

Python 多线程
一,进程 VS 线程
通俗易懂的解释:对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,
打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。进程是很多资源的集合。
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,
就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
总言之,进程是由若干线程组成的,一个进程至少有一个线程
进程之间的数据不共享,线程之间的数据共享
多进程之间怎么传输数据? 进程之间的数据不是共享的,需要借助第三方组件,用消息队列或者redis
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
二,多线程
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
实例一:
import time ,threading
def loop():
print('thread %s is running...'%threading.current_thread().name)
n = 0
while n <5:
n += 1
print('thread %s >>> %s'%(threading.current_thread().name,n))
time.sleep(1)
print('thread %s ended'%threading.current_thread().name)
print('thread %s is running..'%threading.current_thread().name)
t = threading.Thread(target= loop,name= 'LoopThread')
t.start()
# t.join()#主线程等待子线程
print('thread %s ended'%threading.current_thread().name)
输入结果:
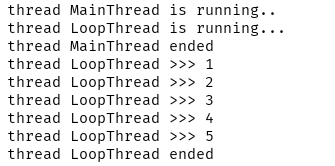
等待子线程结束 (取消 t.join()) 输出结果:
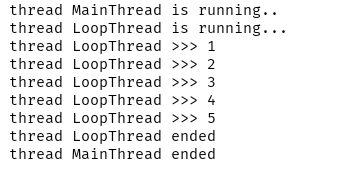
实例二:
import threading
import time
import requests
def downHtml(url,name):
print('thread %s is running...' % threading.current_thread().name)
conent = requests.get(url).content
f = open(name+'.html','wb')
f.write(conent)
f.close()
print('thread %s ended' % threading.current_thread().name)
urls = [
['nnzhp','http://www.nnzhp.cn'],
['dsx','http://www.imdsx.cn'],
['besttest','http://www.besttest.cn']
]
print('thread %s is running...'%threading.current_thread().name)
start_time = time.time()
threads = [] #存放刚才启动线程
for url in urls:
t = threading.Thread(target=downHtml,args=(url[1],url[0]))
t.start()
threads.append(t)
# for t in threads: #等待3个子线程
# t.join() #主线程等待子线程
end_time = time.time()
print('thread %s ended'%threading.current_thread().name)
print(end_time-start_time)
输出结果:
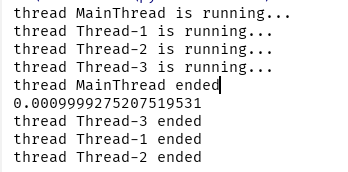
等待子线程结束,输出结果:
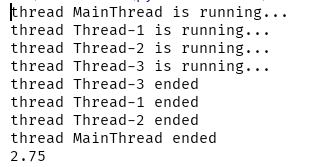
实例三:
import threading
urls = list(range(100))
# 100个 启动5个线程
def p(urls):
for u in urls:
print(u)
#有100个数据,启动5个线程,每个线程分20个数据,怎么把这20个数据分别传给每个线程
for i in range(5):
# urls[:20] 每次取的值
# urls[20:40]
# urls[40:60]
# urls[60:80]
# urls[80:]
for i in range(5):
t = threading.Thread(target=p, args=(urls[i * 20:(i + 1) * 20],))
t.start()
三,线程锁
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,
所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
线程锁就是很多线程一起在操作一个数据的时候,可能会有问题,就要把这个数据加个锁,同一时间只能有一个线程操作这个数据。
实例一:
# 加锁是为了多线程的时候同时修改一个数据的时候 有可能会导致数据不正确
# python3里面锁 你不加也无所谓,它会自动的给你加上锁
import threading
from threading import Lock
num = 0
lock = Lock() #申请一把锁
def run():
print('thread %s is running...' % threading.current_thread().name)
global num
lock.acquire() # 获取锁
try:
num += 1
finally:#用try...finally来确保锁一定会被释放
lock.release() # 释放锁
print('thread %s ended' % threading.current_thread().name)
list = []
print('thread %s is running...' % threading.current_thread().name)
for i in range(10):
t = threading.Thread(target=run)
t.start()
list.append(t)
for t in list:
t.join()
print('thread %s ended'%threading.current_thread().name)
print('over',num)
输出结果:over 10
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,
包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,
并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
四,守护线程
如果你设置一个线程为守护线程,就表示你在说这个线程是不重要的,在进程退出的时候,不用等待这个线程退出。
如果你的主线程在退出的时候,不用等待那些子线程完成,那就设置这些线程的daemon属性。
即在线程开始(thread.start())之前,调用setDeamon()函数,设定线程的daemon标志。(thread.setDaemon(True))就表示这个线程“不重要”。
如果你想等待子线程完成再退出,那就什么都不用做,或者显示地调用thread.setDaemon(False),设置daemon的值为false。
新的子线程会继承父线程的daemon标志。整个Python会在所有的非守护线程退出后才会结束,即进程中没有非守护线程存在的时候才结束。
实例一:
import threading
import time
def pz():
print('thread %s is running...' % threading.current_thread().name)
time.sleep(2)
print('thread %s ended' % threading.current_thread().name)
threads = []
print('thread %s is running...' % threading.current_thread().name)
for i in range(10):
t = threading.Thread(target=pz)
t.setDaemon(True)#设置子线程为守护线程
# 守护线程就是,一旦主线程执行结束,那么子线程立刻结束,不管子线程有没有运行完
t.start()
threads.append(t)
# for t in threads:
# t.join() #如果主线程等待子线程的话,那么设置的守护线程就不好使了
print('thread %s ended' % threading.current_thread().name)
输出结果:
五,线程池
1,安装与简介
pip install threadpool pool = ThreadPool(poolsize) requests = makeRequests(some_callable, list_of_args, callback) [pool.putRequest(req) for req in requests] pool.wait() 第一行定义了一个线程池,表示最多可以创建poolsize这么多线程;
第二行是调用makeRequests创建了要开启多线程的函数,以及函数相关参数和回调函数,其中回调函数可以不写,default是无,也就是说makeRequests只需要2个参数就可以运行;
第三行是将所有要运行多线程的请求扔进线程池,[pool.putRequest(req) for req in requests]等同于
for req in requests: pool.putRequest(req)
第四行是等待所有的线程完成工作后退出。
实例一:
import threadpool
def say(num):
print(num)
res = list(range(101))
pool = threadpool.ThreadPool(10)
#创建一个线程池,大小为10
reqs = threadpool.makeRequests(say,res)#生成线程要执行的所有线程
# for req in reqs:
# pool.putRequest(req) #实际才去执行的
[ pool.putRequest(req) for req in reqs]
pool.wait() #等待 其他线程执行结束
实例二: 线程池封装
import threadpool,asyncio
class MyPool(object):
def __init__(self,func,size=20,data=None):
self.func = func
self.size = size
self.data = data
def pool(self):
pool = threadpool.ThreadPool(self.size)#创建一个线程池,指定大小
reqs = threadpool.makeRequests(self.func,self.data)
#生成请求,分配数据
[pool.putRequest(req) for req in reqs]
#执行函数
pool.wait()
#等待线程执行完成
def down(num):
print(num)
my = MyPool(func=down,data=[1,2,3,4,5,6,7])
my.pool()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号