
Laplacian score 用于特征选择
监督学习,过滤,特征加权
第一个问题就是,怎样定义一个"好的"的特征?
首先我们尊重数据,数据是大爷,所以一个好的特征得到的结果应该和数据相吻合。即如果原数据中两点相近,那么在该特征下两点也应该相近。
其次,好的特征应该能将类之间分开,那么如果一个特征的跨度越到,我们认为这个特征就就具有好的分类特性,衡量这个跨度的就是方差,所以就要有一个大的方差。
Laplacian score 的方法这样定义一个特征的权重值,
其中
其中t 为一个给定值
为什么会有Sij?
我认为Sij 度量的是Xi 和Xj 之间的距离,所以就为分析某一个特性的时候带入了整体感……
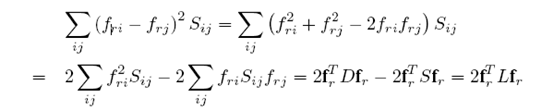
下面再化简
根据一个叫做spectral graph thery 的理论可以用对焦矩阵D来估计
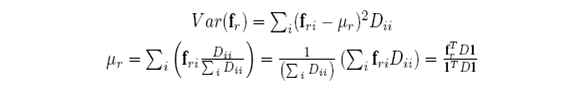
所以就有
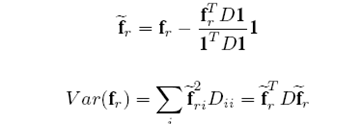
可以证明
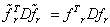
所以
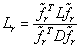
所以Laplacian score的算法流程为
STEP1 : 用所有的数据建立一个图,将相邻的两个点相连。两个点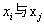 是相连的,如果
是相连的,如果
-
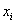 是
是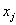 的K近邻,
的K近邻, 亦然
亦然 -
如果是监督学习,
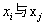 是同一类
是同一类
STEP2 : 计算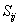 。对于相邻的两点
。对于相邻的两点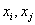


其中 t是给定的一个值,
STEP3 :对于第r个特征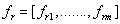 ,
,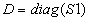 ,
,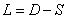 ;
;
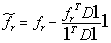
STEP4 : 最后
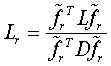
总结:
Laplacian score 算法可以说是fisher score的推广情况。这个算法比较有效的衡量了各个特征的权重,优先选择权重比较小的那些。但是这个算法没有衡量各个特之间相互的硬性,有可能会选取冗余特征。
