【MCUNetV2】2021-NIPS-MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning-论文阅读
MCUNetV2
2021-NIPS-MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning
来源:ChenBong博客园
- Institute:MIT
- Author:Ji Lin, Han Cai, Song Han
- GitHub:https://github.com/mit-han-lab/tinyml
- Citation:5
Introduction
在MCU平台上, 针对CNN imbalanced memory distribution的问题(peak memory占用过高, 导致TinyML的部署瓶颈), 提出了一种patch-by-patch inference的推理模式, 降低CNN的peak memory占用, 进而在新模式下的搜索空间下用NAS进行网络结构搜索(非本文重点).
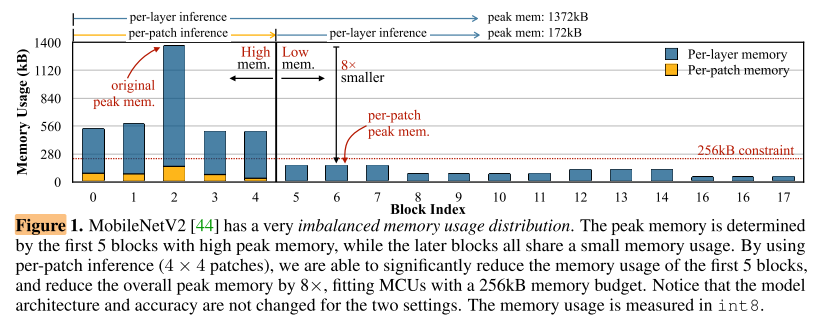
现有的解决TinyML上peak memory的2种方式:
- 使用更小的网络, 前期满足memory要求, 后期memory浪费
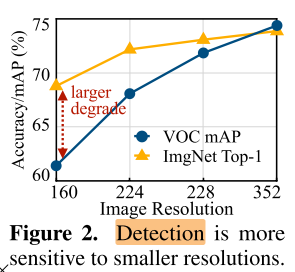
- 减小输入分辨率, 有些任务是分辨率敏感的(目标检测)
Contribution
- 系统研究了CNN imbalanced memory distribution的问题
- 提出patch-based inference, 以及receptive field redistribution对CNN结构进行优化降低peak memory的同时, 保持性能sota
Method
imbalanced memory distribution
Memory Bottleneck
MobileNetV2 [44] with input channels 3, output channels 32, and stride 2, running it on an image of resolution 224 × 224 requires a memory of 3 × 224\(^2\)+ 32 × 1122 = 539kB even when quantized in int8.
Patch-based Inference
传统的CNN推理是 layer-by-layer inference, 这个过程中会使用img2col将卷积的滑动窗口操作转换为矩阵乘法(图3左)
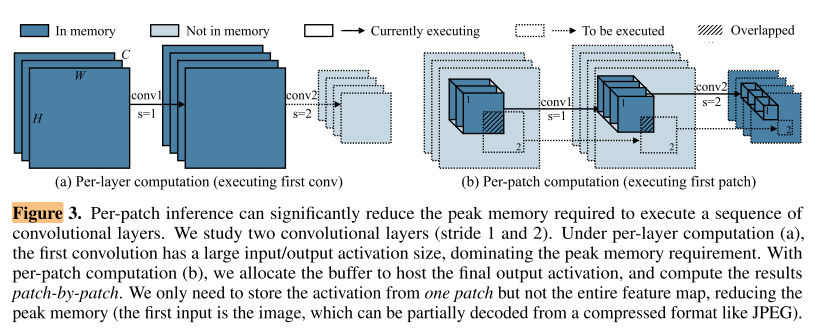
- 将网络划分为2部分, 分别执行不同的推理模式: patch-based inference stage 和 layer-by-layer inference stage
- 在patch-based inference stage中, 对stage末尾的activation划分为pxp个patch, 串行地计算每个patch(图3右), p=1时即退化为layer-by-layer inference
- 优点: p越大, cnn的peak memory越低
- 缺点: 当p>1时, 由于卷积kernel size>1, 因此在计算最后一层不重叠的patch时, 在前面几层的感受野有overlap, 从而与基于 img2col 的 layer-by-layer inference相比, 会带来额外的计算开销, 且p越大, 或 patch-based inference stage 的层数n越多, 前面几层的patch感受野就越大, 感受野越大产生的额外开销就越多
- 解决办法:
- 在patch-based inference阶段缩小感受野(减少patch p 和层数n)
- 但前期感受野的缩小会导致性能的下降, 在后期加大感受野(增加层数)
- 新的推理模式带来新的网络搜索空间, 使用NAS(超网训练+进化算法搜索)自动确定resolution(96-256, step=32), p(1/2/3/4), n(<total number of layer N), layer的kernel size(3/5/7), expansion ratio(3/4/6), block num(2/3/4), block width multiplier (0.5/0.75/1.0)
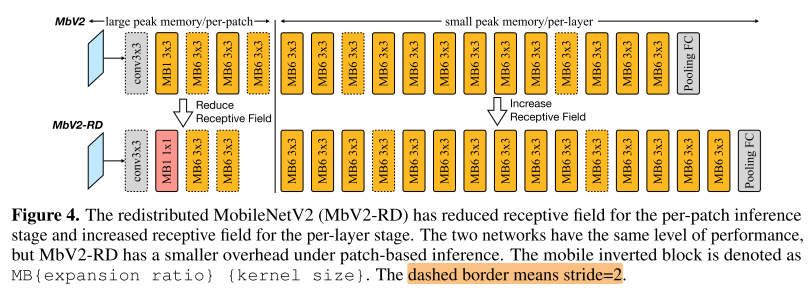
只使用p(MbV2) vs p+n(MbV2-RD)带来额外计算开销的对比:

方法总结
Experiments
Classification
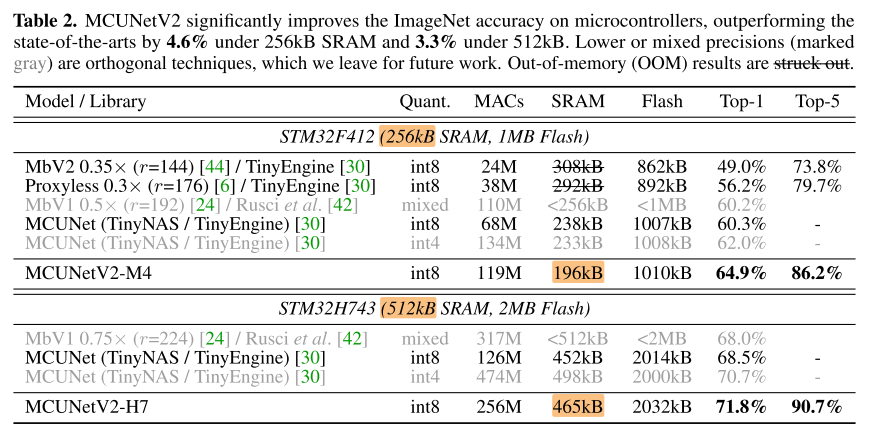
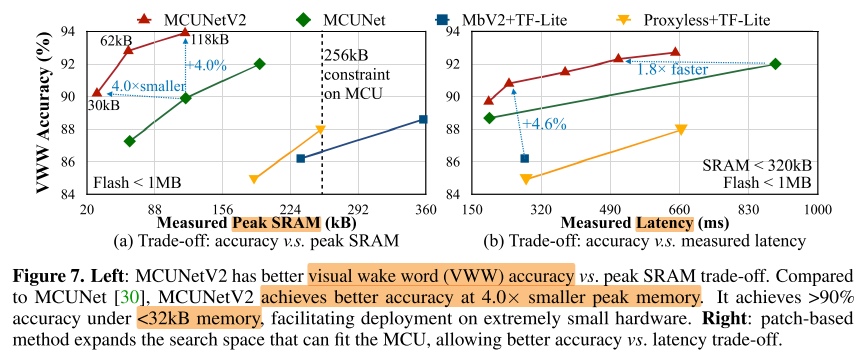
Detection
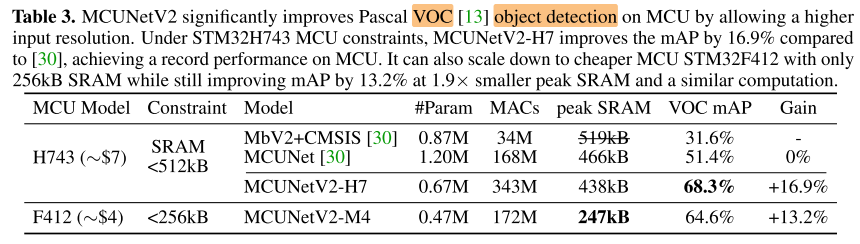
Summary
- CNN peak memory的问题广为人知
- 本文解决peak memory的方式也比较朴素, 也不难想到: 在网络前期进行切patch的串行推理, 用时间换空间
- 最主要的应该是强大的硬件实现能力, 最终效果也很惊艳
- 网络结构设计(剪枝, 量化, NAS...)趋势: 与硬件的结合越来越紧密(e.g. AdderNet, RepVGG, RepLKNet...), 越接近硬件也就越有落地价值(核心竞争力?)
Reference
凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多?| 文末附 meetup 直播预告 - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号