吃西瓜—先磨刀之概率论
目录
一、什么是数据挖掘?
基于对大量的数据进行深度分析,发现其有价值的信息!利用这些信息提高企业预测分析与推断决策能力。针对不同用户进行个性化推荐,优化用户体验。我个人理解是,在大量数据中发现模式与规律,也就是咱们人类所说的知识,所以为什么叫机器学习?让机器像人类一样从一堆数据中学到知识!
数据挖掘所使用的方法论是什么?包括统计学、机器学习、数据库、云计算等等。所以在研究生生活开始之前我应该学习完李航老师的《统计学方法》、周志华老师的西瓜书《机器学习》,为以后研究打下深厚的基础。数据挖掘包括四大基本模型,包括分类、聚类、预测、关联四大模型。
二、概率基础
基础回顾
随机试验E:符合三个条件,1、相同条件下能够重复进行;2、试验结果不止一个但能明确试验所有可能;3、试验前无法确定结果但肯定是所有可能结果之一;例如掷骰子、王者排位。
样本空间S:随机试验E中所有可能的结果组合成的集合称为样本空间,例如掷骰子有 1、2、3、4、5、6种点数,这个集合为样本空间S。样本空间可以是无限的,例如到达教室的时间[8am,9am]。
样本点:样本空间中的每个结果或者说元素为样本空间,例如掷骰子 点数1 是一个样本空间。
基本事件:一个样本点事件为一个基本事件,基本事件我发再分割;通常把事件分为必然事件、偶然事件、不可能事件。
随机事件:若干个基本事件(样本点)组成,样本空间的子集,即在一定条件下可能发生也可能不发生的事件。
和事件AUB:A和B至少有一个发生。
差事件A-B:A发生但B不发生。、
积事件AnB:A和B同时发生的事件。
古典概型:样本空间是一个有限集合,且每个基本事件发生的概率相等。
条件概率
条件概率:P(B|A)=P(AB)/P(A) , 其实很好理解,A发生的条件下B发生的概率,样本空间缩减为事件A,而原来的事件为A、B交集。
乘法定理:P(AB)=P(B|A)*P(A) ,其实就是条件概率的逆推;理解为A、B交集的概率为:A出现的条件下B的概率 乘以 A的概率。
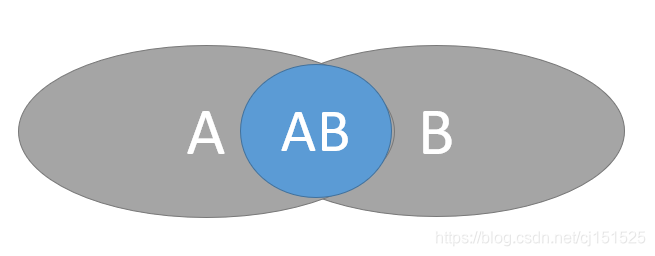
独立事件:P(AB)=P(A)*P(B); P(B|A)=P(B) ;
全概率公式
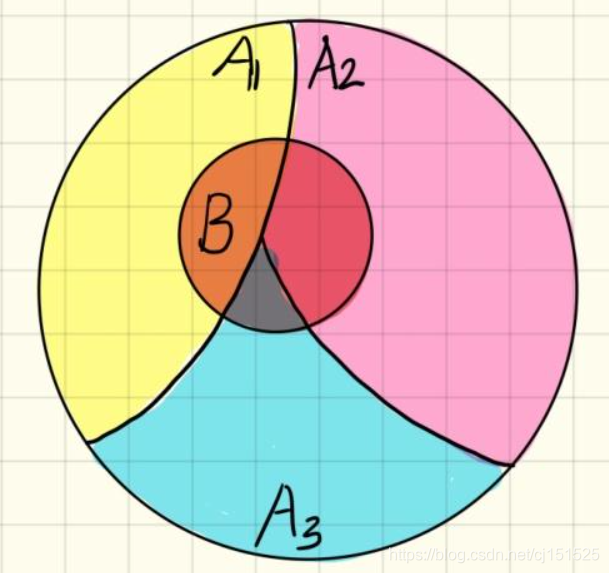
大圆为A事件,小圆为B事件,那么 P(B)=P(BA1)+P(BA2)+P(BA3); 所以有公式: , 根据条件概率公式又知道
, 所以在已知
的情况下,求P(B),即为全概率公式:
。用自己的语言描述就是:将B每一小块的概率加起来即为B的概率,而每一小块由条件概率求得!
贝叶斯公式
已知结果概率P(B)推原因概率,即第i个事件的条件概率,也称为后验概率公式。
, 分子使用乘法公式得到
,分母使用全概率公式得到
,即
。
三、随机变量
概率密度:描述连续型随机变量的取值的统计规律。
概率分布律:描述离散随机变量的取值的统计规律。
分布函数:连续型随机变量的区间概率,对概率密度求积分即可,即为概率密度的区间面积。F(x)=P(X<x) ;
四、数字特征
方差:度量随机变量和数学期望之间的偏离程度。 ,刻画随机变量取值的分散程度!
标准差:, 为了保证与原数据单位具有相同的量纲,对方差开平方就是标准差。
协方差:前提X,Y不相互独立,为了衡量两个变量间的相关程度或者联系。 ,其中
。
协方差矩阵:随机变量两两求协方差,对角线为自己的方差。
相关系数:在相同量纲下,衡量随机变量X和Y之间的相关程度协方差有一定作用,但是不同量纲下,一般使用相关系数来衡量,, [0.8,1] 极强相关,[0.6,0.8]强相关,[0,0.2]极弱相关,若为负数,则有负相关,-1 完全负线性相关,0 不存在线性关系。注意相关系数只能判断是否有线性关系,非线性关系无法确定!!!
相关系数矩阵:随机变量直接两两求相关系数,对角线为自己与自己的相关系数为1 。注意,相关系数与协方差主要区别就是是否消除量纲!!!
五、参数(总体样本的均值、方差、拟合函数的参数等等)估计
参数估计包括点估计与区间估计,点估计通常是从总体样本中取样,然后用样本的统计量估计未知参数,例如使用样本的均值估计总体均值。点估计仅仅是未知参数的近似值,而近似值的误差范围没有明确给出,这就缺乏一定可信度,而区间估计正好弥补了这一缺点。
最小二乘法:真实值与预测值之差的平方之和。求出偏差最小平方和,例如使用 f(x)=a+bx 进行拟合,,令偏导为0,解出函数参数a,b。
极大似然估计:寻找使事件发生概率最大的可能情况的参数估计方法。例如一个袋子有1000个黑、白球,请问黑球几何?我们随机取出100个,发现黑球72个,白球28个。现在我们知道了实验结果,需要估计参数黑球的个数及其白球的个数!什么情况下得到这个实验结果的参数能使得取得这个实验结果的概率最大?答案就是当袋子中黑球720个,白球280个的时候,得到这个实验结果的概率是最大的,所以得出了参数是,黑球720个,白球280个!
极大似然估计如何使用呢?分为离散型与连续型,其实都一样,核心思想就是假设参数为,然后将每一个样本概率累乘起来,离散:
,连续:
。然后在参数可能的范围之内寻找使得
最大的参数
即可,两边取对数求导即可求得
。
区间估计:由样本确定两个统计量 ,满足
,则区间
称之为
的置信水平
的置信区间,
与
分别是此置信区间的上下限。在多次等容量的抽取样本中,至少有
的区间包含
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号