【SQL编写】常用常新
简介
手生时回顾,存放工作中使用SQL查询时候进行优化的一些案例&总结&学习记录。
SQL执行顺序:

易错总结
1.Group By 后面使用select中给定的别名不符合SQL编写规则
SQL语句执行时候一般都是先进行Group By,后进行select,通常也会报错。但是一些数据库会先对SELECT子句里的列表进行扫描,并对列进行计算。
2.CASE WHEN表达式
1)在发现为真的WHEN子句时,CASE表达式的真假值判断就会中止,而剩余的WHEN子句会被忽略。
2)要注意CASE表达式里各个分支返回的数据类型是保持一致。
3)不写else时,其他归为null,不利于后期排查。
4)sum(case when .. then 1 else 0 end) ——聚合内部用case表达式的条件分支形式通常用于行转列的汇总计算,得到交叉表。
5)CASE表达式用在SELECT子句里时,既可以写在聚合函数内部,也可以写在聚合函数外部。
CREATE TABLE StudentClub (
std_id INTEGER,
club_id INTEGER,
club_name VARCHAR(32),
main_club_flg CHAR(1),
PRIMARY KEY (std_id, club_id)
);
-- 参加了多个社团的学生中, main_club_flg为Y表示主社团
INSERT INTO StudentClub VALUES(100, 1, '棒球', 'Y');
INSERT INTO StudentClub VALUES(100, 2, '管弦乐', 'N');
INSERT INTO StudentClub VALUES(200, 2, '管弦乐', 'N');
INSERT INTO StudentClub VALUES(200, 3, '羽毛球', 'Y');
INSERT INTO StudentClub VALUES(200, 4, '足球', 'N');
INSERT INTO StudentClub VALUES(300, 4, '足球', 'N');
INSERT INTO StudentClub VALUES(400, 5, '游泳', 'N');
INSERT INTO StudentClub VALUES(500, 6, '围棋', 'N');
/* 问题: 查询只参加一个社团的人的社团名称&参加多个社团的主社团(Y) */
-- 方法一:合并两个查询
select std_id, club_name from studentclub
group by std_id
having count(*) = 1
union all
select std_id, club_name from studentclub
where main_club_flg = "Y"
-- 方法二:case表达式
SELECT std_id,
case
when count(*)=1 then club_name /* 只加了一个社团的学生 */
else max(CASE WHEN main_club_flg = 'Y' then club_name else null end) -- 牛啊。一定要带上这个max!
end 'club_name_'
from studentclub
GROUP BY std_id
6)个人感觉用case表达式多用来创建新的列。其实多半也是上面4中的交叉表思想,或是做一些特殊分支:
-- order by + case 做特殊排序列
select k, from t
order by (case when k='A' then 2 when k='B' then 1
when k='C' then 4 when k='D' then 3 end
)
-- group by 中分组依据
select
case when age>=25 then '25岁及以上' else '25岁以下' end age_cut,
count(1) num
from t
group by case when age>=25 then '25岁及以上' else '25岁以下' end
3.EXISTS用法


4.自联结
1)select a.col1, a.col2, b.col1, b.bol2 from t a, t b生成笛卡尔集表
自联结只是数据库将同一张物理表当成存储相同数据的不同的数据集合。
再在上述SQL基础上加上where a.col1 <> b.col1则会进行相同行去重,亦或者进行>, <等操作进行筛选。
自联结通常与非等值连接结合使用,但是性能开销较大,通常在主键上使用。
自联结+group by 实现递归集合。
2)自外连接left join
SELECT
s1.year, s1.sale,
s2.year year_, s2.sale sale_
FROM sales s1
LEFT JOIN sales s2
ON s1.year-1=s2.year
-- 若是采用自联结,会缺少一条记录
SELECT
s1.year, s1.sale,
s2.year year_, s2.sale sale_
FROM sales s1, sales s2
WHERE s1.year-1=s2.year;
3)累计值
CREATE TABLE action_log (
user_id VARCHAR(5),
log_date date,
amount int
);
INSERT INTO action_log (user_id, log_date, amount)
VALUES (2, '2021-04-01', 30),
(2, '2021-04-02', 40),
(2, '2021-04-03', 15),
(2, '2021-04-04', 15),
(2, '2021-04-06', 15),
(2, '2021-04-06', 55),
(2, '2021-04-07', 10),
(2, '2021-04-08', 55),
(2, '2021-04-09', 5),
(2, '2021-04-10', 15),
(2, '2021-04-11', 60),
(2, '2021-04-12', 10),
(3, '2021-04-03', 5),
(3, '2021-04-04', 20),
(3, '2021-04-05', 35),
(3, '2021-04-06', 40),
(3, '2021-04-07', 55),
(3, '2021-04-08', 60),
(3, '2021-04-09', 20),
(5, '2021-04-08', 10),
(5, '2021-04-09', 20),
(5, '2021-04-15', 30),
(6, '2021-04-10', 5),
(6, '2021-04-12', 15),
(6, '2021-04-13', 25),
(6, '2021-04-22', 20),
(7, '2021-04-20', 10)
;
下面的一些思路未考虑日内多次登录情况 -> 聚合一下即可
思路一:左连接 最常规的方式
SELECT
t.d1 AS 日期 ,
COUNT(DISTINCT t.user_id) AS 首日 ,
COUNT(DISTINCT IF(DATEDIFF(t.d2, t.d1)=1, t.user_id, NULL )) AS 次日用户数,
COUNT(DISTINCT IF(DATEDIFF(t.d2, t.d1)=7, t.user_id, NULL )) AS 第八日用户数
FROM (
SELECT
a.user_id, a.log_date d1, b.log_date d2
FROM action_log a
LEFT JOIN action_log b
ON a.user_id = b.user_id
WHERE b.log_date >= a.log_date
ORDER BY a.user_id, a.log_date, b.log_date
) t
GROUP BY t.d1
思路二:case 表达式 下面这种得到的是以temp表中的first_dayfirst_day作为基准表的结果
SELECT
temp.first_day AS 日期 ,
COUNT(DISTINCT temp.user_id) AS 新增用户数 ,
COUNT(DISTINCT b.user_id) AS 次日留存用户数,
COUNT(DISTINCT c.user_id) AS 七日留存用户数
FROM (select user_id, min(log_date) first_day from action_log) temp
LEFT JOIN action_log b ON temp.user_id = b.user_id and DATEDIFF(b.log_date, temp.first_day) = 1
LEFT JOIN action_log c ON temp.user_id = c.user_id and DATEDIFF(c.log_date, temp.first_day) = 7
GROUP BY temp.first_day
5.NULL的问题
and优先级:false > unknown > true
or优先级 : true > unknown > false

1)case when xx is null而不是case xx when null;
2)xx not in (select 子句) 的子句查询结果包含null时,查询结果为空。要么填补子句null,要么改用not exists。
PS:not in 与 not exists不可随意替换,in 与 exists等同。
3)null本身不是值,对其使用各种谓词结果是unknown,对含null列聚合运算结果也会受到影响。
4)count(*)算的是表的多少条记录,count(col)算的是col列非null值的个数。
SELECT col FROM tb
GROUP BY dpt
HAVING COUNT(*) = COUNT(col1);
SELECT col FROM tb
GROUP BY col
HAVING COUNT(*) = SUM(CASE WHEN col1 IS NOT NULL THEN 1 ELSE 0 END);
常见查询
1.查询中位数
众数比较好写,group by + count(xx) 获取出现次数,再外套一层获取max次数。
下面是中位数的示例SQL:
思路一:计算所有消费记录(值有重复)的中位数
SELECT
action_log.amount
FROM action_log, action_log b
GROUP BY action_log.amount
HAVING SUM( CASE WHEN action_log.amount >= b.amount THEN 1 ELSE 0 END ) >= COUNT(*) / 2
AND SUM( CASE WHEN action_log.amount <= b.amount THEN 1 ELSE 0 END ) >= COUNT(*) / 2
思路二:摘自网络,利用abs(rn - (cnt+1)/2) < 1限制,rn表示当前排序的行
select
avg(amount) as median
from (
select
user_id, amount,
row_number() over(order by amount) as rn,
count(1) over() as cnt
from action_log
) t
where abs(rn - (cnt+1)/2) < 1
-- 查每个用户分组的消费中位数
select
user_id, avg(amount) as median
from (
select
user_id, amount,
row_number() over(partition by user_id order by amount) as rn, -- 分组行数
count(1) over(partition by user_id) as cnt -- 总记录数
from action_log
) temp
where abs(rn - (cnt+1)/2) < 1 -- 顺序编号在店铺商品销量记录数中间的,即为中位数
group by user_id
2.行列转化
行列的转换其实可以与前面case when表达式处提及的交叉表看成一个东西。
/* 用外连接进行行列转换(1)(行→列):制作交叉表 */
CREATE TABLE Courses(
name VARCHAR(32),
course VARCHAR(32),
PRIMARY KEY(name, course)
);
INSERT INTO Courses VALUES('赤井', 'SQL入门');
INSERT INTO Courses VALUES('赤井', 'UNIX基础');
INSERT INTO Courses VALUES('铃木', 'SQL入门');
INSERT INTO Courses VALUES('工藤', 'SQL入门');
INSERT INTO Courses VALUES('工藤', 'Java中级');
INSERT INTO Courses VALUES('吉田', 'UNIX基础');
INSERT INTO Courses VALUES('渡边', 'SQL入门');
SELECT * FROM courses order by name;
/* 1:侧边栏&表头随意配置,但是显得臃肿,且性能不高 */
SELECT C0.name,
CASE WHEN C1.name IS NOT NULL THEN '○' ELSE NULL END AS "SQL入门"
CASE WHEN C2.name IS NOT NULL THEN '○' ELSE NULL END AS "UNIX基础",
CASE WHEN C3.name IS NOT NULL THEN '○' ELSE NULL END AS "Java中级"
FROM (SELECT DISTINCT name FROM courses) C0 -- C0作为固定的基础主表
LEFT JOIN (
SELECT name FROM courses WHERE course = 'SQL入门'
) C1
ON C0.name = C1.name
LEFT JOIN (
SELECT name FROM courses WHERE course = 'UNIX基础'
) C2
ON C0.name = C2.name
LEFT JOIN (
SELECT name FROM courses WHERE course = 'Java中级'
) C3
ON C0.name = C3.name;
/* 2:使用标量子查询替代外连接 */
SELECT
C0.name,
(
SELECT '○' FROM courses C1
WHERE course = 'SQL入门' AND C1.name = C0.name
) AS "SQL入门",
(
SELECT '○' FROM courses C2
WHERE course = 'UNIX基础' AND C2.name = C0.name
) AS "UNIX基础",
(
SELECT '○' FROM courses C3
WHERE course = 'Java中级'AND C3.name = C0.name
) AS "Java中级"
FROM (SELECT DISTINCT name FROM Courses) C0; -- C0作为主表
/* 3-1:嵌套使用CASE表达式, 这个max显得不是很直观 */
SELECT
name,
max(case when course="SQL入门" THEN '○' ELSE NULL end) "SQL入门",
max(case when course="UNIX基础" THEN '○' ELSE NULL end) "UNIX基础",
max(case when course="Java中级" THEN '○' ELSE NULL end) "Java中级"
FROM courses
GROUP BY name
/* 3-2:嵌套使用CASE表达式 */
SELECT name,
CASE WHEN SUM(CASE WHEN course = 'SQL入门' THEN 1 ELSE NULL END) >= 1
THEN '○' ELSE NULL END AS "SQL入门",
CASE WHEN SUM(CASE WHEN course = 'UNIX基础' THEN 1 ELSE NULL END) >= 1
THEN '○' ELSE NULL END AS "UNIX基础",
CASE WHEN SUM(CASE WHEN course = 'Java中级' THEN 1 ELSE NULL END) >= 1
THEN '○' ELSE NULL END AS "Java中级"
FROM courses
GROUP BY name;
若是将交叉表拆还原呢?
3.窗口函数应用
常用窗口函数一览:
函数格式: <窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名> rows between A and B)
PS: A和B是计算的行数范围
rows between 2 preceding and current row # 取当前行和前面两行
rows between unbounded preceding and current row # 包括本行和之前所有的行
rows between current row and unbounded following # 包括本行和之后所有的行
rows between 3 preceding and current row # 包括本行和前面三行
rows between 3 preceding and 1 following # 从前面三行和下面一行,总共五行
当order by后面缺少窗口从句条件,窗口规范默认是rows between unbounded preceding and current row.
当order by和窗口从句都缺失, 窗口规范默认是 rows between unbounded preceding and unbounded following
执行顺序:FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT前。
执行时GROUP BY的聚合过程已完成,所以不会再产生数据聚合,保留原聚合结果行数。
窗口函数--基础的入sum, count, avg不赘述
1. 序号函数:row_number() / rank() / dense_rank() --> 1,2,3 / 1,1,3 / 1,1,2
2. 分布函数:percent_rank() / cume_dist()
3. 前后函数:lag(xx, N) / lead(xx, N) --> 当前行后/前N行的值
4. 头尾函数:first_val() / last_val()
5. 计算函数: sum(xx) / avg(xx) / min(xx) / max(xx) 之类的, 同Group by
6. 其他函数:nth_value() / 用途:将分区中的有序数据分为n个桶,记录桶号
比如用序号函数可以求排名、求每一行与上一行的差值:
方法一:
select (ROW_NUMBER() over(order by year)) as row_number, num from tb
select (ROW_NUMBER() over(order by year)+1) as row_number1, num from tb
这就有两个错开行数的表,或者存成视图,再左连接row_number,得到两列num,再做处理即可
方法二:当然这种求不同行数据差异,若是每行有某个有序id,可以通过子连接在id上做操作
比如通过id-1进行偏移后进行自联结:
SELECT s1.year, s1.sale, s2.year year_, s2.sale sale_
FROM sales s1
LEFT JOIN sales s2
ON s1.year-1 = s2.year
从这里可以再次感受到,SQL处理列数据远不如处理行数据那么方便,而窗口函数用来处理移动计算是很方便的。
案例二: 求间隔3行内的数据累加和
-- 移动累计值和移动平均值
CREATE TABLE Accounts (
prc_date DATE NOT NULL ,
prc_amt INTEGER NOT NULL ,
PRIMARY KEY (prc_date)
) ;
INSERT INTO Accounts VALUES ('2006-10-26', 12000 );
INSERT INTO Accounts VALUES ('2006-10-28', 2500 );
INSERT INTO Accounts VALUES ('2006-10-31', -15000 );
INSERT INTO Accounts VALUES ('2006-11-03', 34000 );
INSERT INTO Accounts VALUES ('2006-11-04', -5000 );
INSERT INTO Accounts VALUES ('2006-11-06', 7200 );
INSERT INTO Accounts VALUES ('2006-11-11', 11000 );
/* 求移动累计值1:使用窗口函数 */
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date ROWS 2 PRECEDING) AS onhand_amt
FROM Accounts;
/* 求移动累计值2:不满3行的时间区间也输出 */
SELECT prc_date, A1.prc_amt,
(
SELECT SUM(prc_amt) FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (
SELECT COUNT(*) FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date
) <= 3 -- 累计3行这个区间内的数据
) AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;
/* 移动累计值3:不满3行的区间按无效处理 */
SELECT prc_date, A1.prc_amt,
(
SELECT SUM(prc_amt) FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (
SELECT COUNT(*) FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date
) <= 3 -- 累计3行这个区间内的数据
HAVING COUNT(*) = 3 /* 不满3行数据的不显示 */
) AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;
回到上面求累计值的action_log案例
思路三: 使用窗口函数进行计算(面试常考, 会问连表之外的比如窗口函数方式的实现)
SELECT
user_id
-- COUNT(DISTINCT IF(DATEDIFF(temp.log_date, temp.first_day)=1, temp.user_id, NULL)) AS 第二日用户数
from (
SELECT
user_id, log_date, min(log_date) over(PARTITION by user_id) as first_day
FROM action_log
GROUP BY user_id, log_date
) temp
WHERE DATEDIFF(temp.log_date, temp.first_day)=1
延申1: 可算连续登录N天的问题:
SELECT
user_id
FROM (
SELECT
user_id, log_date,
row_number() over(PARTITION by user_id ORDER BY log_date) row_num
FROM action_log
GROUP BY user_id, log_date # 或者distinct user_id, log_date
) temp
GROUP BY DATE_SUB(log_date, INTERVAL row_num DAY) -- Hive中是date_sub(log_date, row_num)
HAVING count(user_id) >= 3 -- N=3时
延申2: 可算间隔登录天的问题:
select
user_id, log_date,
lead(log_date, 1) over(partition by user_id order by log_date) as lead_1, -- 间隔一天
lead(log_date, 1) over(partition by user_id order by log_date) - log_date as diff
from action_log
GROUP BY user_id, log_date
相关题目:
1.计算用户的平均次日留存率
4.表与表比较
-- 利用union去重特性比较两表是否一致
select count(*) as row_num from (
select * from tb
union -- 求两集合并集,依旧是集合的思想
select * from tb
) tmp;
下面创建一张表,任务是找到供应零件类型和数目均相同的supplier(A与C,B与D)
CREATE TABLE SupParts (
sup CHAR(32) NOT NULL,
part CHAR(32) NOT NULL,
PRIMARY KEY(sup, part)
);
INSERT INTO SupParts VALUES('A', '螺丝');
INSERT INTO SupParts VALUES('A', '螺母');
INSERT INTO SupParts VALUES('A', '管子');
INSERT INTO SupParts VALUES('B', '螺丝');
INSERT INTO SupParts VALUES('B', '管子');
INSERT INTO SupParts VALUES('C', '螺丝');
INSERT INTO SupParts VALUES('C', '螺母');
INSERT INTO SupParts VALUES('C', '管子');
INSERT INTO SupParts VALUES('D', '螺丝');
INSERT INTO SupParts VALUES('D', '管子');
INSERT INTO SupParts VALUES('E', '保险丝');
INSERT INTO SupParts VALUES('E', '螺母');
INSERT INTO SupParts VALUES('E', '管子');
INSERT INTO SupParts VALUES('F', '保险丝');
SELECT SP1.sup, SP2.sup
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup /* 非等值连接 生成供应商的全部组合 */
AND SP1.part = SP2.part /* 条件1:经营同种类型的零件 */
GROUP BY SP1.sup, SP2.sup /* 聚合去重 */
HAVING COUNT(*) = ( /* 条件2:经营的零件种类数相同 */
SELECT COUNT(*)
FROM SupParts SP3
WHERE SP3.sup = SP1.sup
)
AND COUNT(*) = (
SELECT COUNT(*)
FROM SupParts SP4
WHERE SP4.sup = SP2.sup
);
5.日期表维护
一个场景是:按日期聚合用户数据到组织区域时,如果某天数据缺失或者确无记录,聚合结果也会缺失当天记录。若是想将缺失的日期进行补0,如何操作?
介绍一个Hive中的函数posexplode
-- 创建日期维度表
select
dt, date_add(dt, pos) generated_date
from
(
select '2022-4-21' dt
) t -- 查询某日期
lateral view posexplode(split(repeat(", ", 10), ",")) tf AS pos,val -- 重复10次,最终11条数据
limit 30 ;
结果:
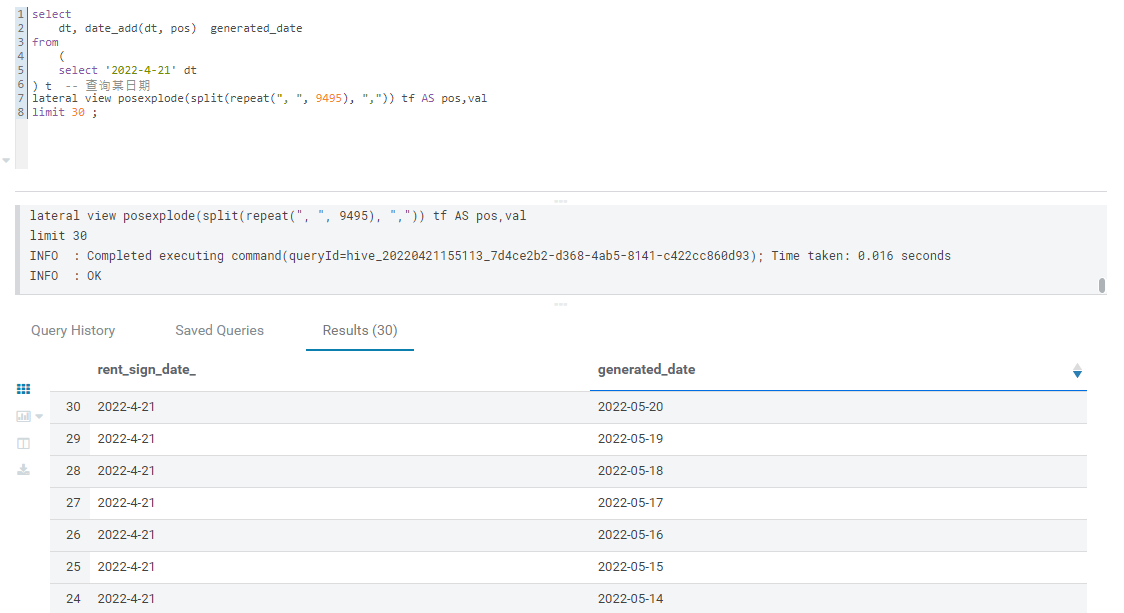
20220421 这次的需求场景是按照某组织区域聚合,但是一些区域某些天缺少A,某些天缺少B,用上面的方式好像还是达不成目标。暂时通过维护一张 维度+扩展每个日期的临时表,然后左连接聚合后的A和聚合后的B实现。。。未完待续...
边角旁门
一些比较常见,零散,暂未统一整理的点。
1.with name as (select ...)创建临时表
在公司是在HUE平台上编写SQL,之前不知道怎么弄创建视图,因为账号没有create权限,如下:

具体的使用方式见如下伪代码:
with temp as (
select sth_complex...
)
select do_sth_with_temp; -- 注意这个select需要直接放在with语句正下面第一句,中间不可插入运行其他查询&不可有空行!
另外可以嵌套(但是不太直观了):
with temp2 as (
with temp1 as (
select * from xxx
)
select * from temp1
)
select * from temp2;
2.数据倾斜问题
参考:
1)Hive的数据倾斜-博客园
这里有个赋予空值新的 key 值,在where 连接中使用case when,这个可以看看这篇.
2)一文带你搞清楚什么是“数据倾斜”-腾讯云
3)面试必问&数据倾斜-知乎:这一篇文章算是对于门外汉解释得比较清楚啥是“数据倾斜”
3.Hive中的explode使用全解
参考:知乎-阿誠的数据杂货铺-explode使用全解
4.空值替代(nvl/Coalesce)
前者只能使用两个参数,后者可以多参数——包含多层null判断
5.多列最大值: GREATEST(col1, col2, ...)
单列的直接用group by即可。
6.关联子查询
这个技巧部分对应《SQL进阶教程》中的1-6章节。
同一张表出现在不同位置(列子查询,where条件中子查询等),本质上是将一张表看成不同的集合,可以在编写SQL时赋不同的简写如t1,t2等。
但是,可读性和性能上不是很好。
7.Hive常用内置函数
substring_index(str1, delim, -1) -- 用于常用带有规律字段的截取,根据分隔符delim,-1表示切割最后一段(并不是split讲每个delim分开的) replace(string, '被替换部分', '替换后的结果') trim('被删除字段' from 列名)
优化相关的内容暂时还是写在有道云上。
参考资源
1.《SQL必知必会》
2.《SQL进阶教程》
3.Leetcode刷题
4.网络不错的题录:1)SQL进阶与面试
5.Hive学习之路 (九)Hive的内置函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号