

Java程序线上故障排查
这篇文章是在公司做了不少的线上Java服务故障排查和优化之后的一个总结,可以作为一个工具清单,在分析问题的时候需要有整体思路:全局观,先从系统层面入手,大致定位方向(内存,cpu,磁盘,网络),然后再去分析具体的进程。
一、Linux
内存和cpu
内存和cpu问题是出问题最多的一个点,因为有些命令如top同时可以观察到内存和cpu所以放在一起。
top命令
常用参数: -H 打印具体的线程, -p 打印某个进程 进入后 按数字1 可以切换cpu的图形看有几个核
下面是我的测试环境shell:
top - 14:28:49 up 7 min, 3 users, load average: 0.08, 0.26, 0.19
Tasks: 221 total, 2 running, 219 sleeping, 0 stopped, 0 zombie
%Cpu(s): 5.1 us, 3.4 sy, 0.0 ni, 91.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 985856 total, 81736 free, 646360 used, 257760 buff/cache
KiB Swap: 2094076 total, 1915196 free, 178880 used. 141592 avail Mem
我一般重点关注的指标有:
%Cpu(s): 5.1 us, 3.4 sy, 0.0 wa
这里可以非常直观的看到当前cpu的负载情况,us用户cpu占用时间,sy是系统调用cpu占用时间,wa是cpu等待io的时间,前面两个比较直观,但是第三个其实也很重要,如果wa很高,那么你就该重点关注下磁盘的负载了,尤其是像mysql这种服务器。
load average: 0.08, 0.26, 0.19
cpu任务队列的负载,这个队列包括正在运行的任务和等待运行的任务,三个数字分别是1分钟、5分钟和15分钟的平均值。这个和cpu占用率一般是正相关的,反应的是用户代码,如果超过了内核数,表示系统已经过载。也就是说如果你是8核,那么这个数字小于等于8的负载都是没问题的,我看网上的建议一般这个值不要超过ncpu*2-2为好。
KiB Mem : 985856 total, 81736 free, 646360 used, 257760 buff/cache
内存占用情况,total总内存,free空余内存, used已经分配内存,buff/cache块设备和缓冲区占用的内存,因为Linux的内存分配,如果有剩余内存,他就会将内存用于cache,这样可以较少磁盘的读写提高效率,如果有应用申请内存,buff/cache这部分内存也是可用的,所以正真的剩余内存应该是free+buff/cache
swap
线上服务器一般都是禁用状态,所以不用看这项。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
这一栏主要是看进程的详情,重点是%CPU %MEM,上面看的是整个服务器的负载,这里是每个进程的负载。还有看看S这个指标,这个代码了进程的状态,有时候有些进程会出现T(暂停)这个状态。
网络
ss
netstat的高性能版,参数都基本一致
常用参数: -n 打印数字端口号 -t tcp连接 -l 监听端口 -a 所有端口 -p 进程号 -s 打印统计信息
ss -s示例:
Total: 1732 (kernel 1987)
TCP: 42373 (estab 1430, closed 40910, orphaned 2, synrecv 0, timewait 40906/0), ports 1924
Transport Total IP IPv6
* 1987 - -
RAW 18 9 9
UDP 18 11 7
TCP 1463 503 960
可以看到整体的连接情况,如timewait过高,连接数过高等情况
然后使用ss -ntap|grep 进程号 or 端口号 查看进程的连接
ping
查看时延和丢包情况
mtr
查看丢包请求
磁盘
磁盘问题在mysql服务器中非常常见,很多时候mysql服务器的CPU不高但是却出现慢查询日志飙升,就是因为磁盘出现了瓶颈。还有mysql的备份策略,如果没有监控磁盘空间,可能出现磁盘满了服务不可用的现象。
**iostat命令 **
常用参数: -k 用kb为单位 -d 监控磁盘 -x显示详情 num count 每个几秒刷新 显示次数
这个是我查看磁盘负载的主要工具,也可以显示cpu的负载,不过我一般用iostat -kdx 2 10,下面是我测试环境执行情况:
root@ubuntu:~# iostat -kdx 2 10
Linux 4.13.0-38-generic (ubuntu) 11/18/2018 _x86_64_ (1 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 24.75 196.05 121.66 9.75 2481.33 961.29 52.40 0.44 3.33 1.12 30.95 0.51 6.71
scd0 0.00 0.00 0.02 0.00 0.08 0.00 7.00 0.00 0.25 0.25 0.00 0.25 0.00
我一般重点关注的指标有:
- rkB/s和wkB/s: 分别对应读写速度
- avgqu-sz: 读写队列的平均请求长度,可以类比top命令的load average
- await r_await w_await: io请求的平均时间(毫秒),分别是读写,读和写三个平均值。这个时间都包括在队列中等待的时间和实际处理读写请求的时间,还有svctm这个参数,他说的是实际处理读写请求的时间,照理来讲w_await肯定是大于svctm的,但是我在线上看到有w_await小于svctm的情况,不知道是什么原因。我看iostat的man手动中说svctm已经废弃,所以一般我看的是这三个。
- %util: 这个参数直观的看磁盘的负载情况,我首先看的就是这个参数。和top的wa命令有关联。
df
查看文件系统的容量
常用参数: -h 友好的单位 如Kb,Mb等
du
统计具体的文件大小
常用参数: -h 友好的单位 如Kb,Mb等 -s 总计,而不是进入每个子目录分别统计
场景:例如系统磁盘空间不足时,先通过df命令定位到具体的挂载目录,在进去挂载目录后,使用
du -sh *查看各个文件或者子目录的大小定位具体文件
这里还有ls命令,可以通过加-h和-S(按大小排序)
iostat命令
常用参数: -k 用kb为单位 -d 监控磁盘 -x显示详情 num count 每个几秒刷新 显示次数
这个是我查看磁盘负载的主要工具,也可以显示cpu的负载,不过我一般用iostat -kdx 2 10,下面是我测试环境执行情况:
root@ubuntu:~# iostat -kdx 2 10
Linux 4.13.0-38-generic (ubuntu) 11/18/2018 _x86_64_ (1 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 24.75 196.05 121.66 9.75 2481.33 961.29 52.40 0.44 3.33 1.12 30.95 0.51 6.71
scd0 0.00 0.00 0.02 0.00 0.08 0.00 7.00 0.00 0.25 0.25 0.00 0.25 0.00
我一般重点关注的指标有:
- rkB/s和wkB/s: 分别对应读写速度
- avgqu-sz: 读写队列的平均请求长度,可以类比top命令的load average
- await r_await w_await: io请求的平均时间(毫秒),分别是读写,读和写三个平均值。这个时间都包括在队列中等待的时间和实际处理读写请求的时间,还有svctm这个参数,他说的是实际处理读写请求的时间,照理来讲w_await肯定是大于svctm的,但是我在线上看到有w_await小于svctm的情况,不知道是什么原因。我看iostat的man手动中说svctm已经废弃,所以一般我看的是这三个。
- %util: 这个参数直观的看磁盘的负载情况,我首先看的就是这个参数。和top的wa命令有关联。
lsof
列出当前系统打开文件,因为在linux下一切皆是文件,连接,硬件等均被描述为文件,所以这个命令也十分有用。
常用参数:
- -p 查看某个进程的文件
- 直接加文件名 查看哪些进程打开了文件
- +d 目录 查看哪些进程打开了目录以及下面的文件(不递归,+D是递归)
Sar
最后补充一个sar(System Activity Reporter)命令,如果系统没有一个良好的监控,那么这个命令对于排查问题是很好的补充,很多时候去排查问题的时候发现问题已经没了,可以通过这个命令查看系统的活动情况,比如各个时间段cpu情况,内存情况。
常用参数:
- -r 内存信息
- -q loader信息,运行队列情况
- -u cpu信息
- -W Swap换页情况
/proc文件系统
/proc是个虚拟文件系统,是内核的一些数据,很多linux命令的都是通过解析/proc文件系统实现的,每个进程都会有一个以pid为目录名的子目录存在,通过解析/proc下的进程目录可以得到很多进程的设置信息和资源占用信息等。
这里简单说个排查过的问题,当时我们线上有个服务,正常ssh登录的情况下,我们设置了ulimit中的open files为(进程可打开的最大描述符数量)100000,但是有一次在服务的日志中发现有报错说文件描述符不够用。所以
二、JVM
java -XX:+PrintFlagsInitial 可以查看所以的jvm默认参数,其中带有manageable表示运行时可以动态修改。
20:45 [root@centos]$ java -XX:+PrintFlagsInitial |grep manageable
intx CMSAbortablePrecleanWaitMillis = 100 {manageable}
intx CMSTriggerInterval = -1 {manageable}
intx CMSWaitDuration = 2000 {manageable}
bool HeapDumpAfterFullGC = false {manageable}
bool HeapDumpBeforeFullGC = false {manageable}
bool HeapDumpOnOutOfMemoryError = false {manageable}
ccstr HeapDumpPath = {manageable}
uintx MaxHeapFreeRatio = 70 {manageable}
uintx MinHeapFreeRatio = 40 {manageable}
bool PrintClassHistogram = false {manageable}
bool PrintClassHistogramAfterFullGC = false {manageable}
bool PrintClassHistogramBeforeFullGC = false {manageable}
bool PrintConcurrentLocks = false {manageable}
bool PrintGC = false {manageable}
bool PrintGCDateStamps = false {manageable}
bool PrintGCDetails = false {manageable}
bool PrintGCID = false {manageable}
bool PrintGCTimeStamps = false {manageable}
Java堆和垃圾收集器
java内存结构
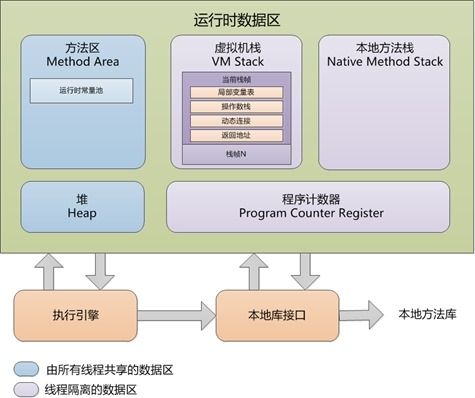
堆内存结构:
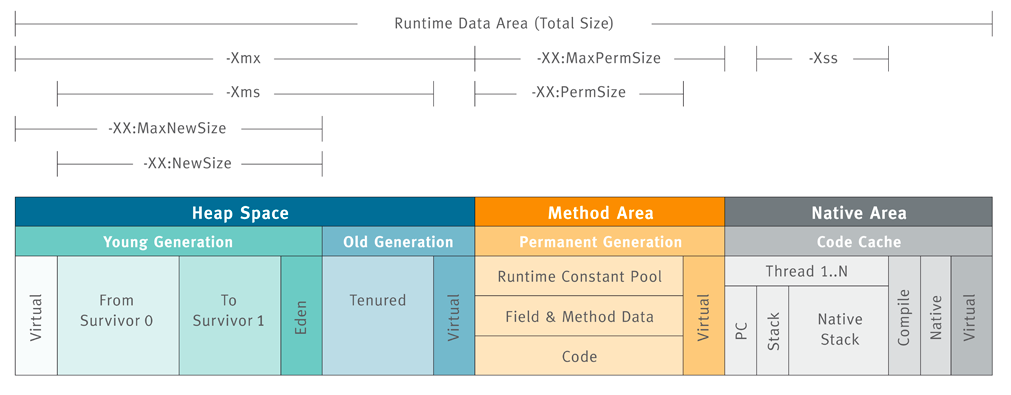
java8元空间改动:
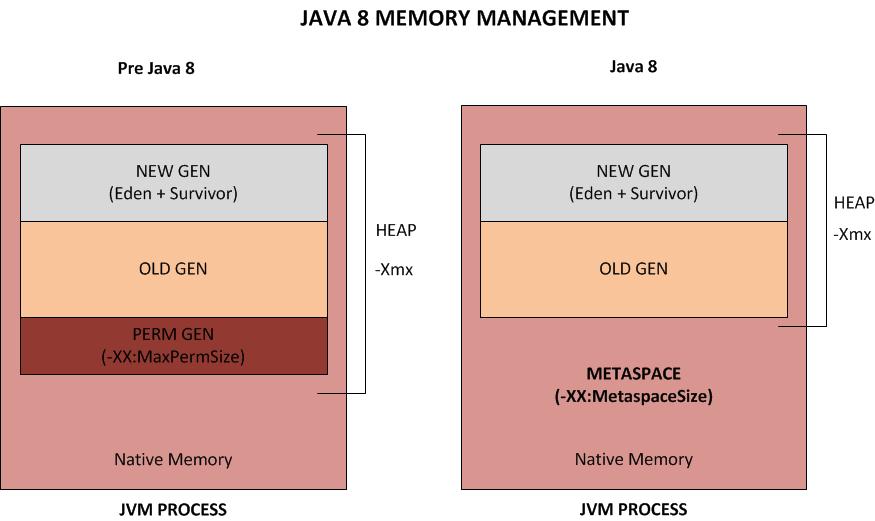
java 7种垃圾收集器:
常见搭配:
- java8默认:Parallel Scavenge和 Parallel Old
- 低延迟:ParNew和CMS
- java8以后可以直接使用G1,参数比较简单
ParNew
Serial的并行版本
Parallel Scavenge
注重的是吞吐量,吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),其具有自适应的特性
-
控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis参数
MaxGCPauseMillis参数允许的值是一个大于0的毫秒数,收集器将尽力保证内存回收花费的时间不超过设定值。不过大家不要异想天开地认为如果把这个参数的值设置得稍小一点就能使得系统的垃圾收集速度变得更快,GC停顿时间缩短是以牺牲吞吐量和新生代空间来换取的:系统把新生代调小一些,收集300MB新生代肯定比收集500MB快吧,这也直接导致垃圾收集发生得更频繁一些,原来10秒收集一次、每次停顿100毫秒,现在变成5秒收集一次、每次停顿70毫秒。停顿时间的确在下降,但吞吐量也降下来了。 -
直接设置吞吐量大小的 -XX:GCTimeRatio参数
GCTimeRatio参数的值应当是一个大于0小于100的整数,也就是垃圾收集时间占总时间的比率。如果把此参数设置为19,那允许的最大GC时间就占总时间的5%(即1 /(1+19)),默认值为99,就是允许最大1%(即1 /(1+99))的垃圾收集时间。 -
UseAdaptiveSizePolicy开关参数
-XX:+UseAdaptiveSizePolicy是一个开关参数,当这个参数打开之后,就不需要手工指定新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomics)。
说说UseAdaptiveSizePolicy参数,加了这个参数-XX:SurvivorRatio会失效,所以有些人会发现新生代比例未如自己的预期,而UseAdaptiveSizePolicy有默认是开启的
CMS
并发垃圾收集器,注重的是时延,有分配担保失败的风险
CMS收集器的GC周期由6个阶段组成。其中4个阶段(名字以Concurrent开始的)与实际的应用程序是并发执行的,而其他2个阶段需要暂停应用程序线程。
初始标记:为了收集应用程序的对象引用需要暂停应用程序线程,该阶段完成后,应用程序线程再次启动。
并发标记:从第一阶段收集到的对象引用开始,遍历所有其他的对象引用。
并发预清理:改变当运行第二阶段时,由应用程序线程产生的对象引用,以更新第二阶段的结果。
重标记:由于第三阶段是并发的,对象引用可能会发生进一步改变。因此,应用程序线程会再一次被暂停以更新这些变化,并且在进行实际的清理之前确保一个正确的对象引用视图。这一阶段十分重要,因为必须避免收集到仍被引用的对象。
并发清理:所有不再被应用的对象将从堆里清除掉。
并发重置:收集器做一些收尾的工作,以便下一次GC周期能有一个干净的状态。
- -XX:CMSInitiatingOccupancyFraction=90 (jdk1.5默认值68,1.6开始默认值92,指设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)
- -XX:+UseCMSInitiatingOccupancyOnly 只是用设定的回收阈值(上面指定的70%),如果不指定,JVM仅在第一次使用设定值,后续则自动调整
- -XX:+CMSScavengeBeforeRemark 在CMS GC前启动一次ygc,目的在于减少old gen对ygc gen的引用,降低remark时的开销
- -XX:+CMSParallelRemarkEnabled 并发标记
- -XX:+ExplicitGCInvokesConcurrent命令JVM无论什么时候调用系统GC(system.gc()),都执行CMS GC,而不是Full GC
- -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses保证当有系统GC调用时,永久代也被包括进CMS垃圾回收的范围内
- -XX:UseParNewGC 使用CMS时自动开启,因为CMS不能和Parallel Scavenge搭配使用
上面的参数都建议开启,CMS需要注意的一个问题就是CMSInitiatingOccupancyFraction参数,这个参数直接影响CMS回收老年代的时机,需要结合自己的业务场景来调整,一般情况下应该尽量设置大一点,但是有一个严重的问题,就是浮动垃圾的问题,如果CMS在并发收集的时候出现老年代不能存放晋升对象将直接进行Full GC使用Serial Old垃圾收集器,所以不能一味追求最大化,如果老年代增长比较慢,那么可以设置的稍微较大些,如果增长比较快,可以从增大新生代,调低CMSInitiatingOccupancyFraction入手
最后在提下-XX:+DisableExplicitGC :禁用显示gc (system.gc())这个参数,很多人因为system.gc()会导致Full gc而禁用显示调用gc,但是这个参数最好不要禁用,现在很多服务端程序都使用了Nio,jvm为了减少内存拷贝,采用了直接内存,直接内存属于堆外内存,java大多使用了Netty这个框架,他帮我们处理堆外内存的回收,实现的机制就是通过调用system.gc(),发起Full Gc,Full Gc会回收堆外内存,如果将system.gc()禁用,则得等到Full Gc发生才能回收堆外内存,很有可能出现堆外内存占用过高影响系统性能或者因为内存不足被系统Kill的问题。
gc日志参数
- -XX:+PrintGC 输出GC日志
- -XX:+PrintGCDetails 输出GC的详细日志
- -XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
- -XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
- -XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
- -XX:+PrintGCApplicationStoppedTime // 输出GC造成应用暂停的时间
- -Xloggc:../logs/gc.log 日志文件的输出路径
- -XX:+PrintTenuringDistribution 打印新生代的年龄分布(这里需要注意,如果使用的是Parallel Scavenge,那么打印的时候是没有年龄分布信息的)
- -XX:+UseGCLogFileRotation 开启日志轮换
- -XX:NumberOfGCLogFiles=5 日志保留数量
- -XX:GCLogFileSize=10m 每份日志保留大小
堆参数
- -Xms 最小堆大小
- -Xmx 最大堆大小
- -Xmn 新生代大小
- -XX:SurvivorRatio 新生代中Eden区与Survivor区的比例,默认值为8
gc日志分析
ParNew Gc日志:
{Heap before GC invocations=4196 (full 3):
par new generation total 1887488K, used 1683093K [0x0000000640000000, 0x00000006c0000000, 0x00000006c0000000)
eden space 1677824K, 100% used [0x0000000640000000, 0x00000006a6680000, 0x00000006a6680000)
from space 209664K, 2% used [0x00000006a6680000, 0x00000006a6ba5430, 0x00000006b3340000)
to space 209664K, 0% used [0x00000006b3340000, 0x00000006b3340000, 0x00000006c0000000)
concurrent mark-sweep generation total 4194304K, used 1565111K [0x00000006c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 59881K, capacity 64953K, committed 66588K, reserved 1107968K
class space used 6615K, capacity 7729K, committed 8224K, reserved 1048576K
2019-10-29T23:48:00.181+0800: 27966.548: [GC (Allocation Failure) 2019-10-29T23:48:00.181+0800: 27966.548: [ParNew
Desired survivor size 107347968 bytes, new threshold 15 (max 15)
- age 1: 2287832 bytes, 2287832 total
- age 2: 132752 bytes, 2420584 total
- age 3: 102408 bytes, 2522992 total
- age 4: 125768 bytes, 2648760 total
- age 5: 145464 bytes, 2794224 total
- age 6: 82808 bytes, 2877032 total
- age 7: 104736 bytes, 2981768 total
- age 8: 79216 bytes, 3060984 total
- age 9: 89496 bytes, 3150480 total
- age 10: 81864 bytes, 3232344 total
- age 11: 91304 bytes, 3323648 total
- age 12: 78912 bytes, 3402560 total
- age 13: 80960 bytes, 3483520 total
- age 14: 91560 bytes, 3575080 total
- age 15: 78992 bytes, 3654072 total
: 1683093K->5343K(1887488K), 0.0342117 secs] 3248204K->1570530K(6081792K), 0.0343754 secs] [Times: user=0.17 sys=0.01, real=0.03 secs]
Heap after GC invocations=4197 (full 3):
par new generation total 1887488K, used 5343K [0x0000000640000000, 0x00000006c0000000, 0x00000006c0000000)
eden space 1677824K, 0% used [0x0000000640000000, 0x0000000640000000, 0x00000006a6680000)
from space 209664K, 2% used [0x00000006b3340000, 0x00000006b3877f50, 0x00000006c0000000)
to space 209664K, 0% used [0x00000006a6680000, 0x00000006a6680000, 0x00000006b3340000)
concurrent mark-sweep generation total 4194304K, used 1565186K [0x00000006c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 59881K, capacity 64953K, committed 66588K, reserved 1107968K
class space used 6615K, capacity 7729K, committed 8224K, reserved 1048576K
}
gc日志中打印了新生代,老年代和元空间等内存信息,其中Times: user=0.02 sys=0.01, real=0.01 secs三个时间分别是用户态的时间,内核态的时间和墙钟时间。墙钟时间表示真正过去的时间,而用户态和内核态的时间则是乘了相应的cpu核心数。
CMS GC日志:
2019-10-29T18:03:19.578+0800: 7285.945: [GC (CMS Initial Mark) [1 CMS-initial-mark: 3182477K(4194304K)] 3254261K(6081792K), 0.0044508 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
2019-10-29T18:03:19.582+0800: 7285.949: [CMS-concurrent-mark-start]
2019-10-29T18:03:20.812+0800: 7287.179: [CMS-concurrent-mark: 1.229/1.229 secs] [Times: user=3.86 sys=0.46, real=1.23 secs]
2019-10-29T18:03:20.812+0800: 7287.179: [CMS-concurrent-preclean-start]
2019-10-29T18:03:20.823+0800: 7287.190: [CMS-concurrent-preclean: 0.011/0.011 secs] [Times: user=0.03 sys=0.01, real=0.01 secs]
2019-10-29T18:03:20.823+0800: 7287.190: [CMS-concurrent-abortable-preclean-start]
{Heap before GC invocations=896 (full 3):
par new generation total 1887488K, used 1747877K [0x0000000640000000, 0x00000006c0000000, 0x00000006c0000000)
eden space 1677824K, 100% used [0x0000000640000000, 0x00000006a6680000, 0x00000006a6680000)
from space 209664K, 33% used [0x00000006a6680000, 0x00000006aaae9780, 0x00000006b3340000)
to space 209664K, 0% used [0x00000006b3340000, 0x00000006b3340000, 0x00000006c0000000)
concurrent mark-sweep generation total 4194304K, used 3182477K [0x00000006c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 60431K, capacity 66281K, committed 66588K, reserved 1107968K
class space used 6828K, capacity 8138K, committed 8224K, reserved 1048576K
2019-10-29T18:03:25.649+0800: 7292.016: [GC (Allocation Failure) 2019-10-29T18:03:25.649+0800: 7292.016: [ParNew
Desired survivor size 107347968 bytes, new threshold 15 (max 15)
- age 1: 1362152 bytes, 1362152 total
- age 3: 124920 bytes, 1487072 total
- age 4: 115256 bytes, 1602328 total
- age 5: 165000 bytes, 1767328 total
- age 6: 99776 bytes, 1867104 total
- age 7: 97728 bytes, 1964832 total
- age 8: 94616 bytes, 2059448 total
- age 9: 93176 bytes, 2152624 total
- age 10: 111352 bytes, 2263976 total
- age 11: 127800 bytes, 2391776 total
- age 12: 85248 bytes, 2477024 total
- age 13: 110984 bytes, 2588008 total
- age 14: 101880 bytes, 2689888 total
- age 15: 96288 bytes, 2786176 total
: 1747877K->18163K(1887488K), 0.0364969 secs] 4930355K->3200776K(6081792K), 0.0366162 secs] [Times: user=0.17 sys=0.00, real=0.04 secs]
Heap after GC invocations=897 (full 3):
par new generation total 1887488K, used 18163K [0x0000000640000000, 0x00000006c0000000, 0x00000006c0000000)
eden space 1677824K, 0% used [0x0000000640000000, 0x0000000640000000, 0x00000006a6680000)
from space 209664K, 8% used [0x00000006b3340000, 0x00000006b44fcd88, 0x00000006c0000000)
to space 209664K, 0% used [0x00000006a6680000, 0x00000006a6680000, 0x00000006b3340000)
concurrent mark-sweep generation total 4194304K, used 3182613K [0x00000006c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 60431K, capacity 66281K, committed 66588K, reserved 1107968K
class space used 6828K, capacity 8138K, committed 8224K, reserved 1048576K
}
CMS: abort preclean due to time 2019-10-29T18:03:25.825+0800: 7292.192: [CMS-concurrent-abortable-preclean: 4.952/5.002 secs] [Times: user=10.51 sys=1.44, real=5.01 secs]
2019-10-29T18:03:25.826+0800: 7292.193: [GC (CMS Final Remark) [YG occupancy: 81039 K (1887488 K)]2019-10-29T18:03:25.826+0800: 7292.194: [Rescan (parallel) , 0.0142974 secs]2019-10-29T18:03:25.841+0800: 7292.208: [weak refs processing, 0.0019208 secs]2019-10-29T18:03:25.843+0800: 7292.210: [class unloading, 0.0230836 secs]2019-10-29T18:03:25.866+0800: 7292.233: [scrub symbol table, 0.0054818 secs]2019-10-29T18:03:25.871+0800: 7292.238: [scrub string table, 0.0707817 secs][1 CMS-remark: 3182613K(4194304K)] 3263652K(6081792K), 0.1182958 secs] [Times: user=0.17 sys=0.01, real=0.11 secs]
2019-10-29T18:03:25.946+0800: 7292.313: [CMS-concurrent-sweep-start]
2019-10-29T18:03:27.771+0800: 7294.138: [CMS-concurrent-sweep: 1.825/1.826 secs] [Times: user=3.98 sys=0.52, real=1.82 secs]
2019-10-29T18:03:27.771+0800: 7294.138: [CMS-concurrent-reset-start]
2019-10-29T18:03:27.781+0800: 7294.148: [CMS-concurrent-reset: 0.010/0.010 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
JVMTI介绍
JVM相关参数:
-agentlib:<库名>[=<选项>]
加载本机代理库 <库名>, 例如 -agentlib:jdwp
另请参阅 -agentlib:jdwp=help
-agentpath:<路径名>[=<选项>]
按完整路径名加载本机代理库
-javaagent:<jar 路径>[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
JVMTI(Java Virtual Machine Tool Interface)即指Java虚拟机工具接口,它是一套由虚拟机直接提供的 native 接口,通过这些接口,开发人员不仅调试在该虚拟机上运行的 Java 程序,还能查看它们运行的状态,设置回调函数,控制某些环境变量(JMX),从而优化程序性能。Java Agent就是基于JVMTI的,所以众多基于Java Agent的技术例如APM,远程调试,各种性能剖析同样是基于这个技术。
JVMTI 接口:
JNIEXPORT jint JNICALL
Agent_OnLoad(JavaVM *vm, char *options, void *reserved);
JNIEXPORT jint JNICALL
Agent_OnAttach(JavaVM* vm, char* options, void* reserved);
JNIEXPORT void JNICALL
Agent_OnUnload(JavaVM *vm);
-agentpath是c/c++编写的动态库,-agentlib和-javaagent是一个instrument的JVMTIAgent(linux下对应的动态库是libinstrument.so)。
Attach机制
Jvm提供一种jvm进程间通信的能力,能让一个进程传命令给另外一个进程,并让它执行内部的一些操作,比如说我们为了让另外一个jvm进程把线程dump出来,那么我们跑了一个jstack的进程,然后传了个pid的参数,告诉它要哪个进程进行线程dump。
Attach命令列表
static AttachOperationFunctionInfo funcs[] = {
{ "agentProperties", get_agent_properties },
{ "datadump", data_dump },
{ "dumpheap", dump_heap },
{ "load", JvmtiExport::load_agent_library },
{ "properties", get_system_properties },
{ "threaddump", thread_dump },
{ "inspectheap", heap_inspection },
{ "setflag", set_flag },
{ "printflag", print_flag },
{ "jcmd", jcmd },
{ NULL, NULL }
};
Attach流程:
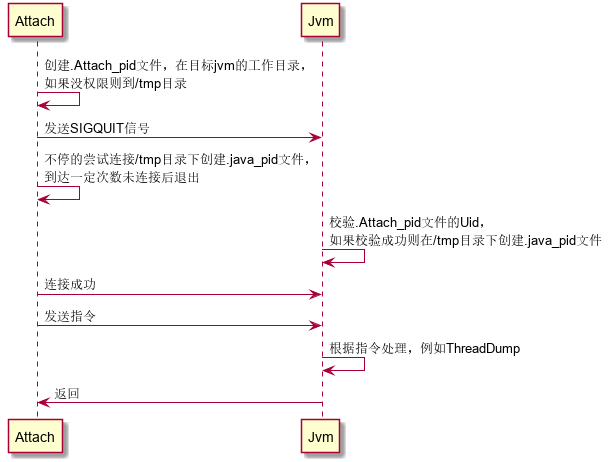
查看java线程:
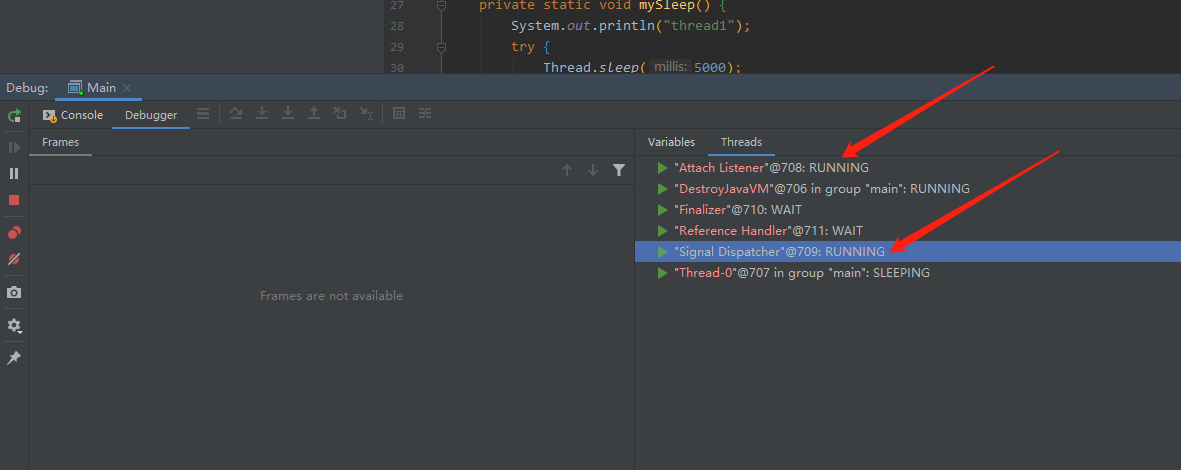
其中Siginal Dispatcher是处理进程信号的线程,Attach Listener正式Attach机制处理线程。
java自带工具
jps
查看Java进程列表
常用参数:
- -l: 输出应用程序主类完整package名称或jar完整名称
- -m:输出主函数传入的参数
jmap
查看JVM堆的情况
常用参数:
- -heap
- -dump 这个命令还有两个常用参数
- live 只dump存活对象,会导致GC
- file=file dump文件名
示例:jmap -dump:live,file=heap.dump <pid>
这里有两点,一方面需要注意live会导致GC,有时候在查问题的时候可能不是你预期的效果,一般查内存问题时不加这个选项,另外dump文件如果比较大,可以先压缩在传回本地
jstack
查看JVM的堆栈情况,监测死锁等
这个命令比较简单,一般不用加什么参数,有时候JVM没响应时可以加-F参数。一般这个命令可以结合top,在top定位到占用cpu高的线程后,在具体在Jstack打印的堆栈中查看线程,有时候也需要多次打印堆栈来进行对比
jstat
查看JVM gc信息,观察JVM的GC活动
常用参数: -gccause 这个参数包含了-gcutil的信息多了一个gc原因
示例: jstat -gccause <pid> 1000
11:19 [supertool@y051]$ jstat -gccause 10711 1000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT LGCC GCC
0.00 21.23 95.99 69.88 91.56 82.62 1187 22.511 4 0.141 22.652 Allocation Failure No GC
0.00 21.23 99.51 69.88 91.56 82.62 1187 22.511 4 0.141 22.652 Allocation Failure No GC
21.30 0.00 3.51 69.88 91.56 82.62 1188 22.530 4 0.141 22.671 Allocation Failure No GC
21.30 0.00 7.02 69.88 91.56 82.62 1188 22.530 4 0.141 22.671 Allocation Failure No GC
21.30 0.00 10.14 69.88 91.56 82.62 1188 22.530 4 0.141 22.671 Allocation Failure No GC
21.30 0.00 13.62 69.88 91.56 82.62 1188 22.530 4 0.141 22.671 Allocation Failure No GC
21.30 0.00 16.78 69.88 91.56 82.62 1188 22.530 4 0.141 22.671 Allocation Failure No GC
jinfo
查看设置的JVM参数和启动时的命令行参数,还可以动态修改JVM参数
常用参数
- -flags 查看jvm参数值
- -sysprops 查看系统属性值
示例: jinfo -flags 10711
Non-default VM flags: -XX:BiasedLockingStartupDelay=0 -XX:CICompilerCount=4 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=75 -XX:+CMSParallelRemarkEnabled -XX:ErrorFile=null -XX:GCLogFileSize=10485760 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=null -XX:InitialHeapSize=1073741824 -XX:MaxHeapSize=1073741824 -XX:MaxNewSize=268435456 -XX:MaxTenuringThreshold=15 -XX:MinHeapDeltaBytes=196608 -XX:NewSize=268435456 -XX:NumberOfGCLogFiles=20 -XX:OldPLABSize=16 -XX:OldSize=805306368 -XX:+PrintClassHistogram -XX:+PrintCommandLineFlags -XX:+PrintConcurrentLocks -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:StringTableSize=6000000 -XX:+UseBiasedLocking -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseFastUnorderedTimeStamps -XX:+UseGCLogFileRotation -XX:+UseParNewGC
Command line: -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 -XX:+PrintCommandLineFlags -Xms1g -Xmx1g -Xmn256m -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5006 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Dfile.encoding=UTF-8 -XX:MaxTenuringThreshold=15 -XX:StringTableSize=6000000 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintHeapAtGC -XX:+PrintClassHistogram -XX:+PrintConcurrentLocks -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=20 -XX:GCLogFileSize=10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/java/logs -XX:ErrorFile=/var/java/logs/jvm-error.log -Dlog4j.config.file=log4j_.properties -Dvertx.logger-delegate-factory-class-name=io.vertx.core.logging.Log4jLogDelegateFactory -Dvertx.options.maxEventLoopExecuteTime=100000000 -Dvertx.options.warningExceptionTime=300000000
JDPA(Java Platform Debugger Architecture)
java远程调试,需要jvm启动时加参数:-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005
远程调试非常有用,有时候测试环境很难复现时,可以用通过远程调试查看线程数据
三、三方工具
jprofile
CPU性能分析
抽样:每隔一段时间,获取线程栈,分析各个栈上出现的方法的次数
优点:性能高
缺点: 不适合做精确的分析
适用范围:寻找程序的执行热点,cpu密集型
指令插入:使用增强的技术修改java class的字节码,在函数的出入口增加埋点
优点:数据准确
缺点:导致jvm内联优化失效,性能低
适用范围:分析具体耗时路径的各个执行时间,io密集型
一般先使用抽样在定位到大致的范围,然后使用指令插入分析具体代码执行路径中的耗时,jprofile可以通过过滤只对指定类进行增强
- Thread Status:选择线程统计状态,Runnable显示的是cpu时间,不包含sleep这种时间一般都是这个模式。还可以使用IO Net模式分析io等待,Wait分析锁竞争模式
- Call tree filters :调用树过滤:用于过滤不需要的类,例如你使用web框架,栈中起始的方法都是框架中的代码,最后才是你的业务代码,这时候可以使用Call tree filters来过滤不需要的类型,减少统计造成的性能开销
内存剖析
分析内存泄漏的利器,主要是看内存中内存占比和大对象。很多时候如果有内存泄漏基本都是以为某些类型的对象占用了大头。
arthas (类似btrace的工具)
Arthas 是Alibaba开源的Java诊断工具。线上debug的工具,很多时候因为性能和安全等原因我们不能直接远程调试线上的jvm,这时候我们可以使用arthas来查看内存的数据,方法调用情况,打印日志信息等。
比较常用的:
- watch 看方法调用情况 -c 统计周期,默认值为120秒
- monitor 统计方法调用信息
- getstatic 查看静态变量
- logger 查看和修改logger
- trace 方法内部调用路径,并输出方法路径上的每个节点上耗时
示例:
monitor -c 5 com.miaozhen.bazaro.deal.PreferredDealFilterService filterwatch com.miaozhen.bazaro.share.manager.util.DealManager getDspToDealsByPid "returnObj"
gceasy
https://gceasy.io/ 一个在线分析gc日志的网站,
四、实际案例
连接泄漏
场景描述:我们公司的用户服务对接了第三方腾讯云通信服务,在用户注册的时候我们需要走http接口调腾讯云,问题就出在http连接那块,同事当时采用了,线上出现了cpu100%的问题,日志出现java.lang.OutOfMemoryError: GC overhead limit exceeded。
排查思路:这个其实很好定位,本来还想打印线程栈看下到底是哪个导致的cpu100%,一看日志直接定位到gc出问题。GC overhead limit exceeded是指gc占用了大量的cpu时间又回收不了内存引起的,从内存泄露去考虑,重启服务 ,启动参数加上-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./user.hprof -verbose:gc -Xloggc:user%t.log。问题复现的时候获得了堆的dump文件,然后通过Jprofile分析,发现有大量的http.HttpKeepAliveCache实例,占用了80%的内存,大致定位到是由于http连接泄露。同事封装的HttpUtil中使用了HttpsURLConnection,在读取完数据的时候没有关闭InputStream导致连接没有关闭。
说明:GC overhead limit exceeded,默认情况下,如果Java进程花费98%以上的时间执行GC,并且每次只有不到2%的堆被恢复,则JVM抛出此错误。这个错误是parallel Scavenge 特有的
String拼接导致内存溢出
公司的后台有段时间会间歇性的卡顿,严重的情况下会导致cpu100%。在cpu100%的时候,通过top定位到进程号,然后输入H切换到线程,记住具体的进程号,使用jstack打印java进程的线程栈,jstack输出为十六进制,需要将top的转换成十六进制的然后入找线程经常卡在哪个方法。定位到方法发现是查询用户关联设备号的方法出问题,方法的逻辑是从数据库查询设备号,在内存中以以逗号分隔拼接返回,如1,2,3。这个bug的原因是有如下:
sql出错,导致查询返回数据量很多,正常情况最多几百个,但是异常情况有七万个设备号
字符串拼接采用str+="1234"的形式,导致大量的内存分配和回收。
运营在点击后台查询的时候发现没返回,点掉就重新点,导致服务器多个线程卡在这个方法造成cpu100%。解决完sql,改用StringBuilder问题解决。
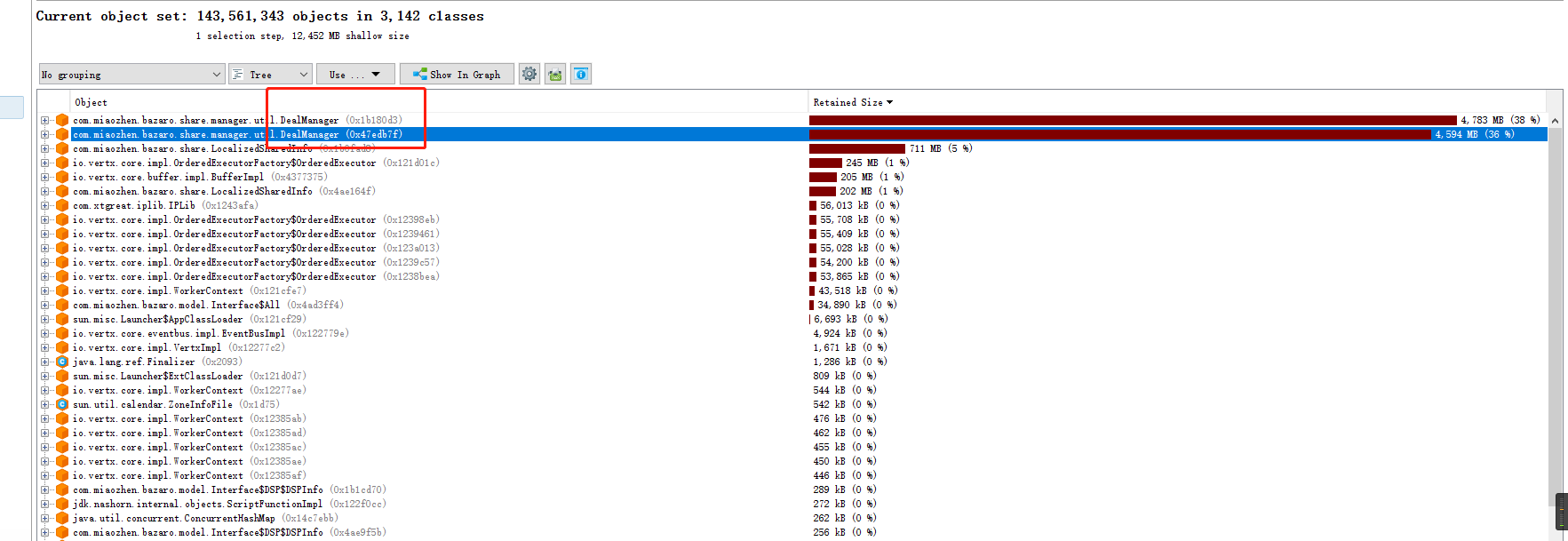
堆内存占用过大
我们的一个服务程序,老年代设置了10g,新生代2g,偶会会出现内存溢出的线程,通过分析内存发现deal数据占用了大量内存,最高可达9.4g。
堆数据:
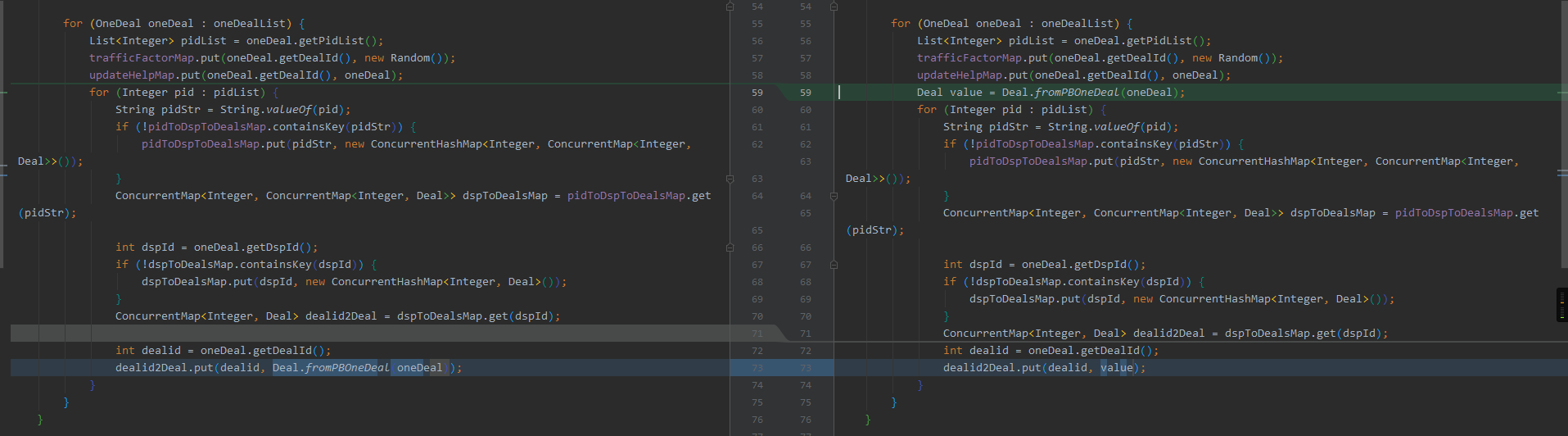
问题代码:
优化后堆数据:
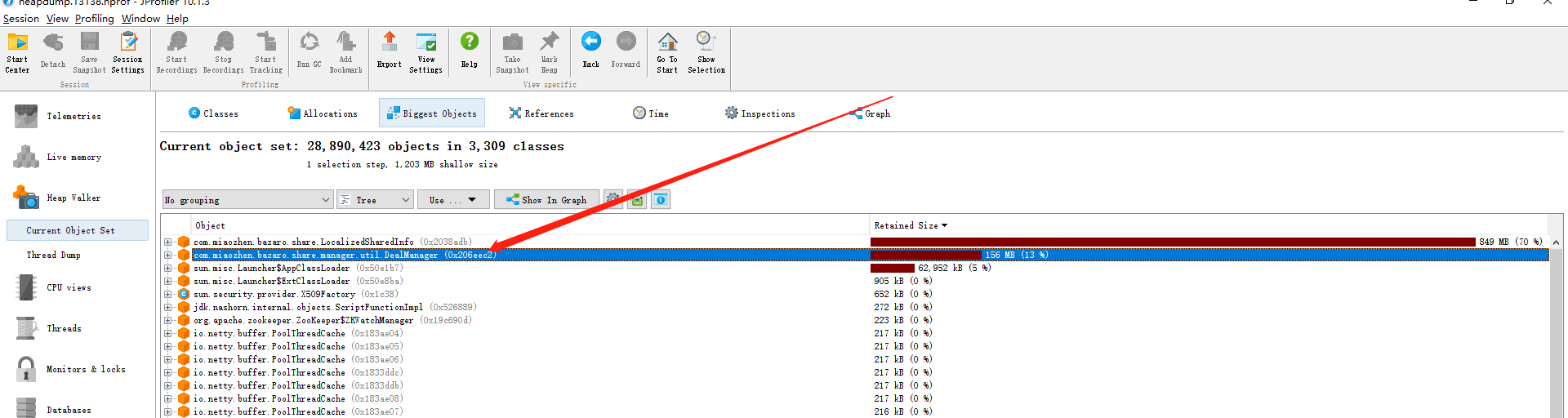
优化后降低了老年代改为4g,大大降低了Jvm的堆的大小,16g机器现在可部署两个实例,且Full Gc稳定在一天一次,Young Gc 5s一次,均处正常。
CPU占用高问题
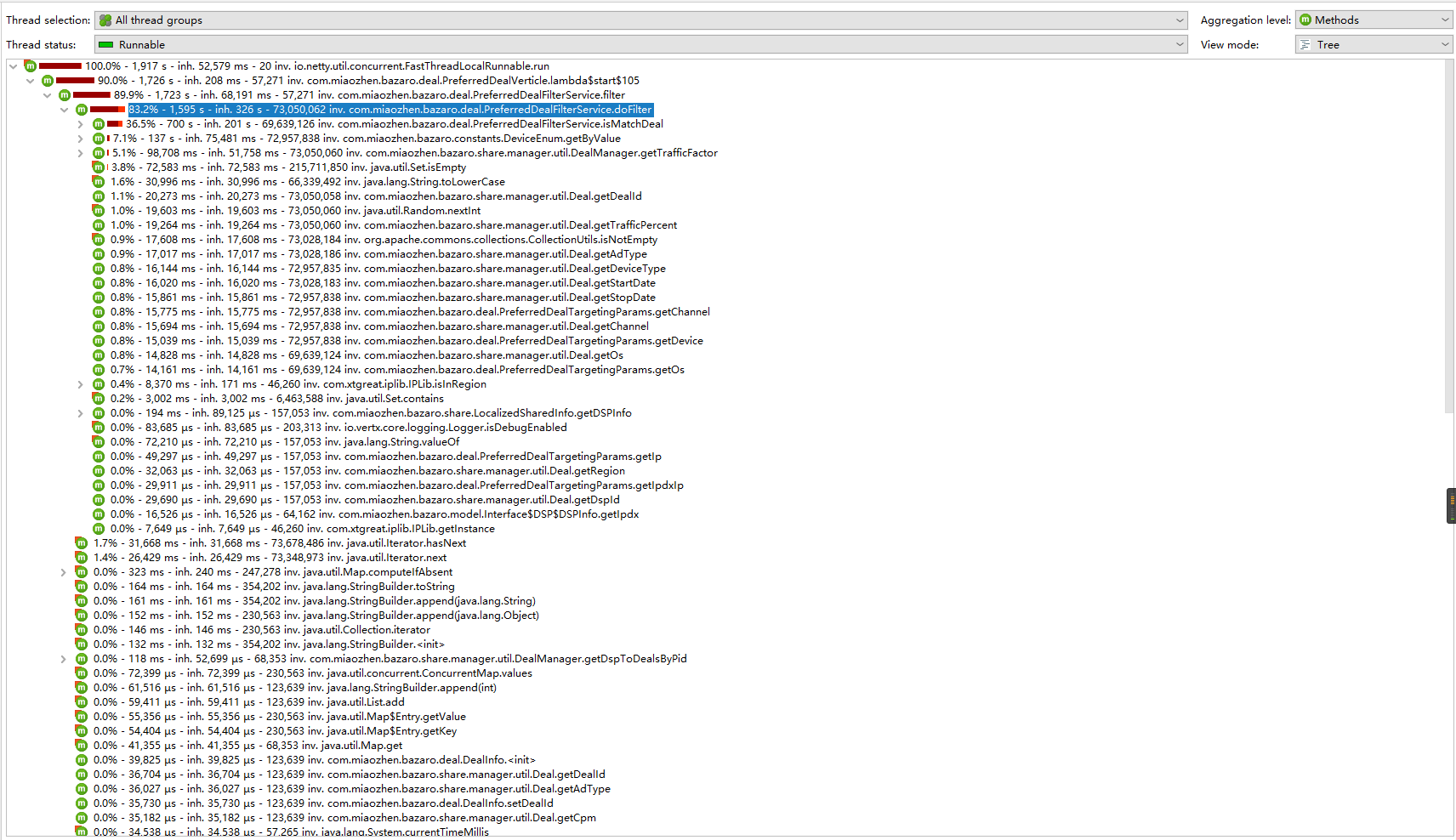
最近在分析拍卖程序时,发现com.miaozhen.bazaro.deal.PreferredDealFilterService#filter方法占用了90%的cpu时间。
cpu热点图:
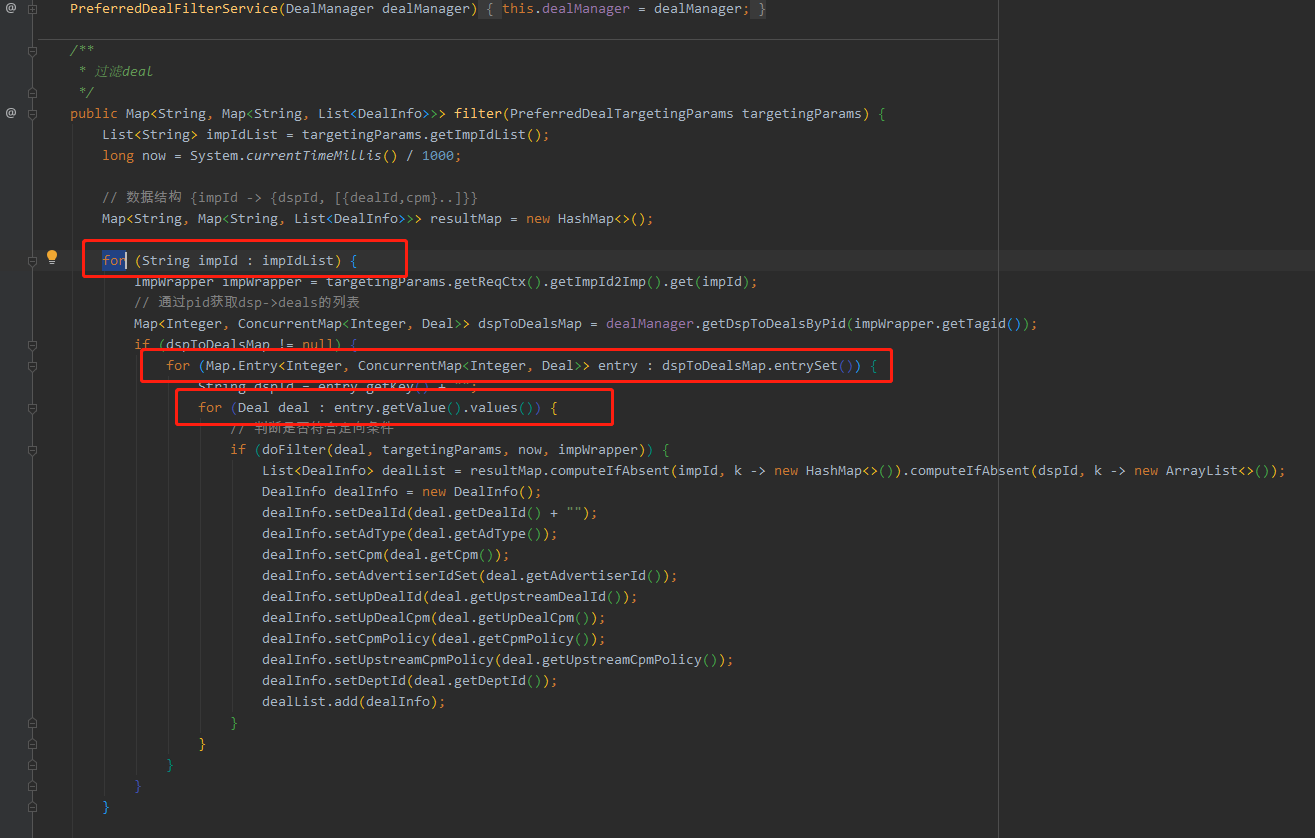
问题代码:
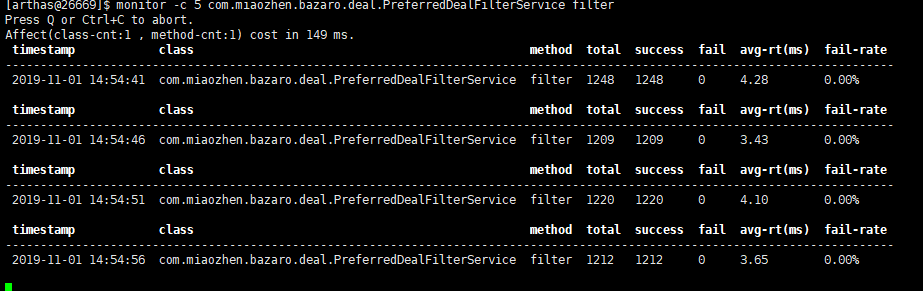
分析该方法的时长:
查看耗时deal数据
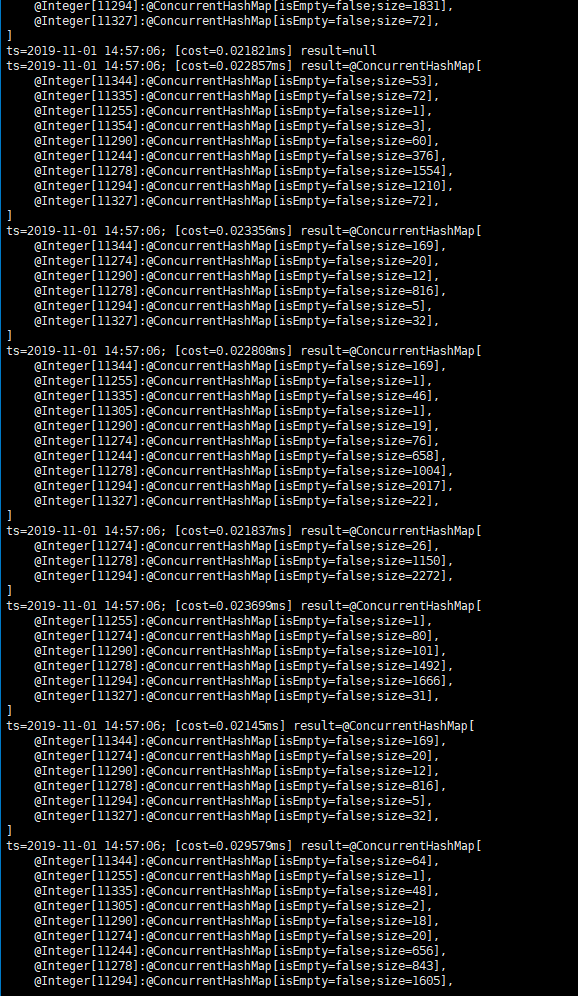
aerospike线程阻塞导致内存溢出问题
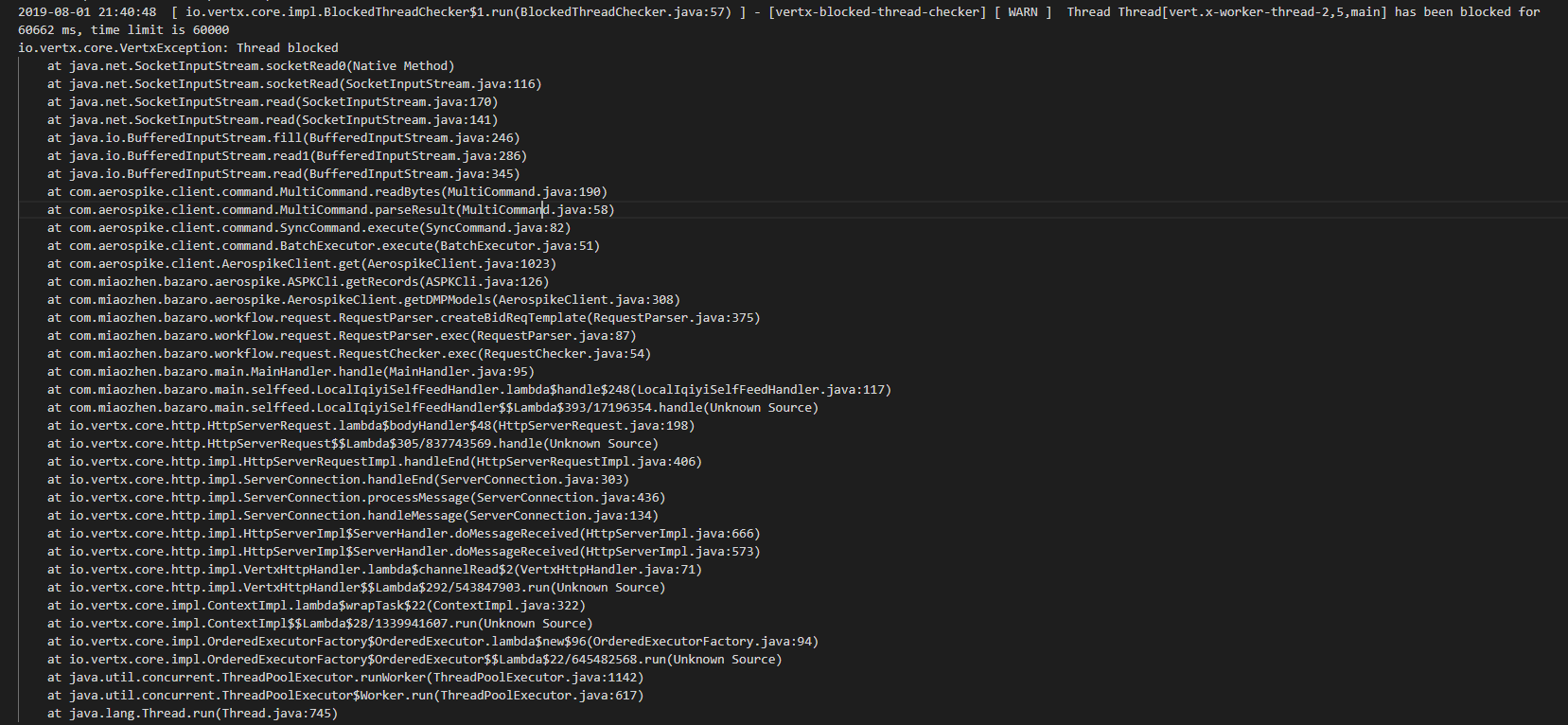
问题:拍卖在五点多收到网站推送数据的时候发生OOM。
查看日志发现,有很多关于线程阻塞的报错,是读取aerospike卡住导致。报错如下:
观察gc分析结果:
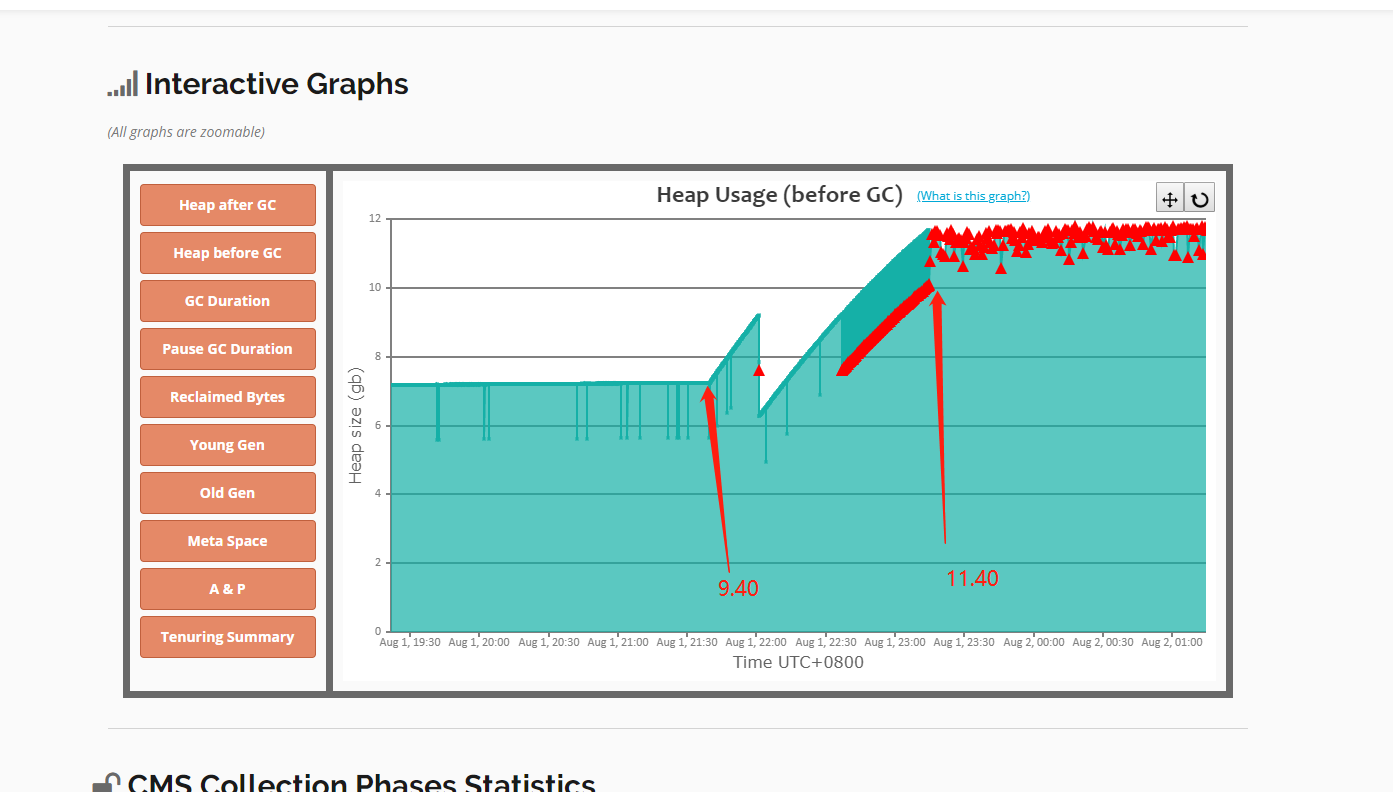
可以看到本来堆内存始终稳定在一个水平,在一个时间点之后,堆内存开始稳步上涨,十分符合内存泄漏的特征。
观察堆内存数据:
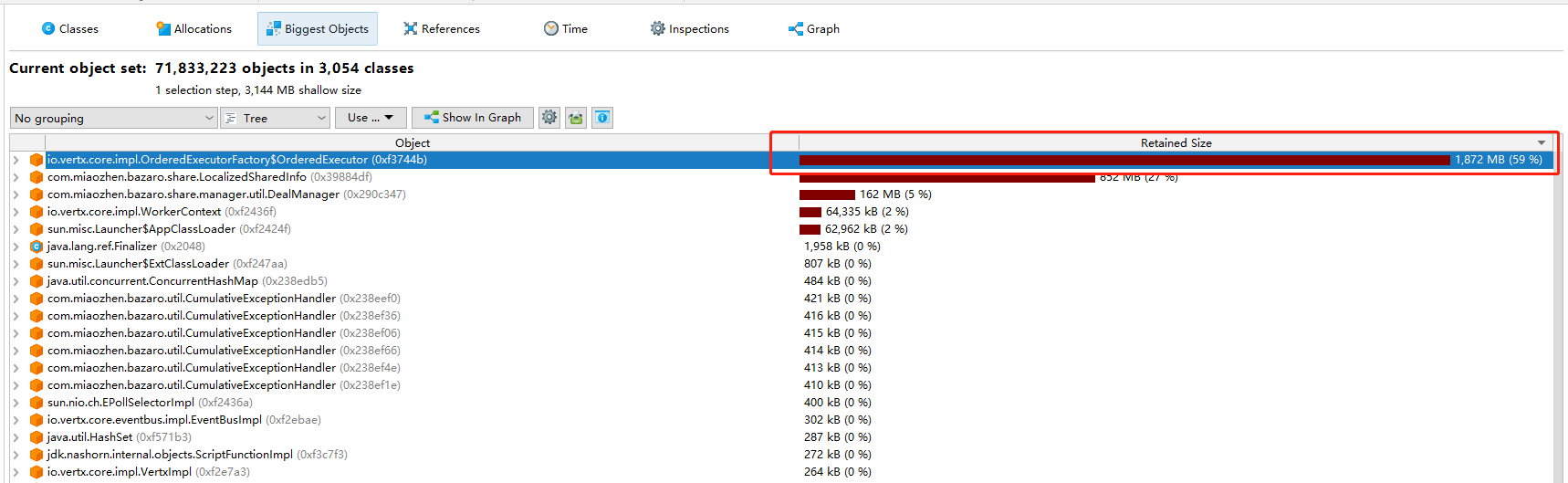
注:这个堆内存不是当时,当时的堆内存没找到,占比是类似的。这个图内存优化之后的,所以老年代只有4g。
可以看到其中OrderedExecutor占用了大量的内存,这个数据接口是用来存放http请求的接口。
总结:
晚上九点40线程阻塞,但是请求的任务不停地往他的tasks里面放,十分钟后grafana监控显示上升了16%的超时率(六个verticle挂了一个),从4%到20%。
查看内存监控图,9点40开始内存上升,不再回收,最终存了2900万个tasks,一个线程占用了10g内存,到晚上11.15左右日志出现大量的空指针和超时,十分钟后监控图显示全部超时,gc监控显示大量full gc,因为内存不够大量的gc占用了进程cpu时间。,5点多的时候推送物料,服务器内存溢出。
参考资料:
- Java远程调试JDPA介绍
- JVM源码分析之javaagent原理完全解读
- 深入理解Java虚拟机(第2版)
- JVM CPU Profiler技术原理及源码深度解析
- JVM 与 Linux 的内存关系详解
- Oracle JDK文档
- JProfile
- Arthas官网
- CMS收集器参数
问题
- 什么样的代码算是耗时的代码,或者说耗时代码的特征是什么
- jvm一个线程发生OOM会导致JVM挂掉吗
- 内存问题会导致cpu飙高吗


