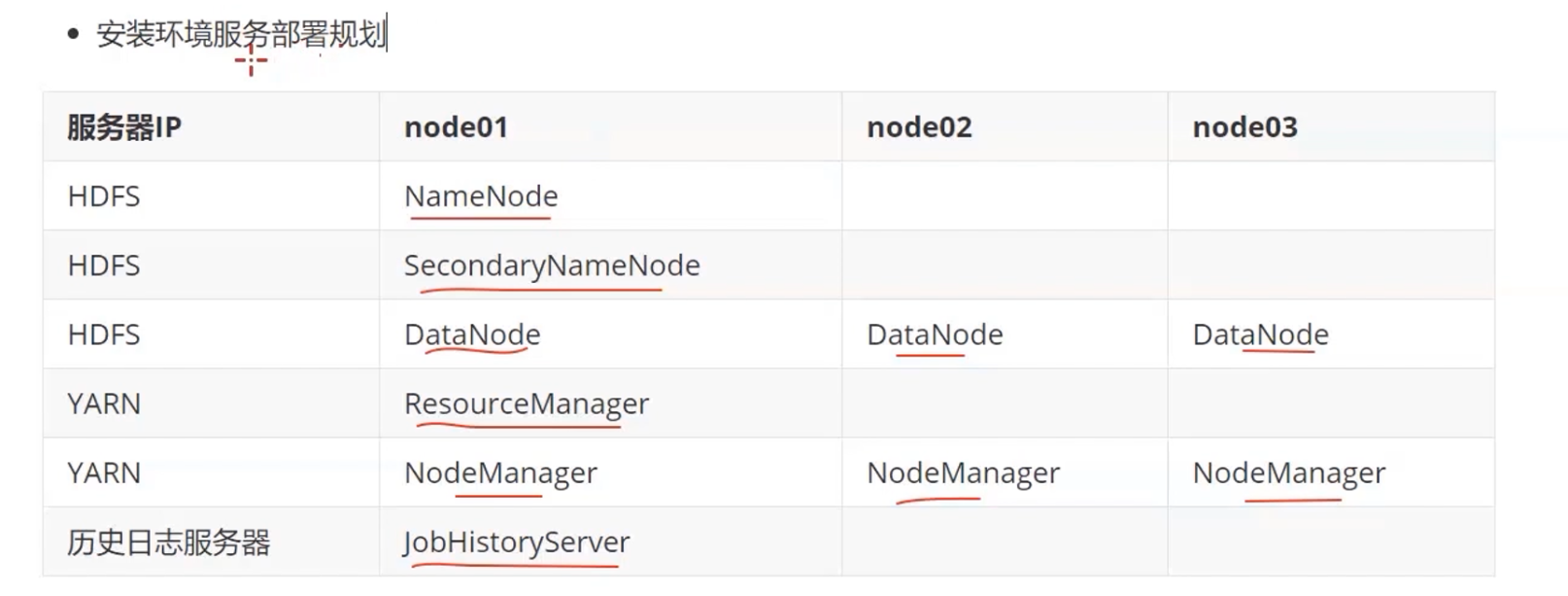
如何安装hadoop集群
三台机器上传压缩包并解压
cd /kkb/soft/
tar -xvzf hadoop-3.14.tar.gz -C /kkb/install
bin/hadoop checknative #查看一下openssl的状态如果为false 那么所有的机器都需要在线安装 openssl-devel
sudo yum -y install openssl-devel #三台机器都要装
mv hadoop-3.14 hadoop3 #修改一下项目名称
修改hadoop-env.sh
cd /kkb/install/hadoop3/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/kkb/install/jdk
修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/kkb/install/hadoop3/hadoopDatas/tempDatas</value>
</property>
<!--缓冲区大小,实际工作中根据服务器性能动态调整:默认值为4096-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶回收,单位分钟:默认值0-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
<!--namenode保存fsimage路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop3/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///kkb/install/hadoop3/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.datanode.edits.dir</name>
<value>file:///kkb/install/hadoop3/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.datanode.checkpoint.dir</name>
<value>file:///kkb/install/hadoop3/hadoopDatas/dfs/nn/snn/name</value>
</property>
<property>
<name>dfs.datanode.checkpoint.edits.dir</name>
<value>file:///kkb/install/hadoop3/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MARRED_HOME=${HADOOP HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MARRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MARRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
修改yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改workers
node01
node02
node03
创建文件存放目录
mkdir -p /kkb/install/hadoop3/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop3/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop3/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop3/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop3/hadoopDatas/dfs/nn/snn/name
mkdir -p /kkb/install/hadoop3/hadoopDatas/dfs/nn/snn/edits
安装包的分发scp与rsync
scp 安全拷贝
cd /kkb/install
scp -r hadoop3/node2:$PWD
scp -r hadoop3/node3:$PWD
rsync -av /kkb/soft/ hadoop@node02:/kkb/soft/
配置环境变量
sudo vim /etc/profile
export HADOOP_HOME=/kkb/install/hadoop3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
格式化集群
要启动hadoop集群,需要启动HDFS 和YARN两个集群
注意:首次启动HDFS时,必须对其进行格式化操作,本质是一些清理和准备工作,因为此时的HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要
node1执行一遍即可
hdfs namenode -format
启动集群
在hadoop目录下
start-dfs.sh --启动hdsf
start-yarn.sh --启动yarn
mapred --daemon start historyserver --启动历史服务
关闭集群
stop-dfs.sh --启动hdsf
stop-yarn.sh --启动yarn
mapred --daemon stop historyserver
验证集群安装
hdfs 集群访问地址
192.168.12.129:9870
yarn 集群访问地址
192.168.12.129:8088
jobhistory访问地址
192.168.12.129:19888
运行一个mr例子
hadoop jar /kkb/install/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号