28.ElasticSearch进阶
两种查询方式
这两种方式的结果都是一样的,实际使用中我们都是使用第二种方式。
在将所有的检索条件全部放在url里
GET /bank/_search?q=*&sort=account_number:asc 表示在banK索引下查询所有文档根据account_number正序
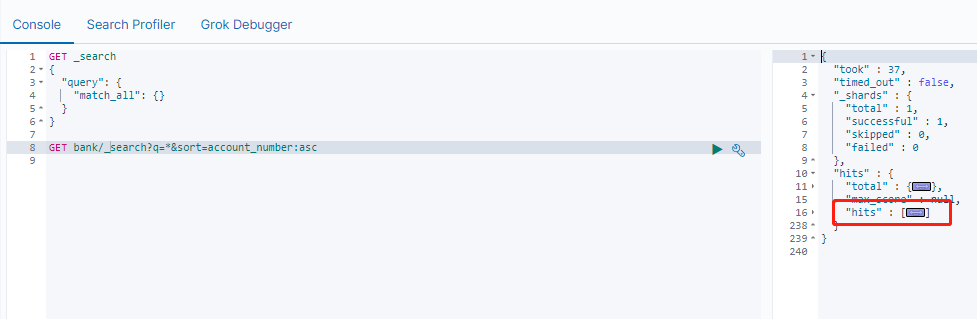
hits里有10条数据,总数是1000,可以看出ES默认做了分页。
在将所有的检索条件全部放在请求体里
GET /bank/_search { "query":{"match_all": {}}, "sort": [ { "account_number": "asc" } ] }
如果我们希望根据account_number正序排列后,如果account_number相同再根据balance倒序排列怎么实现:
GET /bank/_search { "query":{"match_all": {}}, "sort": [ { "account_number": "asc" }, { "balance": "desc" } ] }
QueryDSL基本使用
上述的第二种查询方式就属于QueryDSL的方式,我们实际项目中也都是使用QueryDSL这个方式来做查询。
基本用法
GET /bank/_search { "query":{"match": {
"account_number":20
}}, "sort": [ { "account_number": "asc" }, { "balance": "desc" } ], "from":0, "size":20,
"_source":["balance","firstname"]
}
query表示where条件
sort表示orderby排序
from表示分页的pageIndex,跟pageIndex不同的是from是从0开始的
size表示分页的pageSize
_source可以声明我们要查询的文档的字段,避免了SELECT *

match全文检索
GET /bank/_search { "query":{"match": { "address":"mill lane" }} }
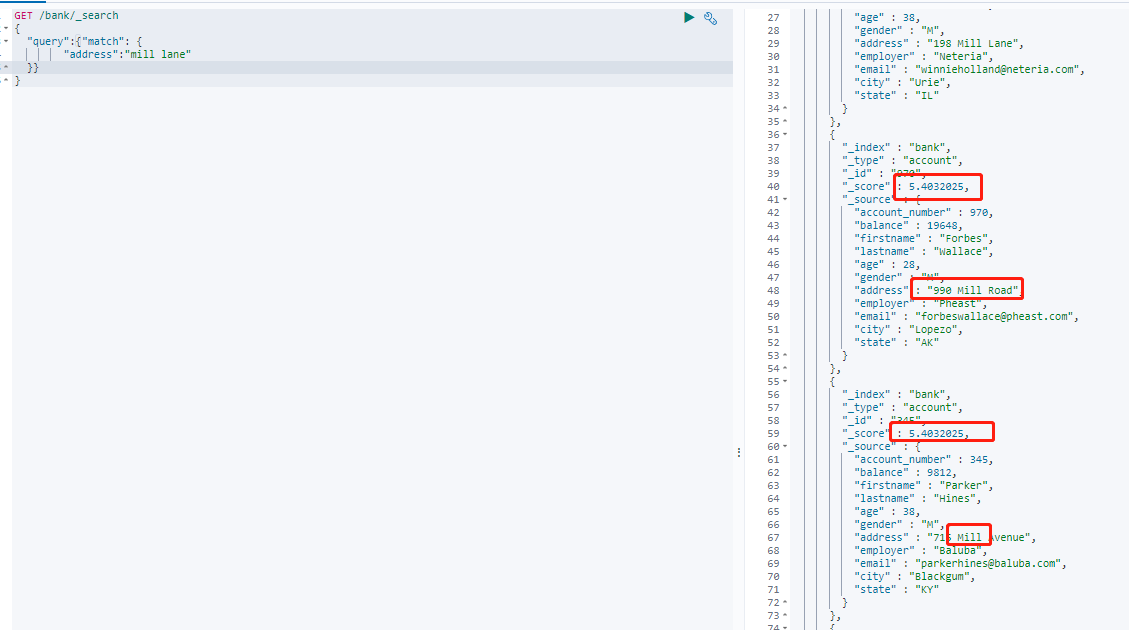
会对检索条件进行分词和存储的文档的倒排索引进行分词匹配检索,会按照相关性得分排序。
match_phrase短语匹配
GET /bank/_search { "query":{"match_phrase": { "address":"mill lane" }} }
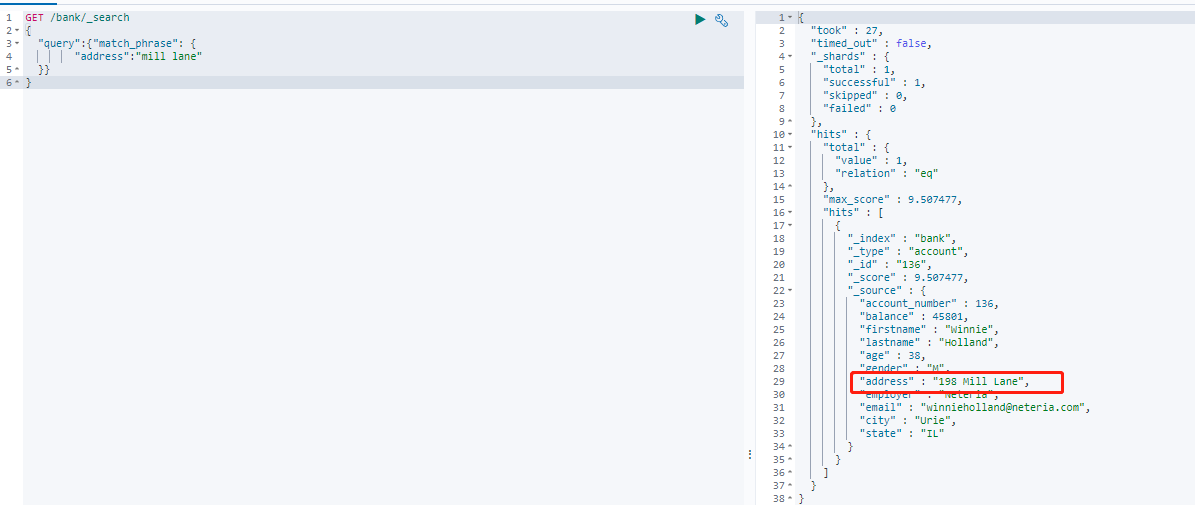
只查到一条记录,match_phrase就不会对检索的条件进行分词了,mill lane不会分词成mill和lane。
multi_match多字段匹配
GET /bank/_search { "query":{"mutil_match": { "query":"mill movico",
"fields":["address","city"] }} }
这个语句相当于MySql的: address like '%mill%' or address like '%movico%' or city like '%mill%' or city like '%movico%' ,当然不同的地方是ES是根据分词来做匹配的。
bool复合查询
GET /bank/_search { "query":{ "bool":{ "must": [ {"match": { "address": "mill" }}, { "match": { "gender": "M" } } ], "must_not": [ {"match": { "age": "28" }} ], "should": [ {"match": { "lastname": "Hines" }} ] } } }
这个语句相当于MySql的:
address='mill' and gender='M' and age<>28
然后根据lastname是否匹配Hines,匹配则相关性得分越高
filter结果过滤
filter用法与must一样,但是也有区别,区别在于:
must过滤出来的数据有相关性得分,filter过滤出来的数据相关性得分为0。
term
非文本类型字段我们一般使用term,文本字段一般使用match匹配。
非文本字段用term的原因是我们希望age检索28就只搜索28岁的数据,而不希望给128,280岁的都检索出来。
GET /bank/_search { "query":{ "term":{ "age":28 } } }
.keyword精确匹配
我们知道match是分词匹配,match_phrase是不分词like。
而.keyword就是精确匹配,比如我们要检索address='aaa'的:
GET /bank/_search { "query":{ "match":{ "address.keyword":"aaa" } } }
aggregations聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于MYSQL的GROUP BY和SQL 聚合函数。
例1
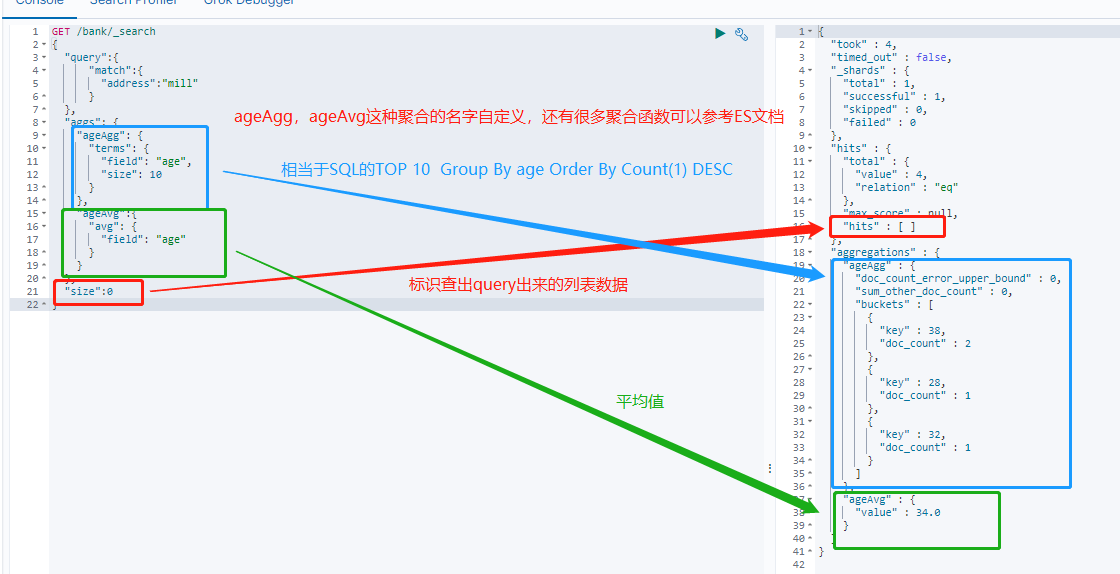
搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情:
GET /bank/_search { "query":{ "match":{ "address":"mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg":{ "avg": { "field": "age" } } }, "size":0 }
例2
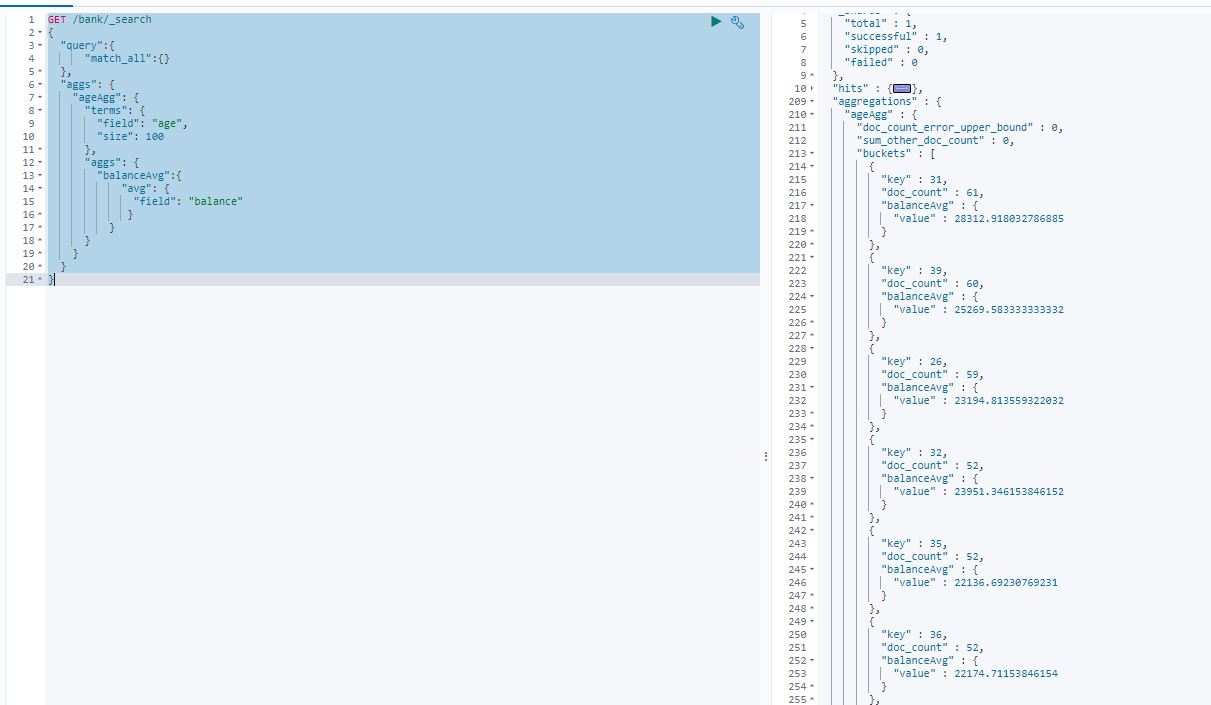
按照年龄聚合,并且计算这些每个年龄组的人的平均工资:
GET /bank/_search { "query":{ "match_all":{} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "balanceAvg":{ "avg": { "field": "balance" } } } } } }
例3
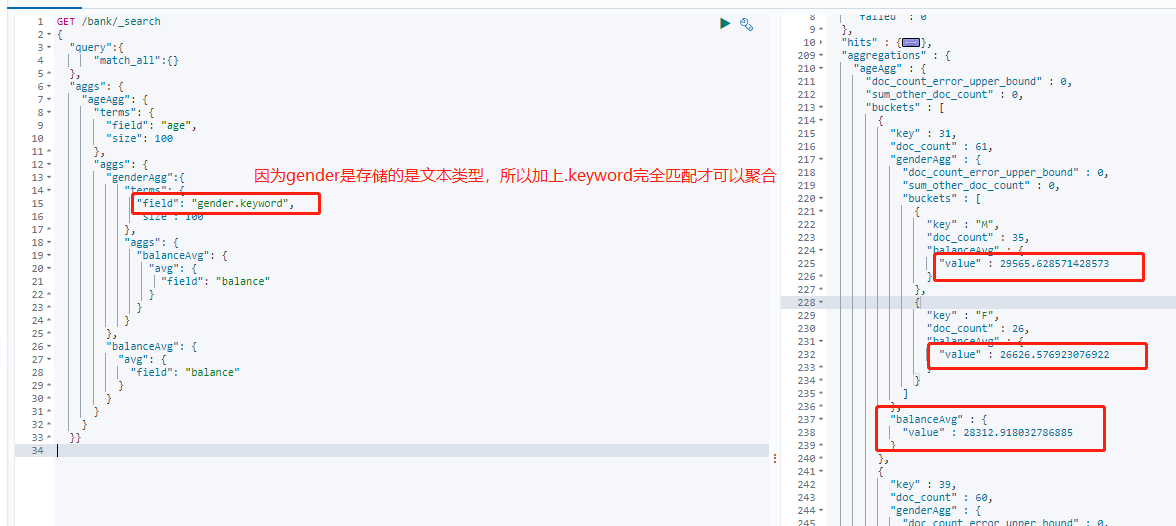
查询所有年龄分布,并且计算这些每个年龄组的男性平均工资和女性平均工资以及总平均工资:
GET /bank/_search { "query":{ "match_all":{} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "genderAgg":{ "terms": { "field": "gender.keyword", "size": 100 }, "aggs": { "balanceAvg": { "avg": { "field": "balance" } } } }, "balanceAvg": { "avg": { "field": "balance" } } } } } }
mapping映射
文档的字段映射数据类型,可以理解为MySql的字段的数据类型。
前面说了,索引下面是类型,类型下面是文档,ES在6.0版本开始去除了类型,索引下面直接是文档,去除的类型与MySql的表同级,不是数据类型,不要理解错了。
我们查一下样本数据里映射的字段的数据类型:
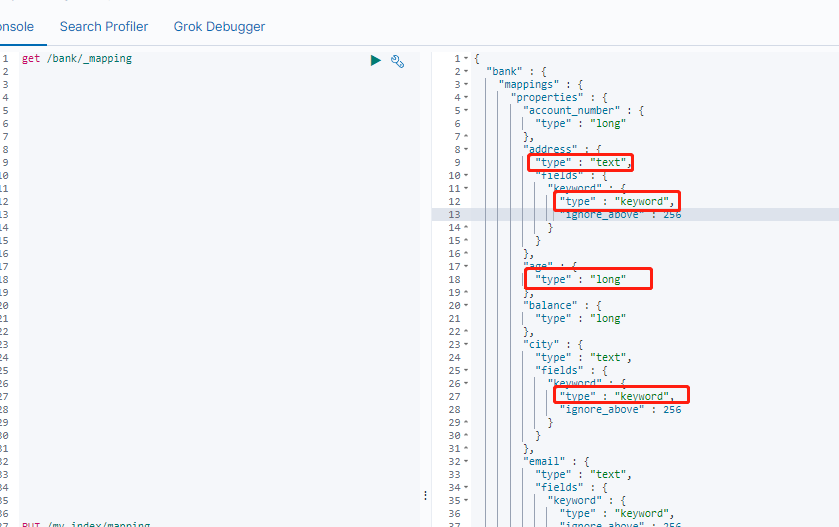
第一次写入数据到文档时候,ES会根据数据推断出数据类型,我们也可以指定数据类型,即创建映射。
创建映射
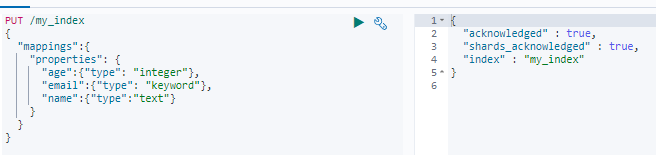
创建一个索引my_index并创建映射,type同级还可以加一个index,取值为true,false,不写默认为true,表示是否可以作为检索条件。
添加一个映射的字段

给my_index索引添加了一个字段employee-id,且该字段不可以作为检索条件
修改映射
已存在的映射字段无法修改,要想修改只能常见新的索引进行数据迁移。
数据迁移
1.先查一下bank索引的映射
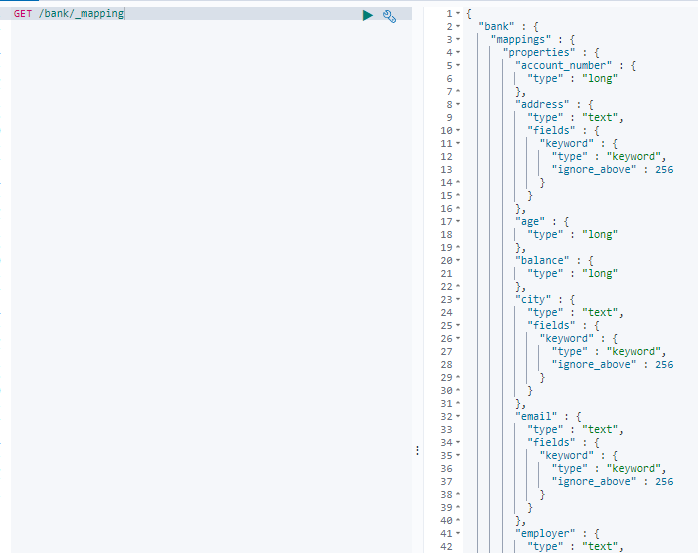
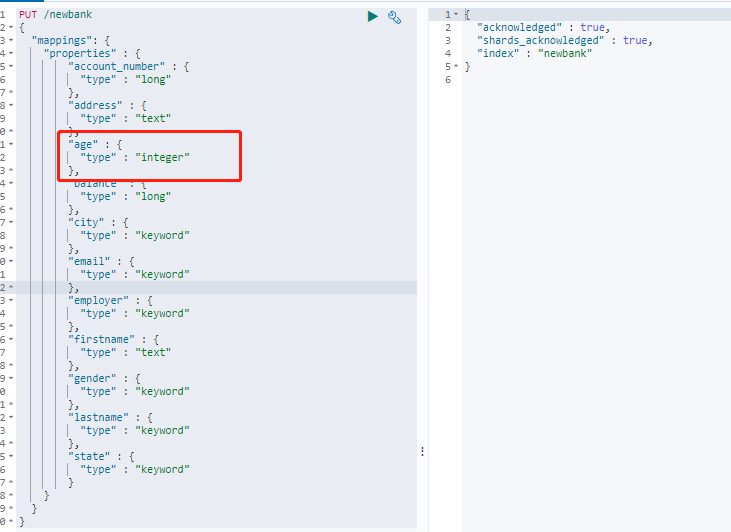
2.创建一个新的索引newbank,并指定映射关系,其中age不适用bank索引的long类型,改为integer
3.迁移数据,bank的数据迁移到newbank
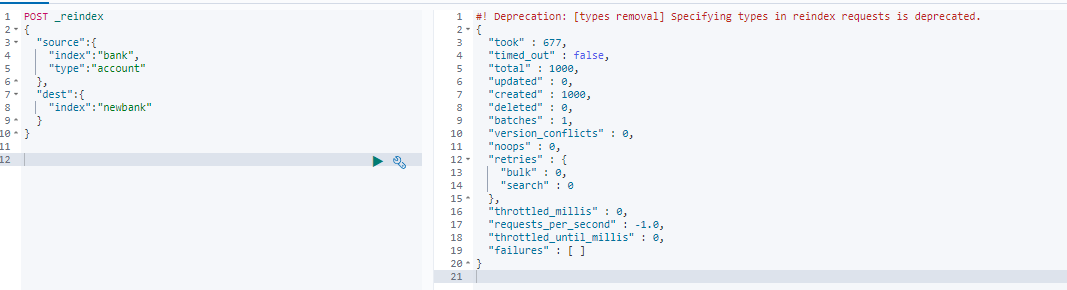
由于bank用的是6.0版本以前的,使用了类型,所以迁移需要指定type,如果6.0版本后不使用类型的索引迁移就不需要指定type了。
4.查一下迁移后的索引下的数据
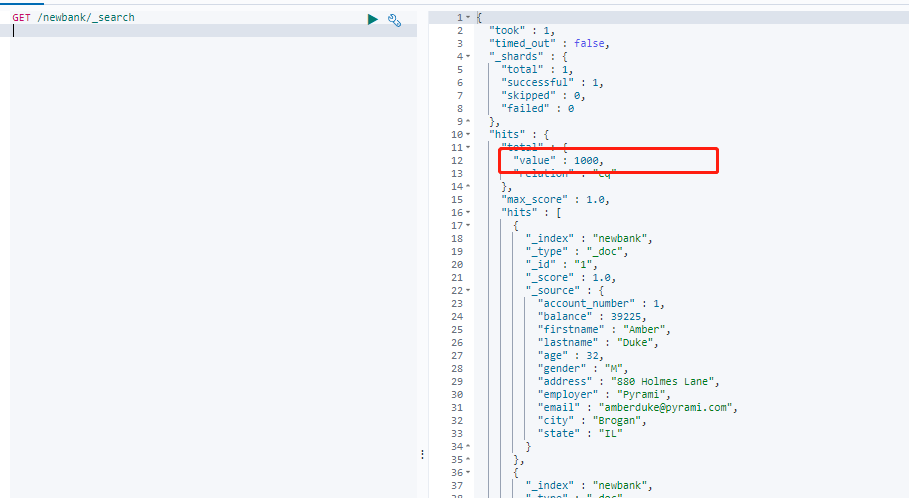
1000条数据,和bank索引下的数据一直,没问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号