Redis 源码解析 6:五大数据类型之字符串
前文 Redis 设计与实现 2:Redis 对象 说到,五大数据类型都会封装成 RedisObject。
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
// ...
void *ptr; // 指向具体底层数据的指针
} robj;
不同数据类型的主要区别就是 type 和 encoding 属性的差异,同一种数据类型,有不同的编码。
一、编码类型
字符串的编码有raw、embstr、int三种。
raw用于长字符串。embstr用于短字符串。int用于整数类型。
定义在 server.h 中,这里只列出 string 类型的编码
#define OBJ_ENCODING_RAW 0
#define OBJ_ENCODING_INT 1
#define OBJ_ENCODING_EMBSTR 8
编码 1:raw
raw 编码主要用来保存长度超过 44 的字符串。其真实数据,由 sdshdr 结构来表示存储,外层还是由 redisObject 包装。
sdshdr 的结构在前文 Redis 设计与实现 3:字符串 SDS 中有讲到。
sdshdr 结构大致如下:
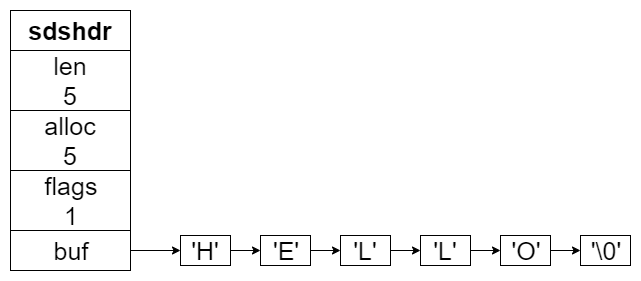
redisObject 中的 ptr 指针,就是指向 sds。

编码 2:embstr
embstr 编码是专门用于保存短字符串的一种优化编码方式。当字符串的长度小于等于 44 的时候,将采用 embstr 编码。
创建字符串对象的代码如下(object.c):
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
embstr 有个显著的特点,就是 redisObject 跟 sds 的内存是挨在一起的。挨在一起的好处:
- 分配内存的时候,只需要分配一次。而
raw编码的sds跟redisObject分离,就要分配两次内存。 - 同样,释放内存也只需要释放一次。
- 连续内存能更好利用内存带来的优势。
其结构示意图如下:
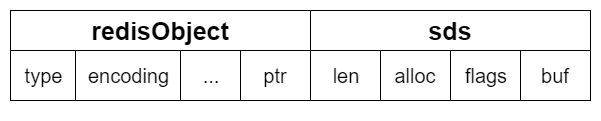
embstr 问题一:那么为什么 embstr 跟 raw 的界限是 44 呢?
embstr的sds使用了sdshdr8,sdshdr8头占用了 3 个字节:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 1 字节 */
uint8_t alloc; /* 1 字节 */
unsigned char flags; /* 1 字节 */
char buf[];
};
- 另外还有
redisObject占用 16 个字节 (4 + 4 + 24 + 32 + 64 = 128位):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; // #define LRU_BITS 24
int refcount; // 32 位
void *ptr; // 64 位
} robj;
redisObject + sdshdr8 至少需要 3 + 16 = 19 字节。
redis 认为如果超过 64 字节就是大字符串,所以在 redisObject+ sdshdr8 的总长度是 64 字节的情况下,留给 buf 的长度就只剩下 45 字节,由于字符串结尾需要一个 \0 占用一个字节,所以留个字符串的长度就只有 44 字节了。
公式:64 - 3(sdshdr8) - 16(redisObject) - 1(\0) = 44
embstr 问题二:为什么网上有的博文说 embstr 跟 raw 的界限是 39
在 redis 3.2 版本之前,这个界限的确是 39,为什么后面改成 44 了呢?
那是因为 sdshdr 的结构在 3.2 版本的时候修改了。3.2 之前的 sdshdr 结构是:
struct sdshdr {
unsigned int len; // 4 字节
unsigned int free; // 4 字节
char buf[];
};
旧版本的 sdshdr 的头占用了 8 个字节,比新版本的多了 5 个字节,所以界限就是 44 - 5 = 39 啦!
编码 3:int
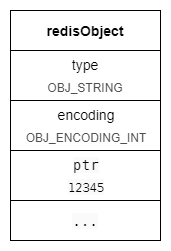
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示,那么这个整数值将会保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long),并将字符串对象的编码设置为 int。
相对于用 raw 编码,int 编码既节省了指针占用的内存,也节省了sds结构的内存。
redis> SET int_key 12345
OK
redis> OBJECT ENCODING int_key
"int"
下图为存着 12345 的 string 示例结构:
二、编码的转换
1. int 转 raw
- 当字符串传的不是整数的时候,int 就会转成 raw 编码。
- 如果执行了一些修改的命令,如
append等(set不算),都会转成raw编码。因为这些操作只有字符串才支持。 - 一旦编码变为
raw之后,将不会再转成embstr
127.0.0.1:6379> SET num 1
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
127.0.0.1:6379> APPEND num 2
(integer) 2
127.0.0.1:6379> OBJECT ENCODING num
"raw"
127.0.0.1:6379> SET num 12
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
2. embstr 转 raw
- 如果执行了一些修改的命令,如
append等,都会转成raw编码,不管修改后字符串的长度。因为没有给embstr编码实现修改接口,所以实际上embsr是只读的。 - 一旦编码变为
raw之后,将不会再转成embstr
三、重点回顾
- 字符串对象有三种编码,
raw、embstr、int raw负责保存长字符串;embstr负责保存短字符串;int负责保存整数。int和embstr在修改的时候,会转成raw编码,并且不再转回
本文的分析没有特殊说明都是基于 Redis 6.0 版本源码
redis 6.0 源码:https://github.com/redis/redis/tree/6.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号