k8s(六)--pod控制器 (二)
3、控制器实战
3.5、Daemonset
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph。
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash。
- 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond。
一个简单的用法是,在所有的 Node 上都存在一个 DaemonSet,将被作为每种类型的 daemon 使用。 一个稍微复杂的用法可能是,对单独的每种类型的 daemon 使用多个 DaemonSet,但具有不同的标志,和/或对不同硬件类型具有不同的内存、CPU要求。
编辑DaemonSet清单:
# vi DemonSet.yaml
apiVersion: apps/v1 kind: DaemonSet metadata: name: nginx-daemonset labels: app: daemonset spec: selector: matchLabels: name: nginx-daemonset template: metadata: labels: name: nginx-daemonset spec: containers: - name: nginx image: nginx:1.10 ports: - containerPort: 80
创建DaemonSet
# kubectl create -f nginx-daemonset.yaml # kubectl get ds -owide --show-labels # kubectl get pod -owide --show-labels

更新升级
# kubectl set image ds/nginx-daemonset nginx=nginx:1.21.3
3.6、Job
容器按照持续运行的时间可分为两类:服务类容器和工作类容器
服务类容器通常持续提供服务,需要一直运行,比如HTTPServer、Daemon等,Kubernetes的Deployment、ReplicaSet和DaemonSet都用于管理服务类容器。
工作类容器则是一次性任务,比如批处理程序,完成后容器就退出,对于工作类容器,我们使用Job。
Job负责处理仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而CronJob则就是在Job上加上了时间调度
Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always,Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话会陷入了死循环。
# vi job.yaml
apiVersion: batch/v1 kind: Job metadata: name: job-demo spec: template: metadata: name: job-demo spec: restartPolicy: OnFailure containers: - name: counter image: busybox command: - "bin/sh" - "-c" - "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
注:apiVersion不能用apps/v1
# kubectl create -f job.yaml # kubectl get jobs -owide

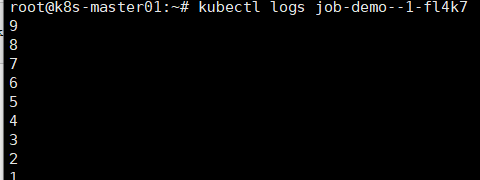
查看运行日志
# kubectl logs job-demo--1-fl4k7
3.7、CronJob
CronJob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和Linux中的crontab就非常类似了。
一个CronJob对象其实就对应crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 小时 日 月 周 要运行的命令
- 第1列分钟(0~59)
- 第2列小时(0~23)
- 第3列日(1~31)
- 第4列月(1~12)
- 第5列星期(0~7)(0和7表示星期天)
- 第6列要运行的命令
应用场景:
数据库备份、定期发送邮件
vi cronjob.yaml
apiVersion: batch/v1 kind: CronJob metadata: name: cronjob-demo spec: schedule: "*/1 * * * *" jobTemplate: spec: #completions: 3 #parallelism: 2 template: spec: restartPolicy: OnFailure containers: - name: hello image: busybox args: - "bin/sh" - "-c" - "for i in 9 8 7; do echo $i; done"
.spec.schedule :调度,必需字段,指定任务运行周期,格式同 Cron
.spec.jobTemplate :Job 模板,必需字段,指定需要运行的任务,格式同 Job.
- completions:设置Job成功完成Pod的总数,如果设置completions,则完成指定数量的pod后才会重新创建一个job继续执行定时任务
- parallelism: 并发执行job数
.spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错 过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
.spec.concurrencyPolicy :并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的 并发执行。只允许指定下面策略中的一种:
- Allow (默认):允许并发运行 Job
- Forbid :禁止并发运行,如果前一个还没有完成,则直接跳过下一个
- Replace :取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总 是允许并发运行。
.spec.suspend :挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始 执行的 Job 不起作用。默认值为 false 。
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit :历史限制,是可选的字段。它 们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相 关类型的 Job 完成后将不会被保留。
创建cronjob
# kubectl apply -f cronjob.yaml # kubectl get cronjob -owide --show-labels # kubectl get job -owide --show-labels # kubectl get pod -owide -w
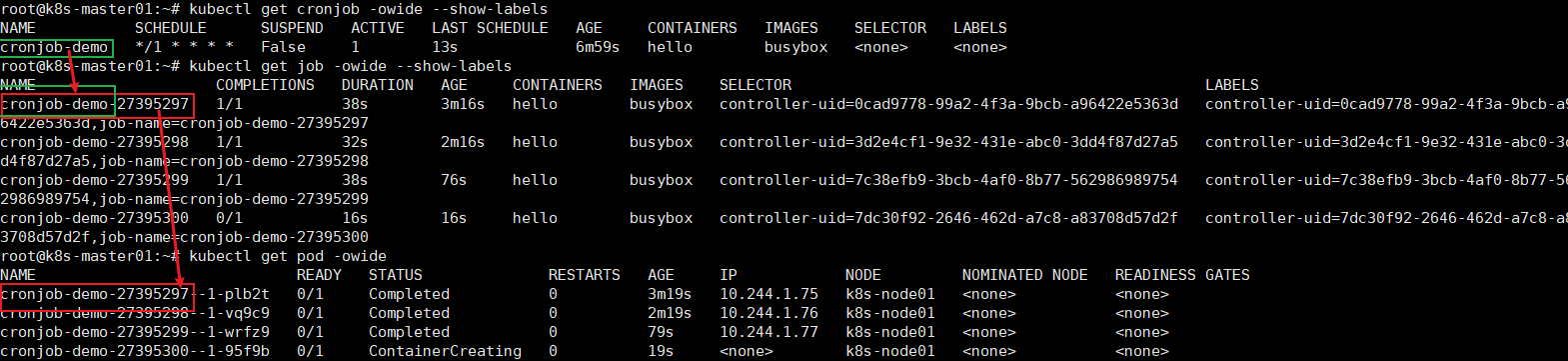
因为没设置completions值,每次执行pod时都对应一个新的job
3.8、Statefulset
statefulset简称sts,是pod资源控制器的一种实现,用于部署和扩展有状态应用的pod资源,确保他们的运行顺序及每个pod资源的唯一性。
其与ReplicaSet控制器不同的是,虽然所有pod对象都基于同一个spec配置所创建,但statefulset需要为每个pod维持一个唯一且固定的标识符,必要时还要为其创建专用的存储卷。
StatefulSet适用于具有以下特点的应用场景:
- 稳定且唯一的网络标识符,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 稳定且持久的存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 有序、优雅地部署和扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序、优雅地删除和终止,有序删除(即从N-1到0)
- 有序而自动地滚动更新
一般来说,一个典型、完整可用的StatefulSet通常由三个组件构成:Headless Service、StatefulSet和volumeClaimTemplate。
- Headless Service用于为pod资源标识符生成可解析的DNS资源记录
- StatefulSet用于管控pod资源
- volumeClaimTemplate则基于静态或动态的PV供给方式为pod资源提供专有且固定的存储。
再次强调,StatefulSet的部署和扩缩容需要注意如下几点:
- StatefulSet创建pod或扩容的时候是串行化按照顺序执行,从0创建到n-1,当且仅当一个pod运行成功进入就绪状态的时候,下一个pod才会开始创建(基于Init container来实现之前的pod必须是running或ready状态)。
- 删除pod的时候(比如缩容),按照相反的方向操作,当且仅当一个pod彻底停止之后,下一个pod才会开始停止过程,即先删除pod n-1,在删除pod n-2,直到pod0。
在k8s-node-04节点(192.168.6.24)上配置挂载点
# mkdir -p /data/nfshdd{1..3}
# chmod -R 777 /data/
# sudo tee /etc/exports <<-'EOF'
> /data/nfshdd1 *(rw,sync,no_subtree_check,no_root_squash)
> /data/nfshdd2 *(rw,sync,no_subtree_check,no_root_squash)
> /data/nfshdd3 *(rw,sync,no_subtree_check,no_root_squash)
> EOF
# sudo /etc/init.d/rpcbind restart
# /etc/init.d/nfs-kernel-server restart
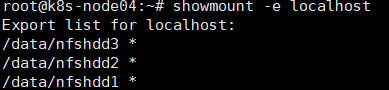
# showmount -e localhost
在k8s-master(192.168.6.10)节点编辑创建pv的资源清单
vi sfs-pv.yaml
apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs-strong spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: pv-nfs nfs: path: /data/nfshdd1 server: 192.168.6.24 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs-fast spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: pv-nfs nfs: path: /data/nfshdd2 server: 192.168.6.24 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs-slow spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: pv-nfs nfs: path: /data/nfshdd3 server: 192.168.6.24 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs-common spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: pv-aws nfs: path: /data/nfshdd3 server: 192.168.6.24
创建pv
# kubectl apply -f sfs-pv.yaml
# kubectl get pv

创建无头服务svc和Statefulset
编辑清单vi sfs.yaml
apiVersion: v1 kind: Service metadata: name: nginx-headless labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx serviceName: "nginx-headless" replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.21.3 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] storageClassName: "pv-nfs" resources: requests: storage: 2Gi
只有符合volumeClaimTemplates声明的pvc匹配规则的pv才会被绑定
他们会匹配存储空间必须大于等于2G,匹配pv的类名,匹配读写模式这几个规则
# kubectl apply -f sfs.yaml # kubectl get svc # kubectl get Statefulset -owide # kubectl get pvc -owide # kubectl get pv -owide # kubectl get pod -owide
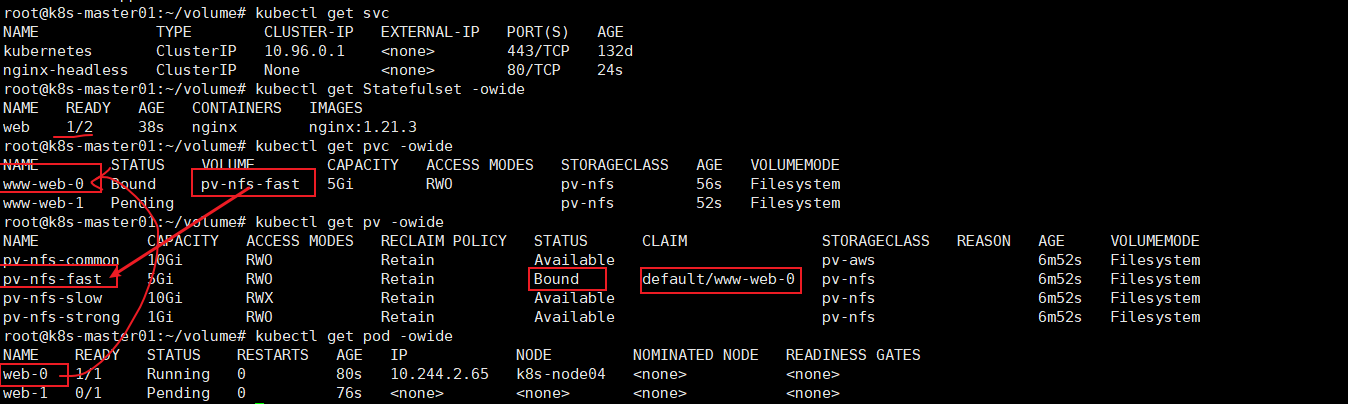
发现只创建成功了一个pod
查看失败原因
# kubectl describe pod web-1

这是因为pvc找不到匹配的pv进行绑定导致
接下来把名称为pv-nfs-slow的pv修复成符合pvc声明规则的pv
# kubectl delete pv pv-nfs-slow #删除指定名称pv
编辑清单sfs-pv.yaml,修改名称为pv-nfs-slow的pv读写模式为ReadWriteOnce
apiVersion: v1 kind: PersistentVolume metadata: name: pv-nfs-slow spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: pv-nfs nfs: path: /data/nfshdd3 server: 192.168.6.24
重新应运清单
# kubectl apply -f sfs-pv.yaml # kubectl get pod -owide # kubectl get pvc # kubectl get pv -owide # kubectl get pv -owide # kubectl get svc -owide # kubectl get Statefulset -owide
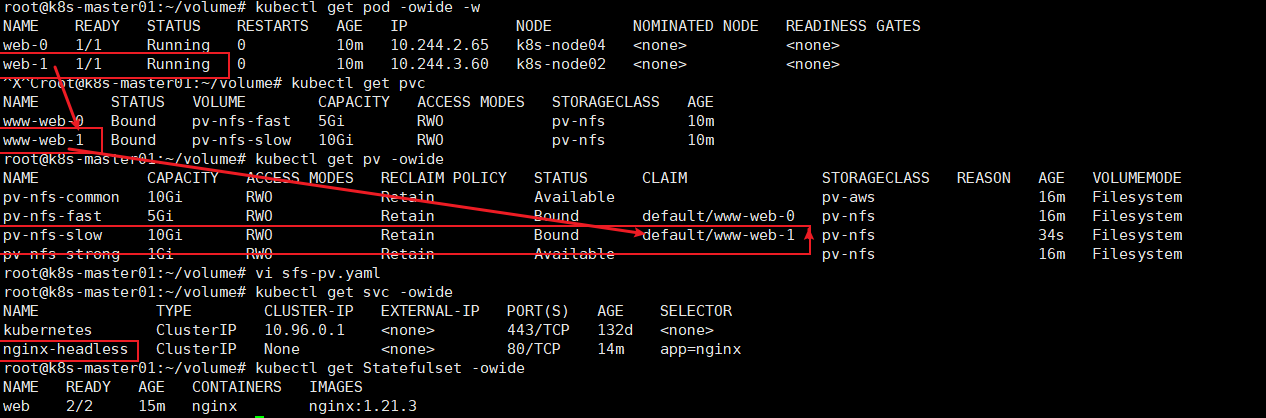
查看名为pv-nfs-fast的pv挂载点
# kubectl describe pv pv-nfs-fast
到nfs服务器192.168.6.24相应的挂载点创建文件
# echo pv-nfs-fast>/data/nfshdd2/index.html
同理在另一个pv-nfs-slow挂载点创建文件
# echo pv-nfs-slow>/data/nfshdd3/index.html
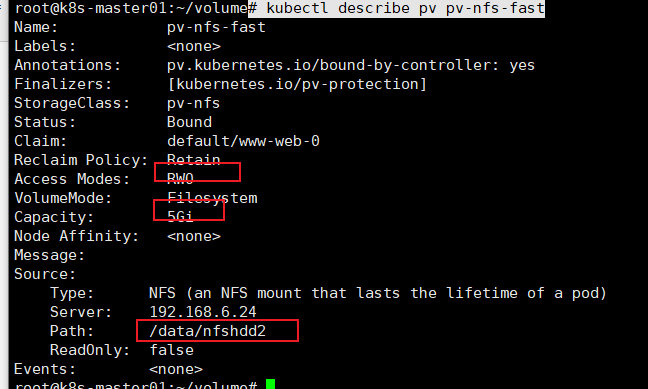
此时请求这个文件
# kubectl get pod -owide # curl 10.244.2.65

删除web-0这个pod
# kubectl delete pod web-0 # kubectl get pod -owide # curl 10.244.2.68

删除pod后发现又启动了一个pod,地址信息已经发生概念,但数据没丢失,这就是Statefulset有状态控制器的特性
关于Statefulset:
1)、匹配 Pod name ( 网络标识 ) 的模式为:$(statefulset名称)-$(序号),比如上面的示例:web-0,web-1

2)、StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless server name).default.svc.cluster.locali,也就意味着服务间是通过Pod域名来通信而非 Pod IP,因为当Pod所在Node发生故障时, Pod会被飘移到其它 Node上,Pod IP 会发生变化,但是 Pod 域名不会有变化
# kubectl exec -it web-0 -- /bin/bash -c "cat /etc/hosts"

# kubectl exec web-0 -it -- /bin/bash -c "ping web-0.nginx-headless.default.svc.cluster.locali"

注意,若容器无ping命令,可更换apt源后安装ping
#cat /etc/apt/sources.list<<-'EOF' deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse EOF" #apt-get update #apt-get -y install inetutils-ping
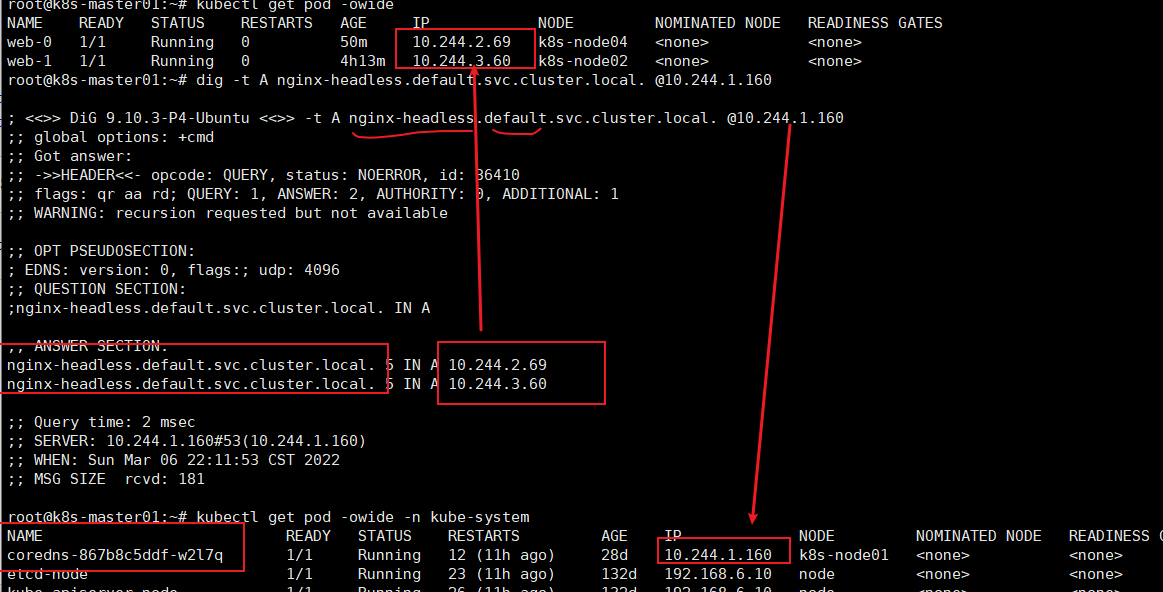
3)、StatefulSet 使用Headless服务来控制 Pod 的域名,这个域名的格式为:$(service name).$(namespace).svc.cluster.local,其中,“cluster.local” 指的是集群的域名
# dig -t A nginx-headless.default.svc.cluster.local. @10.244.1.160
4)、根据volumeClaimTemplates为每个Pod创建一个pvc,pvc的命名规则匹配模式:(volumeClaimTemplates.name)-(pod_name)
# kubectl get pvc # kubectl get pod


5)、除Pod不会删除其pvc,手动删除pvc将自动释放pv
# kubectl delete -f sfs.yaml # kubectl get pv -owide # kubectl delete pvc --all # kubectl get pv -owide
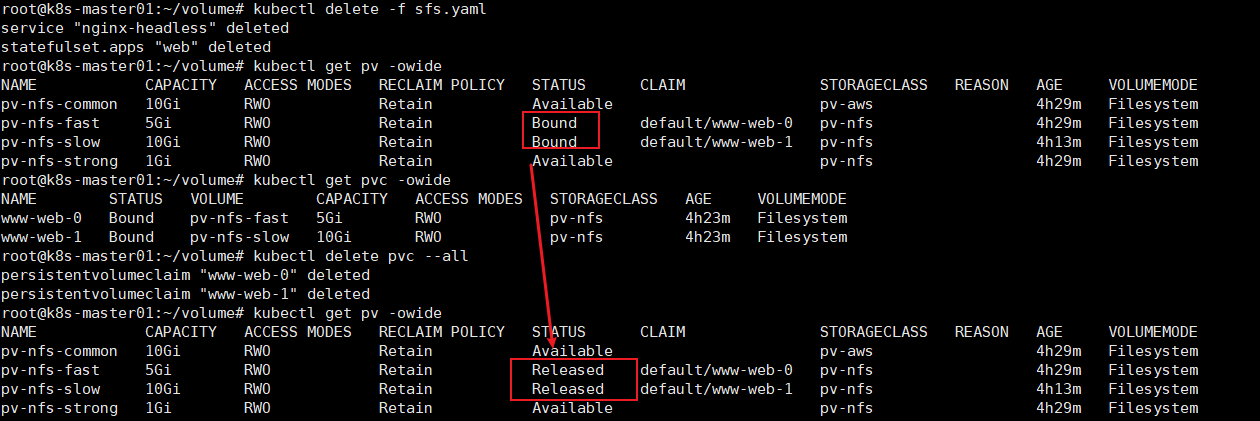
pv只是被释放了,但还不能被其它pvc申请,因为它不是Avaliable状态,可以需要删除pv,重新创建
# kubectl delete pv pv-nfs-fast # kubectl delete pv pv-nfs-slow # kubectl apply -f sfs-pv.yaml # kubectl get pv -owide
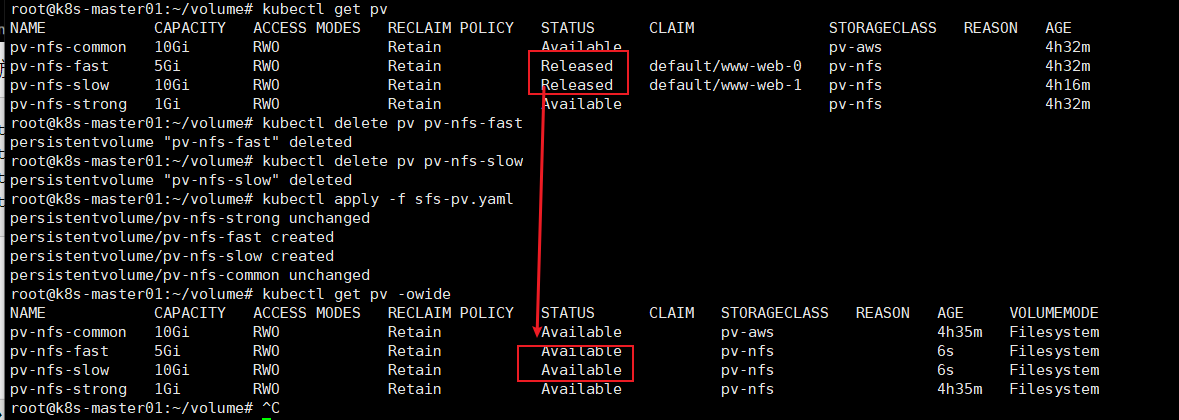
还有另一种方式
# kubectl get pv pv-nfs-fast -oyaml
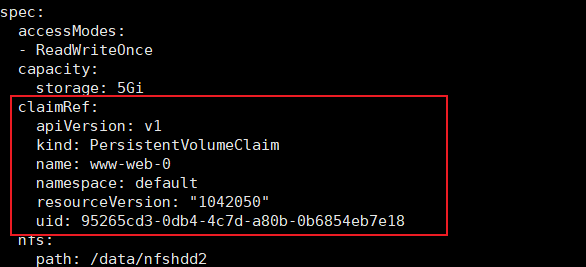
发现一直有使用者信息,把它删除
# kubectl edit pv pv-nfs-fast
# kubectl edit pv pv-nfs-slow
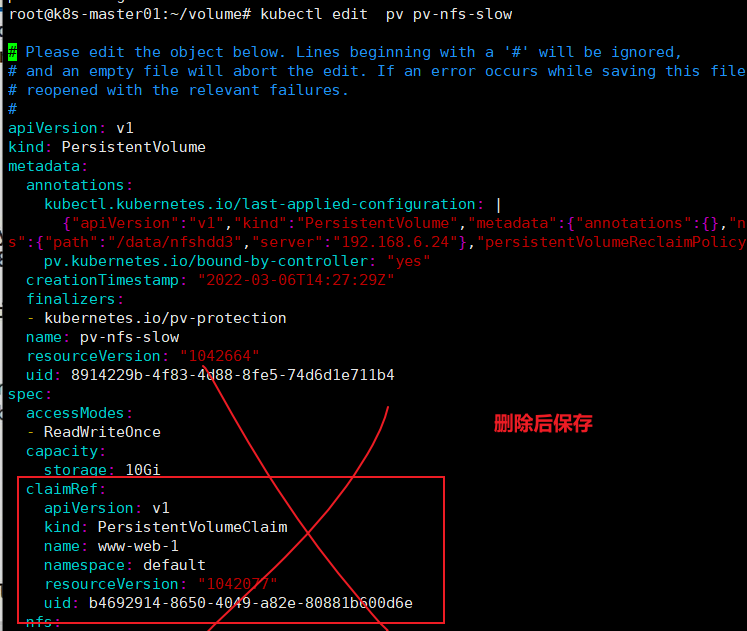
删除后再次查看pv状态
# kubectl get pv -owide

发现pv又可以被pvc重新申请了
Statefulset的启停顺序:
有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到N-1)并且,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态。
有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0。
有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
删除实验
# kubectl apply -f sfs.yaml # kubectl get pod -owide -w
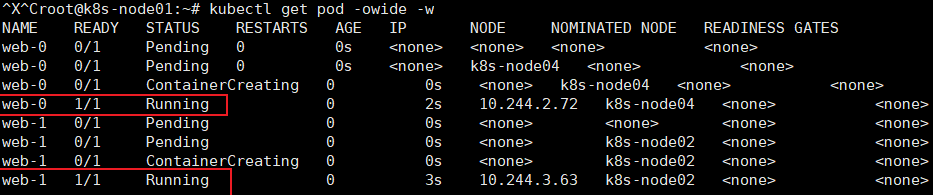
发现先创建web-0,再创建web-1,那删除一定是先删web-1.再删web-0
# kubectl delete -f sfs.yaml # kubectl get pod -owide -w
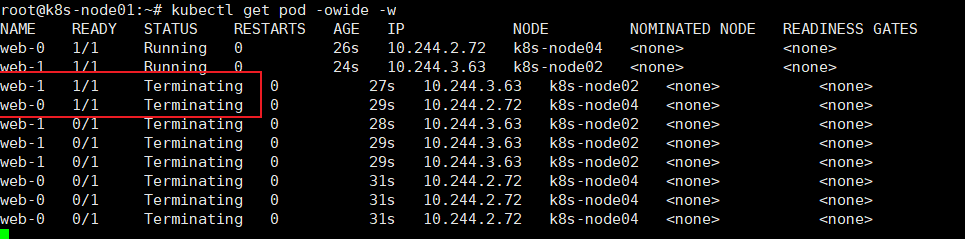

 浙公网安备 33010602011771号
浙公网安备 33010602011771号