准确率、精确率、召回率、F值
准确率:正确的数量除以总数量
准确率(accuracy),是一个用来衡量分类器预测结果与真实结果差异的一个指标,越接近于1说明分类结果越准确。举个例子,比如现在有一个猫狗图片分类器对100张图片进行分类,分类结果显示有38张图片是猫,62张图片是狗,经与真实标签对比后发现,38张猫的图片中有20张是分类正确的,62张狗的图片中有57张是分类正确的,那么准确率是多少呢?显然就应该是 (20+57)/100=0.77 ,即分对的数量除以总的数量就这么简单,这也是准确率好理解的原因之一。
同时可以发现,对于这100张图片来说,其真实标签为狗75张,猫25张。那么现在问题就来了,假如某分类器使坏,对于输入的任何让本其结果都输出为狗,那么从整个结果来看就是狗的照片全都分对,猫的照片全都分错,准去率为 75/100=0.75 。可是仔细想想这有意义吗?若是猫狗照片数量为10和90,你啥也不做,就这么一搞准确率就到 0.9了,岂不无法无天?那我们应该这么避免这种情况呢?那就要轮到精确率和召回率登场了。
什么精确率(precision)与召回率(recall)呢?我们先用一个矩阵来把上面猫狗分类的结果给展示出来:
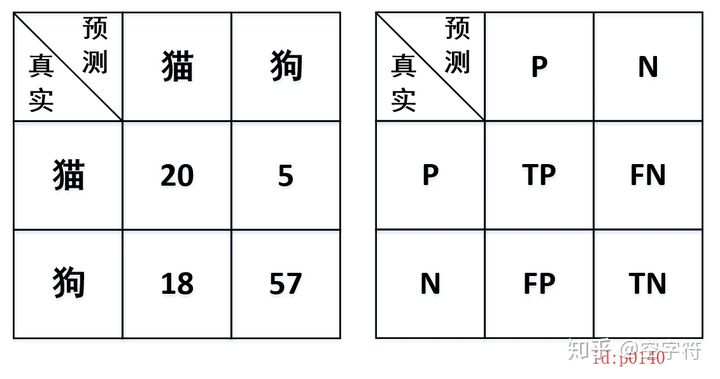
怎么去读这张表呢?首先从这张表可知:数据集中有25张猫的图片,75张狗的图片;同时对于左图20这个值,其含义是将猫预测为猫的数量为20,同理5表示将猫预测为狗的数量,18表示将狗预测成猫的数量,57表示将狗预测为狗的数量。衍生开就是,如右图所示:
- True Positive(TP):表示将正样本预测为正样本,即预测正确;
- False Positive(FP):表示将负样本预测为正样本,即预测错误;
- False Negative(FN):表示将正样本预测为负样本,即预测错误;
- True Negative(TN):表示将负样本预测为负样本,即预测正确;
图p0140这个矩阵就称为混淆矩阵(confusion matrix),同时我们可以得到如下计算公式分别为:准确率、精确率(查准率)、召回率、F值:

精确率:预测对的正样本在整个预测为正样本中的比重 ;理解为:预测为正样本的所有样本中,预测对了的概率
召回率:预测对的正样本在整个真实正样本中的比重 ;理解为:正样本的准确率,所有真实正样本中,预测对了的概率
可以看到,精确率计算的是预测对的正样本在整个预测为正样本中的比重,而召回率计算的是预测对的正样本在整个真实正样本中的比重。因此一般来说,召回率越高也就意味着这个模型找寻正样本的能力越强。但值得注意的是,通常在实际任务中,并不明确哪一类是正样本哪一类又是负样本,所以每个类别,都可以计算其各项指标:
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-score是Precision和Recall加权调和平均:

当参数α=1时,就是最常见的F1,也即
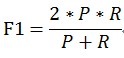
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。

对于上面的计算过程,也可以通过sklearn中的包来完成。
from sklearn.metrics import classification_report,confusion_matrix
y = [0]*25 + [1]*75
y_pre =[0]*20+[1]*5+[0]*18+[1]*57
print(confusion_matrix(y,y_pre))
print(classification_report(y,y_pre,target_names=['cat','dog']))
>>
[[20 5]
[18 57]]
precision recall f1-score support
cat 0.53 0.80 0.63 25
dog 0.92 0.76 0.83 75此时,通过这三个指标,我们再来对比下面的极端情况:

对于猫来说:精确率、召回率、F1分别为:0,0,0
对于狗来说:精确率、召回率、F1分别为:0.75,1,0.86
只用准确率:准确率为0.75
还有一个问题就是,既然有了精确率和召回率那还搞了F1干啥?这当然也是为了避免一些极端情况。还是以上面的数据为例,试想一下假如某个分类器说对于猫的识别,它的召回率能做到1,那么这算是厉害还是不厉害呢?可能厉害也可能不厉害,厉害就是当猫狗所有类别都分类正确的情况下,但这是及其困难;还有一种作弊的方式就是将所有的样本都预测成猫,那么这样将会得到如下混淆矩阵:
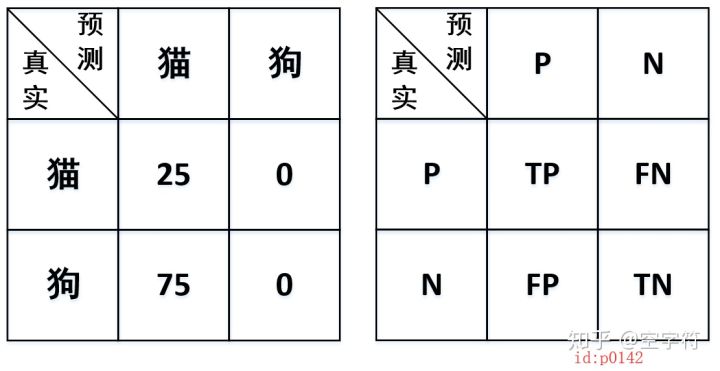
此时对于猫来说,其精确率、召回率、F1分别为:0.25,1,0.4
总结就是,通过引入精确率,召回率能够明显的解决只用准确率的不足之处,同时加入F-score能够解决召回率和精确率的不足之处。
3.NLP中的精确率、召回率和F-score

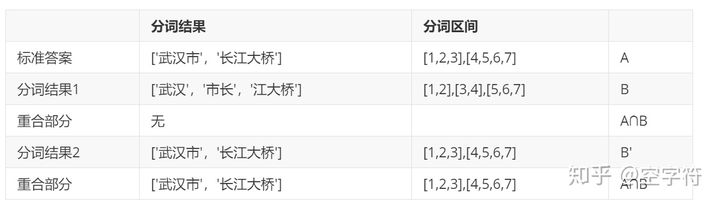
可以发现,重合部分就是正确部分;因此,对于分词结果1来说,精确率和召回率均为0,因为没有重合部分。而对于分词结果2来说都为1。下面再来看个例子:

此时的精确率为3/5=0.6: ,召回率为: 3/6=0.5
4. OOV Recall 与 IV Recall
OOV指的是“未登录词”(Out Of Vocabulary)的简称,也就是新词,已知词典中不存在的词。出现OOV的原因一方面可能确实是因为产生了有意义的新词而词典并没有收录;另一方面可能就是因为分词器产生的错误无意义的分词结果,这当然也不会出现在字典中。IV指的是“登陆词”(In Vocabulary),也就是已经存在字典中的词。而OOV Recall和IV Recall 分别指的就是OOV的召回率和IV的召回率。为了说明这两个召回率的具体含义,请先耐心看下面的详细例子:
标准分词 A:['结婚',' 的',' 和',' 尚未',' 结婚 ','的',' 都',' 应该',' 好好',' 考虑',' 一下',' 人生',' 大事']
标准区间 A:[1,2],[3,3],[4,4],[5,6],[7,8],[9,9],[10,10],[11,12],[13,14],[15,16],[17,18],[19,20],[21,22]
分词结果 B:['结婚',' 的','和尚','未结婚 ','的 ','都',' 应该',' 好好考虑',' 一下',' 人生大事']
分词区间 B:[1,2],[3,3],[4,5],[6,7,8],[9,9],[10,10],[11,12],[13,14,15,16],[17,18],[19,20,21,22]
重复词语 A∩B:['结婚',' 的',' 的',' 都',' 应该',' 一下']
重复区间 A∩B:[1,2], [3,3], [9,9],[10,10],[11,12],[17,18]
词典:['结婚', '尚未', '的', '和', '青年', '都', '应该', '好好考虑', '自己', '人生', '大事']

前面三项指标同第3节中的一样,不在赘述。从上面的计算过程可以看到,OOV召回率等于重复词区间未在词典中出现的词除以标准分词中未在词典中出现的词。需要注意的是重复词区间未在词典中出现的词就意味着未在字典中出现的新词是有意义的,只是字典没有收录而已;同理标准分词中未在词典中出现的词就更是如此。同时也可以将两者分别称为重复词区间有意义的新词和所有有意义的新词。有意义的新词越多也就表示你用来分词的字典收录越不全(可能也会因为词语的颗粒度大小造成),而OOV recall越低也就意味着词典分词器对有意义新词的发现或者说查找能力越低。

同理,从IV 召回率的计算公式可以发现重复词区间在词典中出现的词指的就是分词得到的正确部分(即正样本);标准分词中在词典中出现的词指的就是所有正样本。因此,IV 召回率就可以来衡量词典中的词被正确找回的概率。如果IV召回率低,就说明字典分词器连词典中的词汇都无法百分之百的发现或者找回,说明其消歧能力不好。例如“商品,和服,服务”三个词都在词典中,词典分词依然可能分布对句子”商品和服务“。
import re
def to_region(segmentation: str) -> list:
"""
将分词结果转换为区间
:param segmentation: 商品 和 服务
:return: [(0, 2), (2, 3), (3, 5)]
"""
region = []
start = 0
for word in re.compile("\\s+").split(segmentation.strip()):
end = start + len(word)
region.append((start, end))
start = end
return region
def prf(gold: str, pred: str, dic) -> tuple:
"""
计算P、R、F1
:param gold: 标准答案文件,比如“商品 和 服务”
:param pred: 分词结果文件,比如“商品 和服 务”
:param dic: 词典
:return: (P, R, F1, OOV_R, IV_R)
"""
A_size, B_size, A_cap_B_size, OOV, IV, OOV_R, IV_R = 0, 0, 0, 0, 0, 0, 0
A, B = set(to_region(gold)), set(to_region(pred))
A_size += len(A)
B_size += len(B)
A_cap_B_size += len(A & B)
text = re.sub("\\s+", "", gold)
for (start, end) in A:
word = text[start: end]
if word in dic:
IV += 1
else:
OOV += 1
for (start, end) in A & B:
word = text[start: end]
if word in dic:
IV_R += 1
else:
OOV_R += 1
p, r = A_cap_B_size / B_size * 100, A_cap_B_size / A_size * 100
return p, r, 2 * p * r / (p + r), OOV_R / OOV * 100, IV_R / IV * 100
if __name__ == '__main__':
dic = ['结婚', '尚未', '的', '和', '青年', '都', '应该', '好好考虑', '自己', '人生', '大事']
gold = '结婚 的 和 尚未 结婚 的 都 应该 好好 考虑 一下 人生 大事'
pred = '结婚 的 和尚 未结婚 的 都 应该 好好考虑 一下 人生大事'
print("Precision:%.2f Recall:%.2f F1:%.2f OOV-R:%.2f IV-R:%.2f" % prf(gold, pred, dic))5. 总结
此处一共介绍了精确率、召回率、F-score、OOV召回率、IV召回率,其中前面三种指标可以用来衡量任意一种分词器分词结果的好坏;而后两种指标则是用来衡量基于词典分词模型好坏的一个评估指标。同时,一定需要明白的是:精确率计算的是预测对的正样本数占整个预测为正样本数的比重,而召回率计算的是预测对的正样本占整个真实正样本的比重,而F-score则是对两者的一个调和平均。
摘自:https://zhuanlan.zhihu.com/p/100552669 侵删!!!
参考:
- 《自然语言处理入门》,何晗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号