六: 第3行第A列的值是bbb: 第3行第B列的值是jklj: 第3行第C列的值是None: 第3行第D列的值是None: 第3行第E列的值是三: 第3行第F列的值是七: 第4行第A列的值是ccc: 第4行第B列的值是jkjlk: 第4行第C列的值是None: 第4行第D列的值是None: 第4行第E列的值是四: 第4行第F列的值是八: 第5行第A列的值是dddd: 第5行第B列的值是fd: 第5行第C列的值是None: 第5行第D列的值是None: 第5行第E列的值是虽: 第5行第F列的值是影响力: <generator object _cells_by_row at 0x10cfaef00> <generator object _cells_by_col at 0x10cfaef00> 6 5 sheet-test2 <generator object values at 0x10cfaef00>
Cell属性
column:所在列,起始为1
row:所在行,起始为1
coordinate: 所在坐标,如'A1'
parent: 所属的WorkSheet
value: 单元格的值
表格如下:
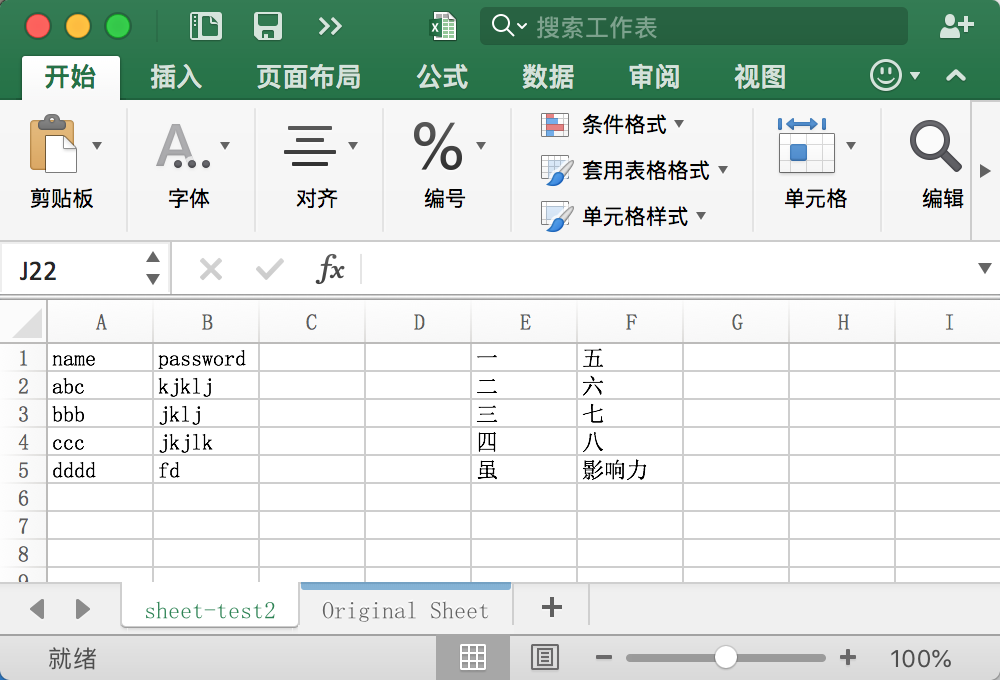
file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) ws = wb.active c1=ws['C7'] c1.value=300 print c1.row print c1.column print c1.coordinate print c1.parent c2=ws.cell(row=10,column=1,value=10) print c2.value wb.save(file_name)
执行结果:
7 C C7 <Worksheet "sheet-test2"> 10
如何操作Workbook中的数据?
file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) #直接通过worksheet中单元格的位置来获取单元格的值: ws=wb['sheet-test2'] a = ws["A3"] print a.value #对单元格赋值或者修改单元格原有的值 ws["A4"] = "123" print ws["A4"].value #通过cell属性操作单元格 b = ws.cell(row=6, column=1,value=100) print b.value
执行结果:

如何一次性读取很多单元格组成的块的数据呢?
file_name='/Users/chichi/Documents/TestStudy/test.xlsx' wb=load_workbook(file_name) ws = wb.active #通过索引切片的方式来获取一组单元格的数据 cell_range = ws["A1":"C3"] for i in cell_range: for j in i: print j.value # 针对列的切片 cell_range = ws["A":"B"] print "A列至B列的数据如下:" for i in cell_range: for j in i: print j.value # 针对行的切片 cell_range = ws["1":"2"] print "第1行至第2行的数据如下:" for i in cell_range: for j in i: print j.value # 针对worksheet提供了iter_rows方法来获取一组单元格 for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): for cell in row: print cell.value
参考:https://www.missshi.cn/api/view/blog/5a001868e519f50d04000350
https://www.jianshu.com/p/ce2ba7caa414
http://blog.topspeedsnail.com/archives/5404

 浙公网安备 33010602011771号
浙公网安备 33010602011771号