学习笔记-volatile关键字
本文内容源于视频教程,若有侵权,请联系作者删除
一、概念
先看一个例子
1 public class VolatileDemo { 2 3 public static boolean stop = false; 4 5 public static void main(String[] args) throws InterruptedException { 6 Thread thread = new Thread(() -> { 7 int i = 0; 8 while (!stop) { 9 i++; 10 } 11 }); 12 thread.start(); 13 Thread.sleep(10); 14 stop = true; 15 } 16 }
上面的程序会一直运行,并不会因为主线程中修改了stop的值而跳出循环。而在stop变量加上volatile关键字之后程序会立马结束,这就是volatile的第一个作用:保证可见性,它还有另一个功能——防止指令重排序。下面一一道来。
二、JMM
JMM(Java Memory Model)是一种抽象内存模型,它定义了共享内存中多线程程序读写共享变量规范,即把变量存储到内存以及从内存中取出的底层实现细节。
JMM 抽象模型分为主内存、工作内存;主内存是所有线程共享的,一般是实例对象、静态字段、数组对象等存储在堆内存中的变量。工作内存是每个线程独占的,线程对变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量,线程之间的共享变量值的传递都是基于主内存来完成 。
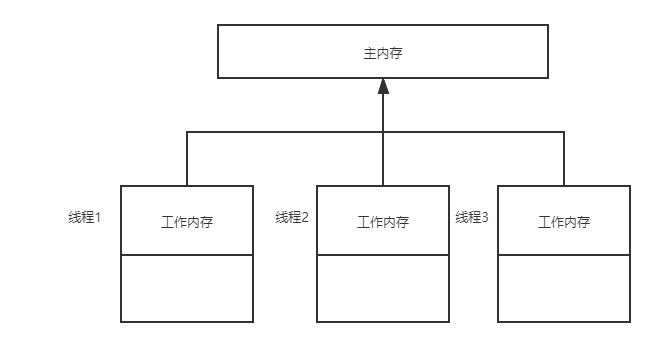
讲到JMM,这里得提一下硬件模型,可移步至3
而JMM存在两个问题
1.可见性问题:多个工作内存同时存储同一变量,当某个线程修改变量值时,会先修改当先当前线程工作内存中变量值,然后写回到主内存中。当其他线程访问该变量时会出现变量不一致问题。
2.有序性问题:为了提高程序的执行性能,编译器和处理器都会对指令做重排序,在单线程下不会出现问题,但是在多线程情况下可能导致计算结果与预期不一致。
volatile解决可见性和有序性的本质是通过内存屏障来实现,简单来说,内存屏障不仅能限制编译器做指令重排序优化,还具备刷新缓存的功能。
volatile内存语义
当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量值刷新到主内存
当读一个 volatile 变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
2.1 内存屏障
八种原子操作指令:
- read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用;
- load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中;
- use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作;
- assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作;
- store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用;
- write(写入):作用于主内存,它把store传送值放到主内存中的变量中;
- lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态;
- unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定;
| 屏障类型 | 指令示例 | 备注 |
| LoadLoadBarriers | load1,loadload,load2 | 确保load1数据的装载优先于load2及所有后续装载指令的装载 |
| StoreStoreBarriers | store1,storestore,store2 | 确保store1数据对其他处理器可见优先于store2及所有后续存储指令的存储 |
| LoadStoreBarriers | load1,loadstore,store2 | 确保load1数据装载优先于store2及后续存储指令的存储 |
| StoreLoadBarriers | store1,storeload,load2 |
确保store1数据对其他处理器可见优先于load2及所有后续指令的装载 |
volatile实现原理
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
2.2 指令重排序
简单来说,指令重排序是为了提高程序执行性能,在不影响单线程执行结果的条件下,优化指令的执行顺序。
从源代码到最终执行的指令,可能会经过三种重排序

2 和 3 属于处理器重排序。这些重排序可能会导致可见性问题。
2.2.1 as-if-serial
虽然编译器和cpu优化指令执行顺序,但必须保证在单线程下执行结果一致,这就是as-if-serial规则。
如:a=1;a=2; 这种情况下如果交换第二句和第三句会导致执行结果不一致,因此这种情况下不会重排序。
2.2.1 happens-before
happens-before表示在多线程中,只要满足一定规则,那么前一个操作的结果对于后一个操作是可见的。
happens-before规则如下:
1.volatile 变量规则,对一个volatile域的写,happens-before于任意后续对这个volatile域的读
2.传递性规则,如果 1 happens-before 2,2happens-before 3 ,那么1happens-before3
3.Join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回
4.监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁
5.对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。
6.程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
三、计算机内存模型
计算机的核心组件包括CPU,内存,和IO设备,随着时代发展,设备也在不断更新换代,如CPU从单核到多核,内存从1G到8G再到16G不等,硬盘由机械转为固态。然而不管怎么变化,一直都存在这一个问题:就是这三者之间计算速度的差异,CPU速度最快,内存次之,IO设备最慢。为了解决CPU和内存之间速度不匹配的问题引入了高速缓存,当CPU需要从内存中读取数据时,不必从内存中直接读取,只需要从高速缓存中读取已备份好的数据,当CPU写数据到内存时,也是现将数据同步到高速缓存,然后同步到内存,大大增加了CPU的利用率。
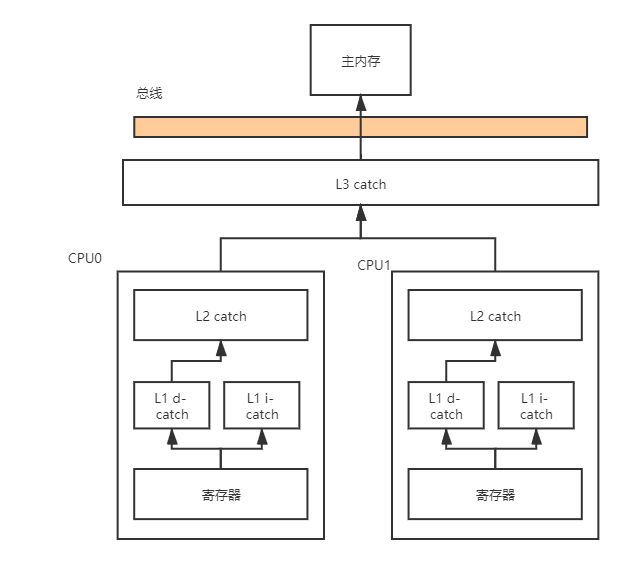
然而,高速缓存的引入带了新的问题:缓存一致性,每个CPU都有各自的缓存,这意味着当一个线程修改CPU0缓存中的数据并且此时并未同步到主内存中,另外一个线程读取了CPU1中当前变量的值时,拿到的是脏数据。为解决此问题,引入了两种解决方案,总线索和缓存锁。
总线锁:在CPU情况下,当其中一个线程操作共享变量时,在总线上发出一个 LOCK#信号,其他线程都无法访问内存中的数据,这种方法开销较大
缓存锁:缓存锁把锁的粒度控制到了变量级别,基于缓存一致性协议实现的。
3.1 缓存锁
3.1.1 MESI
MESI是一种缓存一致性协议,常见的还有MSI,MOSI等。
缓存一致性协议通过对读和写缓存的操作,以此解决缓存不一致问题。
在MESI协议中,每个缓存的缓存控制器不仅知道自己的读写操作,而且也监听(snoop)其它Cache的读写操作。
| 状态 | 描述 | 监听任务 | 当前CPU读请求 | 当前CPU写请求 |
| M(Modify)修改 |
数据只缓存在当前 CPU 缓存中,并且是被修改状态, 也就是缓存的数据和主内存中的数据不一致 |
缓存行必须时刻监听所有试图读该缓存行相对应的内存的操作,其他缓存须在本缓存行 写回内存并将状态置为E之后才能操作该缓存行对应的内存数据 |
可读 |
可写 |
| E(Exclusive)独占 | 数据只缓存在当前CPU 缓存中,并且没有被修改 |
缓存行必须监听其他缓存读主内存中该缓存行相对应的内存的操作,一旦有这种操作, 该缓存行需要变成S状态 |
可读 |
可写 |
| S(Share)共享 | 数据可能被多个 CPU 缓存,且各个缓存中的数据和主内存数据一致 | 缓存行必须监听其他缓存是该缓存行无效或者独享该缓存行的请求,并将该缓存行置为I状态 | 可读 | 需要先将其他CPU中缓存置为无效才可写 |
| I(Invalid)无效 | 数据已失效 | 无 | 需要从主内存读取 | 不可写(实际上可写,但不生效) |
通过MESI协议既能保证在读取缓存数据时不会读到脏数据,又能保证写缓存数据时数据的有效性及对其他CPU的可见性。但仍存在效率问题:
当多个CPU缓存相同数据,且与主内存保持一致(及此时各CPU中缓存行状态都为S),当其中一个CPU修改共享数据时,需要将其他所有CPU中该缓存置为无效,等到收到所有CPU置为无效的结果后才能执行写操作。而在此期间该CPU一直处于阻塞状态,导致APU资源浪费。
为解决上述问题,在CPU中引入了Store Buffers。具体的实现为:在写数据时先把数据写到Store Buffers中,继续处理其他事情,当收到其他所有CPU的返回结果后写到缓存中,然后同步到主内存(其实就是做了异步操作)。
由于引入Store Buffers之后其实是做了异步操作,那么又带来的新的问题:
1 value=3; 2 void exeCpu0(){ 3 value = 10; 4 isFinish = true; 5 } 6 void exeCpu1(){ 7 if(isFinish){ 8 assert value == 10 9 } 10 }
假设value在CPU0和1中是S状态,isFinish在CPU0是E状态。预期的assert value == 10的结果为true,但实际上可能为false,理由如下:
CPU0在执行value = 10;时,由于value是S状态,此时CPU0会把value=10存入Store Buffers并且通知CPU1将value置为E状态,然后执行isFinish = true,由于isFinish是E状态,所以可以立刻修改该值。此时如果CPU1还没有返回执行结果且执行了exeCpu1方法就会导致返回结果与预期不一致问题。因此引入了一个新的概念:CPU层面内存屏障,它包含以下内容
| 屏障类型 | 描述 |
| Store Memory Barrier(写屏障) | 写屏障之前的所有已经存储在存储缓存(store bufferes)中的数据同步到主内存 |
| Load Memory Barrier(读屏障) | 处理器在读屏障之后的读操作,都在读屏障之后执行。配合写屏障,使得写屏障之前的内存更新对于读屏障之后的读操作是可见的 |
| Full Memory Barrier(全屏障) | 确保屏障前的内存读写操作的结果提交到内存之后,再执行屏障后的读写操作 |
此时上面问题可以通过如下方式解决。
1 { 2 value=3; 3 void exeCpu0(){ 4 value = 10; 5 StoreMemoryBarrier(); 6 isFinish = true; 7 } 8 void exeCpu1(){ 9 if(isFinish){ 10 LoadMemoryBarrier(); 11 assert value == 10 12 } 13 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号