Redis 源码解析 9:五大数据类型之集合
集合对象的编码有两种:intset 和 hashtable
编码一:intset
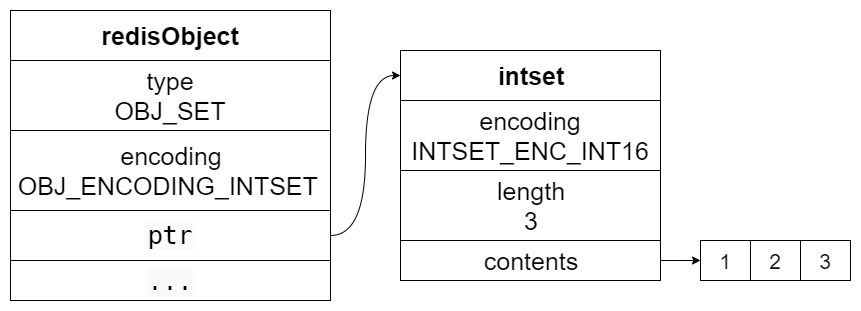
intset 的结构
整数集合 intset 是集合底层的实现之一,从名字就可以看出,这是专门为整数提供的集合类型。
其结构定义如下,在 intset.h:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
contents中的元素,按照从小到大排序,并且不存在重复项。虽然元素定义是int8_t类型,但实际上,contents存的元素类型取决于encodingencoding有几个类型,定义在intset.c:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
| encoding | 类型 | 字节 |
|---|---|---|
| INTSET_ENC_INT16 | int16_t | 2 |
| INTSET_ENC_INT32 | int32_t | 4 |
| INTSET_ENC_INT64 | int64_t | 8 |
下图展示了包含了 1、2、3 三个整数元素的集合结构:
常见操作源码分析
源码在
intset.c中
1. 创建空集合
创建一个空的 intset,一开始的编码是最小的 INTSET_ENC_INT16
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}
2. 搜索
因为集合中的整数存的是有序的,所以查找是用二分查找,时间复杂度 \(O(nlogn)\)
uint8_t intsetFind(intset *is, int64_t value) {
uint8_t valenc = _intsetValueEncoding(value);
// 如果 value 的编码大于集合的编码,那肯定是不存在的
// intsetSearch 是更底层的搜索,实现源码在下面,是个二分查找
return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
}
// 集合搜索,是二分查找。
// 如果找到了,返回1,并且把位置设置到 pos 变量中
// 如果找不到,返回0,可以插入值的位置设置到 pos 变量中
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
// 数组判空
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
// 看是否比最大的大或者比最小的小,这种情况也直接返回不存在
if (value > _intsetGet(is,max)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
// 二分查找
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
3. 指定位置获取
// 如果获取得到,返回1,找到的值设置进 value 变量
// 如果获取不到,返回 0
uint8_t intsetGet(intset *is, uint32_t pos, int64_t *value) {
if (pos < intrev32ifbe(is->length)) {
*value = _intsetGet(is,pos);
return 1;
}
// 位置如果大于长度,肯定就获取不到的
return 0;
}
static int64_t _intsetGet(intset *is, int pos) {
// 根据编码获取
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
}
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
// ...
// 根据编码的长度,从对应的位置后拷贝对应的字节返回
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64));
memrev64ifbe(&v64);
return v64;
} else if (enc == INTSET_ENC_INT32) {
// ...
return v32;
} else {
// ...
}
}
4. 插入
插入的步骤如下:
- 检查如果插入的元素的编码大于集合编码,进行升级并插入
- 如果不需要升级,检查元素是否存在,如果存在,则直接返回
- 如果元素不存在,则扩容,在元素对应的位置插入值(它后面的元素则都往后挪)
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
// 插入的元素的编码
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
// 如果插入的元素的编码比当前集合的编码大,需要进行升级
if (valenc > intrev32ifbe(is->encoding)) {
return intsetUpgradeAndAdd(is,value);
} else {
// 先查找看元素已存在,如果存在,则直接返回
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
// 扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 将 pos 后的内存块向后挪动一个位置,给新值腾空间
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
// 把新值设置进 pos 位置上
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from;
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t);
} else if (encoding == INTSET_ENC_INT32) {
// ...
} else {
// ...
}
memmove(dst,src,bytes);
}
5. 升级
当 intset 插入元素的时候,会先检测元素的长度,判断元素应该属于什么编码(encoding)。
如果当前元素的编码,大于 intset 的编码(整个集合最长的编码),集合将进行升级后,才添加元素。
升级整数集合并添加新元素共分为 3 步进行:
- 根据新元素的编码,扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
// 升级并插入新值
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 当前编码
uint8_t curenc = intrev32ifbe(is->encoding);
// 新的编码
uint8_t newenc = _intsetValueEncoding(value);
// 当前元素个数
int length = intrev32ifbe(is->length);
// value 的编码比其他的都大,那么这个 value 不是最大值就是最小值。
// 如果是最大值就放在数组最后,最小值就放在数组最前面
int prepend = value < 0 ? 1 : 0;
// 设置 encoding 属性为新编码
is->encoding = intrev32ifbe(newenc);
// 根据新编码给扩展集合需要的空间,实现源码在下面
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 从尾到头依次遍历挪动原来的值。为什么不从头到尾呢?因为数组是同一个,从头到尾会覆盖原来的值
while(length--)
// _intsetGetEncoded(is,length,curenc) 表示根据编码和位置获取值
// prepend 为了确保如果 value 是最小的值,那么前面会留一个空位置
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
if (prepend)
// 当 value 是最小值时,放在第一个空位
_intsetSet(is,0,value);
else
// 当 value 是最大值,放在最后一个位置
_intsetSet(is,intrev32ifbe(is->length),value);
// 长度加 1
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
// 整数集合重新分配内存
static intset *intsetResize(intset *is, uint32_t len) {
// 根据编码算出集合需要的空间
uint32_t size = len*intrev32ifbe(is->encoding);
// 分配内存
is = zrealloc(is,sizeof(intset)+size);
return is;
}
6. 降级
并没有降级
7. 删除
删除的步骤如下:
- 找到值的位置
pos - 把
pos后面的元素向前挪,覆盖掉pos上的元素 - 缩容:长度减一
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
// 查找值的位置
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) {
uint32_t len = intrev32ifbe(is->length);
if (success) *success = 1;
// 把删除位置后面的元素都挪到前面来,直接覆盖掉 pos 的元素
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos);
// 再缩容
is = intsetResize(is,len-1);
is->length = intrev32ifbe(len-1);
}
return is;
}
编码二:hashtable
hashtable 编码用的是字典 dict 作为底层实现,关于 dict,具体的前文 Redis 设计与实现 4:字典 dict 已经写了,包括了 dict 基本操作的源码解读。
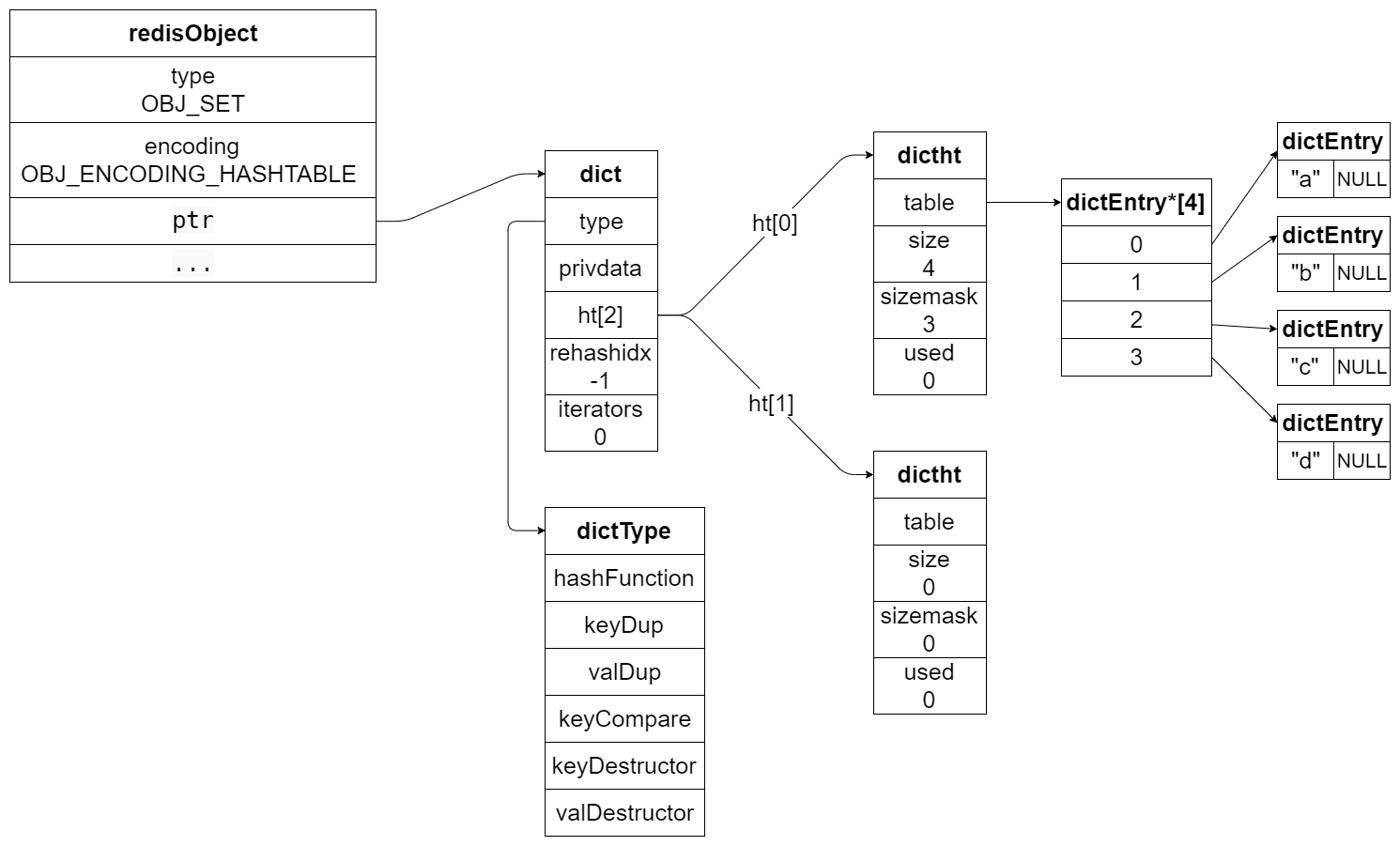
下图展示了包含 "a"、"b"、"c"、"d" 四个元素的集合结构:
编码的转换
当集合对象满足以下两个条件时,采用 intset 编码:
- 所有元素都是整数
- 元素数量不超过512个(用通过
set-max-intset-entries配置项配置)
不能同时满足以上两个条件,则采用 tablehash 编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号