
【动态网页】python3爬取花瓣网图片
步骤:1 分析源码,找到网页地址以及下拉刷新后的地址,提取每张图片的信息,包括pin_id,key,type,通过key可以唯一确定一张图片的地址。
2 编写脚本,使用request库模拟请求
脚本地址:github
举个例子分析:
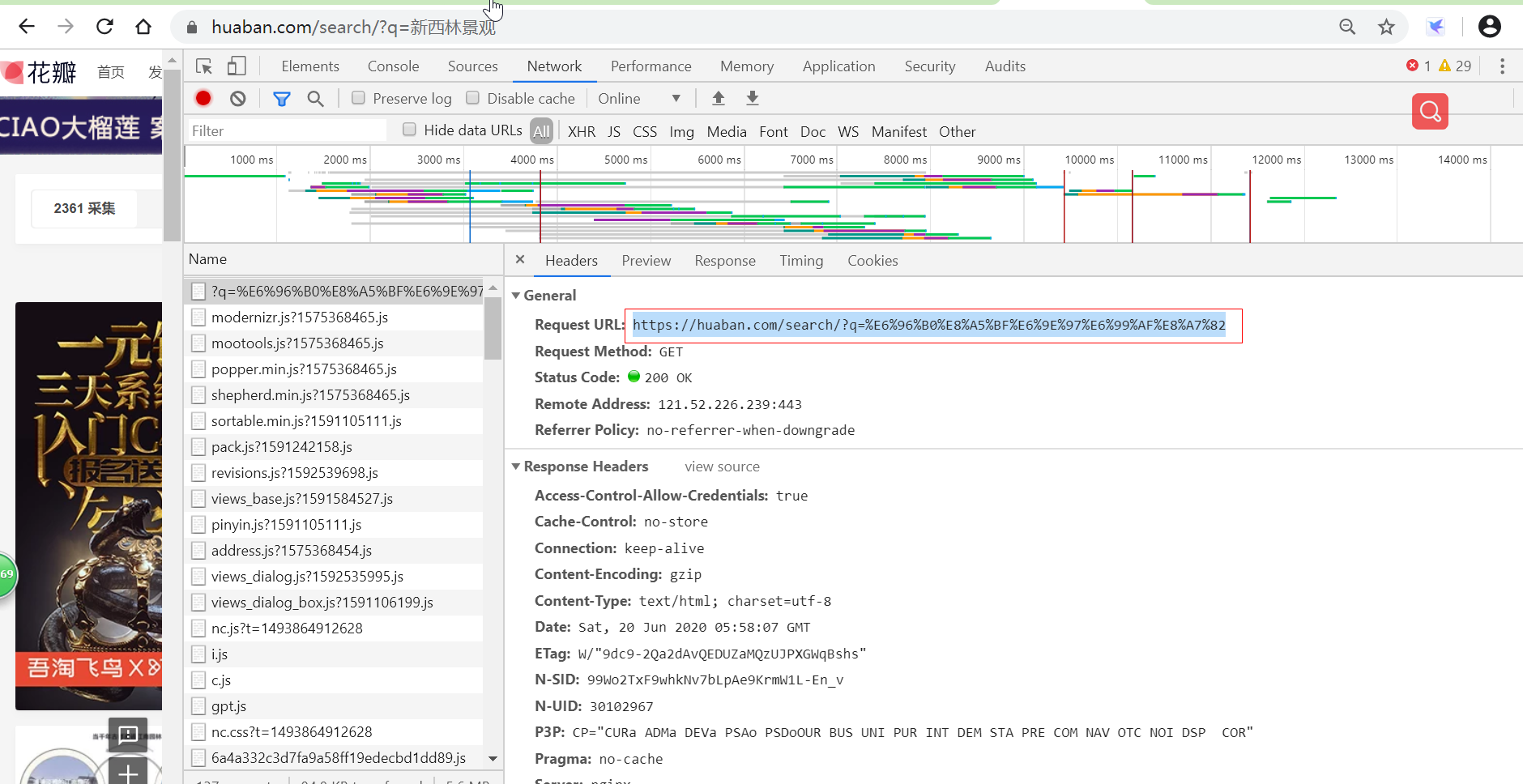
在花瓣网站按关键字搜索“新西林景观”,query=新西林景观
通过开发者工具可看到请求网页为 https://huaban.com/search/?q=%E6%96%B0%E8%A5%BF%E6%9E%97%E6%99%AF%E8%A7%82
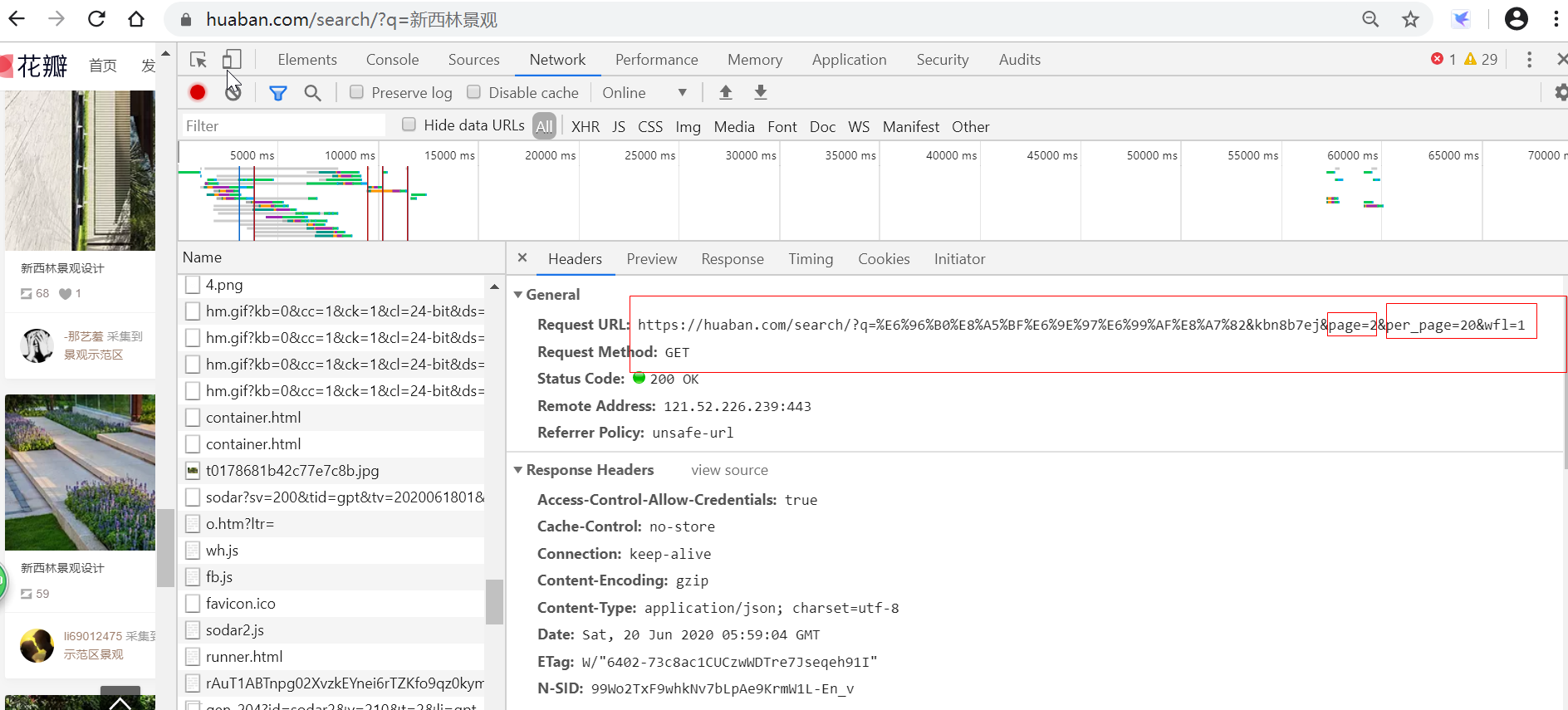
下拉刷新后的地址为:
https://huaban.com/search/?q=%E6%96%B0%E8%A5%BF%E6%9E%97%E6%99%AF%E8%A7%82&page=3&per_page=20&wfl=1
(PS:kbn8b7ek这个不影响访问)
再看response中返回的信息,app.page['pins']中就有20张图片的信息。默认分页显示20张图片。
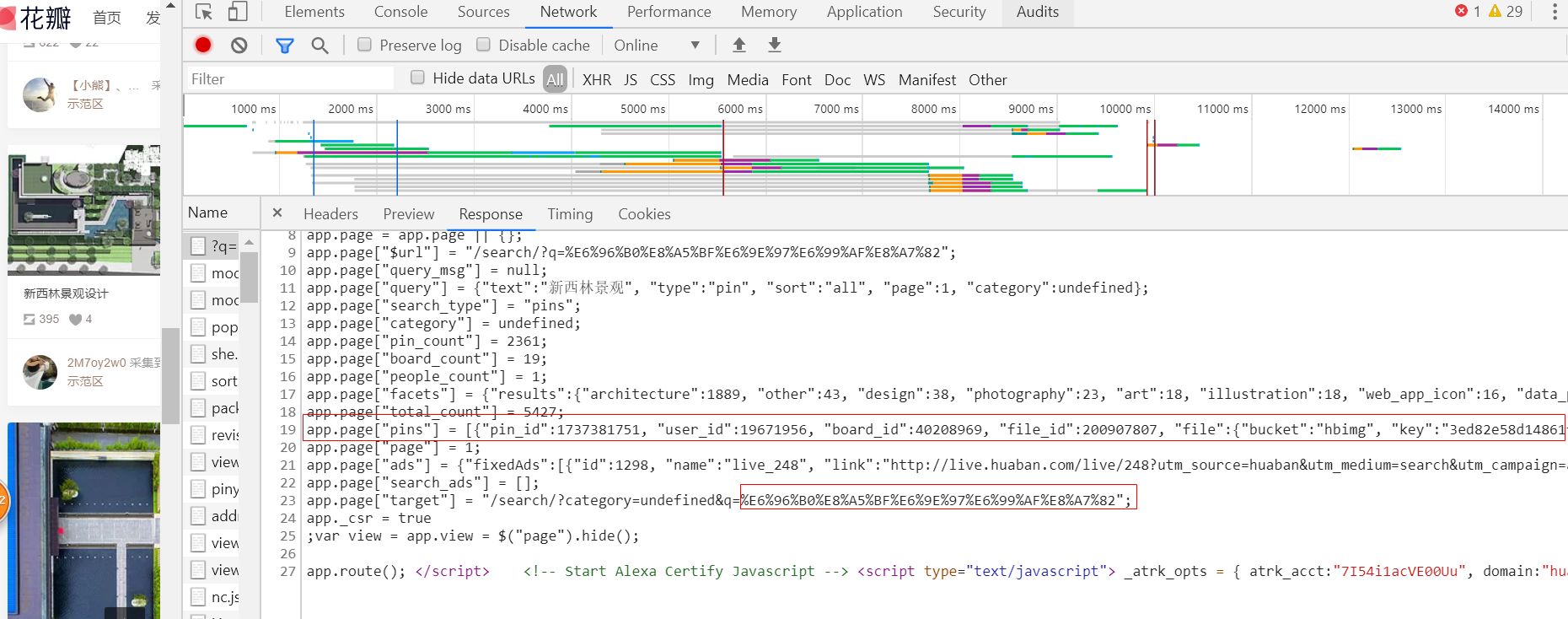
每个图片有一个pin_id和一个key
通过key可以得到该图片地址:
https://hbimg.huabanimg.com/b3c46a29a1c673b08ce738e52c73b69eb366706d1807c-OHZufY_fw658/format/webp
也就是动态传入key,再发起请求访问 f'https://hbimg.huabanimg.com/{key}_fw658/format/webp',再下载图片就ok了

总结思路:找到图片地址-->找到图片信息-->找到下拉刷新后的网页地址
代码实现:循环访问分页,获取图片pin_id和key; 遍历key,再发请求访问图片地址,保存图片。
大功告成!
作者:chenboshi
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号