【CDRP】2018-CVPR spotlight-Interpret Neural Networks by Identifying Critical Data Routing Paths-论文阅读
CDRP
2018-CVPR spotlight-Interpret Neural Networks by Identifying Critical Data Routing Paths
来源: ChenBong博客园
2020-TIP-Interpret Neural Networks by Extracting Critical Subnetworks
- Institute:Tsinghua University
- Author:Yulong Wang, Hang Su, Bo Zhang, Xiaolin Hu
- GitHub:
- Citation:30+
Introduction
借鉴了通道剪枝的思想, 通过在pre-trained model上, 为每个样本寻找各自的"关键子网"的方式来解释神经网络的工作方式的文章
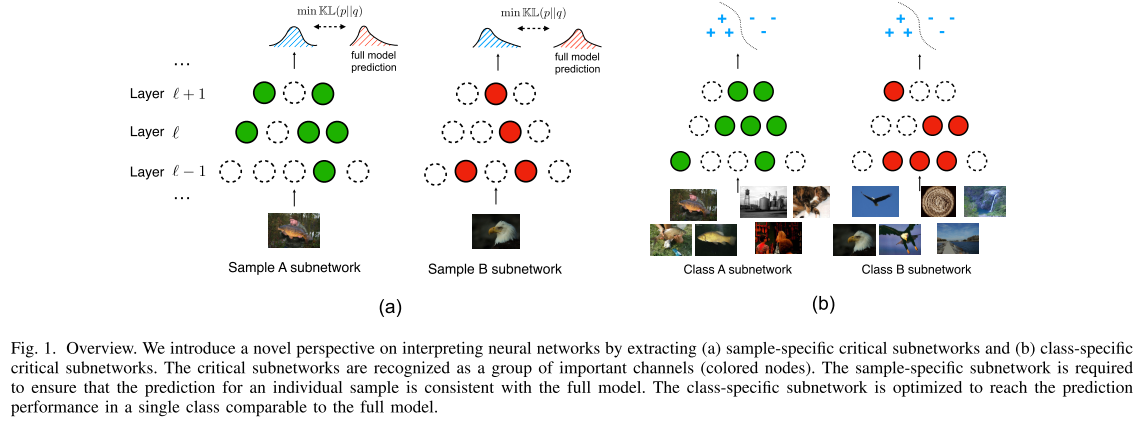
Motivation
不同的样本激活的卷积核是不同的, 作者为不同样本都单独学习一组channel-wise的control gate vector, 来确定该样本激活的"关键节点"(channel), 从而确定该样本的"关键子网"
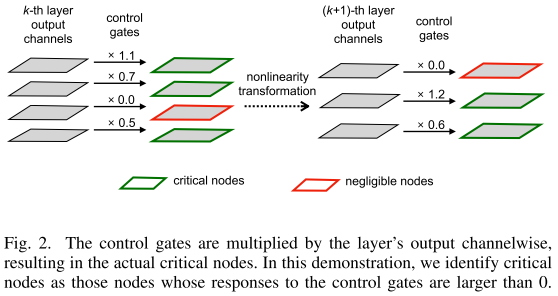
Method
Sample-Specific Subnetwork
第 \(i\) 层的 control gate value: \(\boldsymbol λ_i \in \mathbf R^{1 × c_i}\), \(c_i\) 是第 \(i\) 层的通道数
整个网络的 control gate value: \(\Lambda=\left\{\boldsymbol{\lambda}_{1}, \cdots, \boldsymbol{\lambda}_{n}\right\}\)
给定一个pre-trained model, 和某个样本x, 如何优化的 \(\Lambda\) ?
使用SGD梯度更新 \(\Lambda\) , 最小化公式(2)的loss:
\(\begin{aligned} \min _{\Lambda} & \mathcal{L}_{\mathrm{CE}}\left(f_{\theta}(x), f_{\theta}(x ; \Lambda)\right)+\gamma \sum_{j}^{n} \boldsymbol{\lambda}_{j} \\ \text { s.t. } & \boldsymbol{\lambda}_{j} \succeq 0, \forall j=1,2, \cdots, n, \end{aligned} \qquad (2)\)
\(\frac{\partial \mathcal{L}}{\partial \Lambda}=\frac{\partial \mathcal{L}_{\mathrm{CE} / \mathrm{BCE}}}{\partial \Lambda}+\gamma * \operatorname{sign}(\Lambda) \qquad(7)\)
- 算法输入为单张图片, 输出为为该图片优化的 \(\Lambda\)

Algo L7-9保证了每个样本找到的 稀疏Sample-Specific Subnetwork 的预测结果都与full model完全一致, 即在Acc不降的前提下, 找到最小的子网 (最稀疏的 \(\Lambda^*\) )
Class-Specific Subnetwork
Class-Specific Subnetwork只需要判断该样本是否属于该类(是/否), 即二分类, 因此改为BCE Loss:
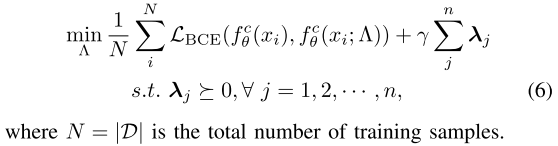
\(\frac{\partial \mathcal{L}}{\partial \Lambda}=\frac{\partial \mathcal{L}_{\mathrm{CE} / \mathrm{BCE}}}{\partial \Lambda}+\gamma * \operatorname{sign}(\Lambda) \qquad(7)\)
- Sample-Specific Subnetwork是每个样本应用各自的一个 \(\Lambda^*\) , Class-Specific Subnetwork相当于一类样本应用同一个 \(\Lambda^*\) , 因此无法做到Acc不降, 因此算法2的输入多了预设的稀疏率 \(\tau\)

Experiments
Sample-Specific Subnetwork
在ImageNet上与类似剪枝的方法对比
- Adaptive Weight Pruning (AWP), 根据weight norm来确定 Sample-Specific Subnetwork (\(\Lambda^*\)), 输入无关? 性能最差
- Adaptive Activation Pruning (AAP), 根据activation norm 来确定 Sample-Specific Subnetwork (\(\Lambda^*\)), 输入有关
AWP和AAP相当与 \(\Lambda\) 中的值的取值范围是{0, 1}, 而本文的方法 \(\Lambda\) 中的值的取值范围是 [0, \(+\infty\)], 不是很公平
因为control gate value是>=0的值, 因此稀疏率的计算应该是 \(\Lambda\) 中值为0对应的channel认为是被剪去, 其余的都视为保留, 然后计算每个样本对应的Sample-Specific Subnetwork的平均稀疏度
而且这里应该是为每个验证集的样本单独学习各自的 \(\Lambda\)
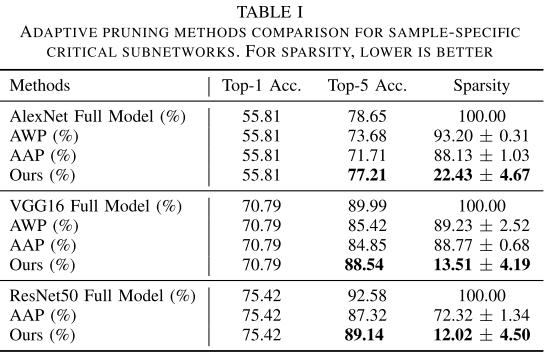
可以看出, 本文的方法可以在很低的FLOPs下(10-20%), 保持与 Fullmodel 相同的性能, 性能高的原因: 在验证集上单独优化每个样本的Specific Subnetwork (\(\Lambda^*\))
如果可以设计1个module, 可以自适应的根据输入样本生成每一层的 \(\lambda_i\), 就是动态网络的工作, 此时表1中的结果可以看成是这种动态网络方法性能的上界.
Class-Specific Subnetwork
- AUROC是二分类的指标, 越高越好
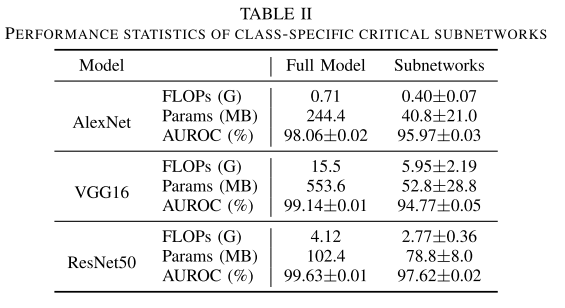
每一类共用一个Class-Specific Subnetwork的方式, FLOPs的压缩率就不是很高了
进一步的如果所有类共用1个Specific Subnetwork, 其实就和静态剪枝一样了
可解释性
Sample-Specific Subnetwork
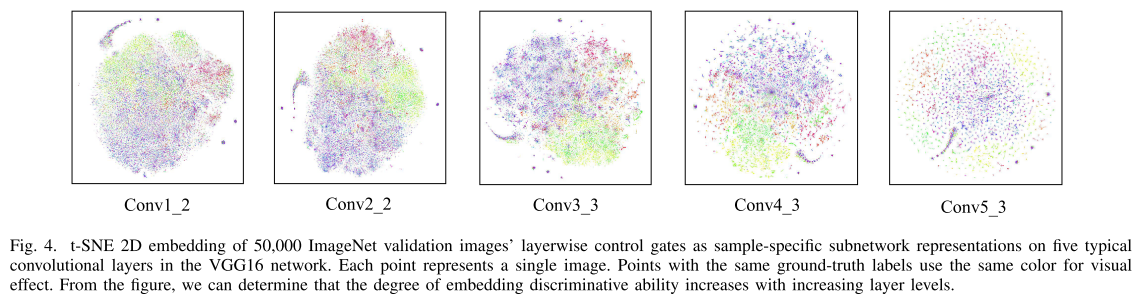
对不同样本不同层的gate vector做降维可视化, 越深的层区分度越高.
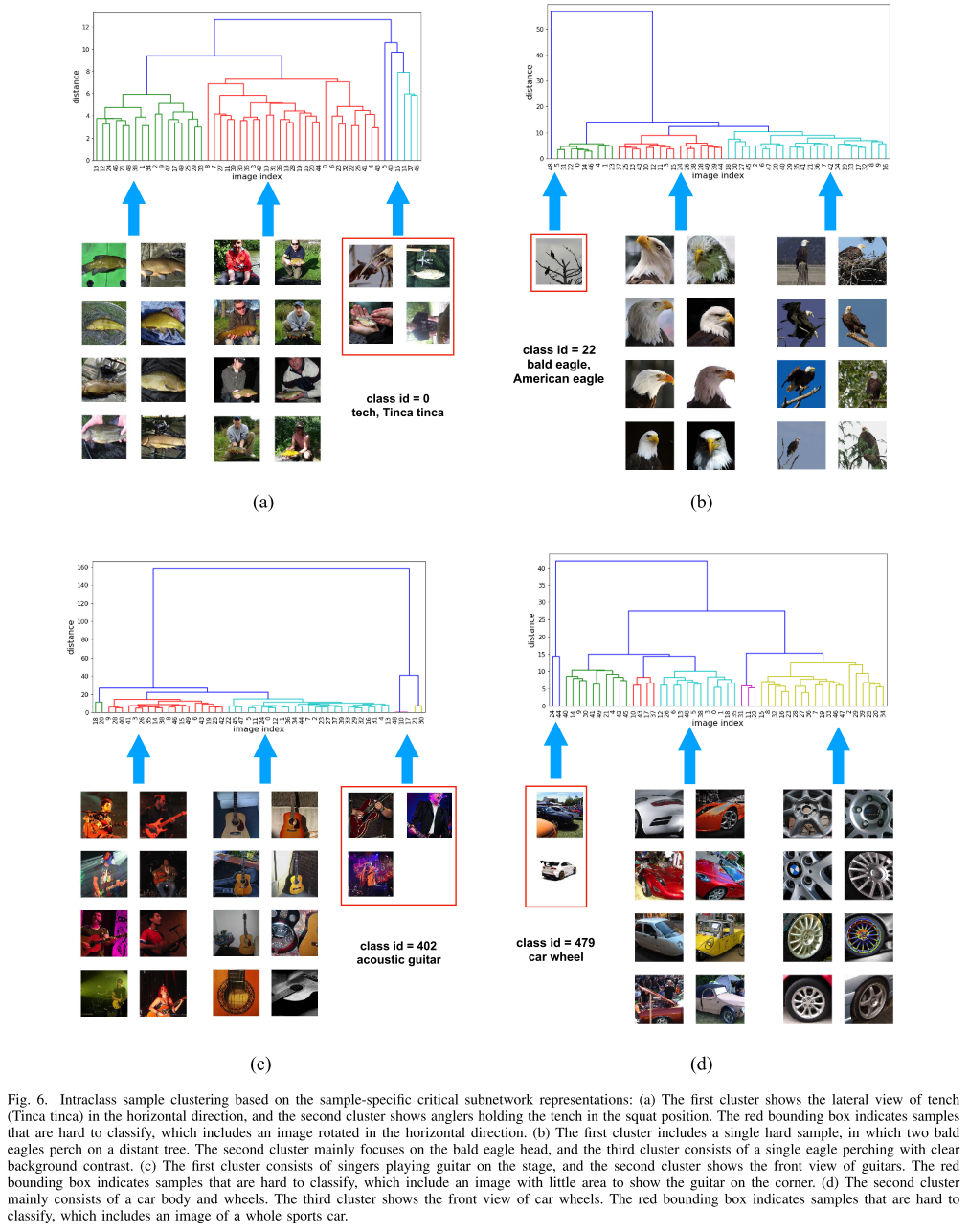
使用Sample-Specific Subnetwork gate vector计算类内距离, 可以发现一些离群的样本:
使用Sample-Specific Subnetwork gate vector 检测攻击样本:
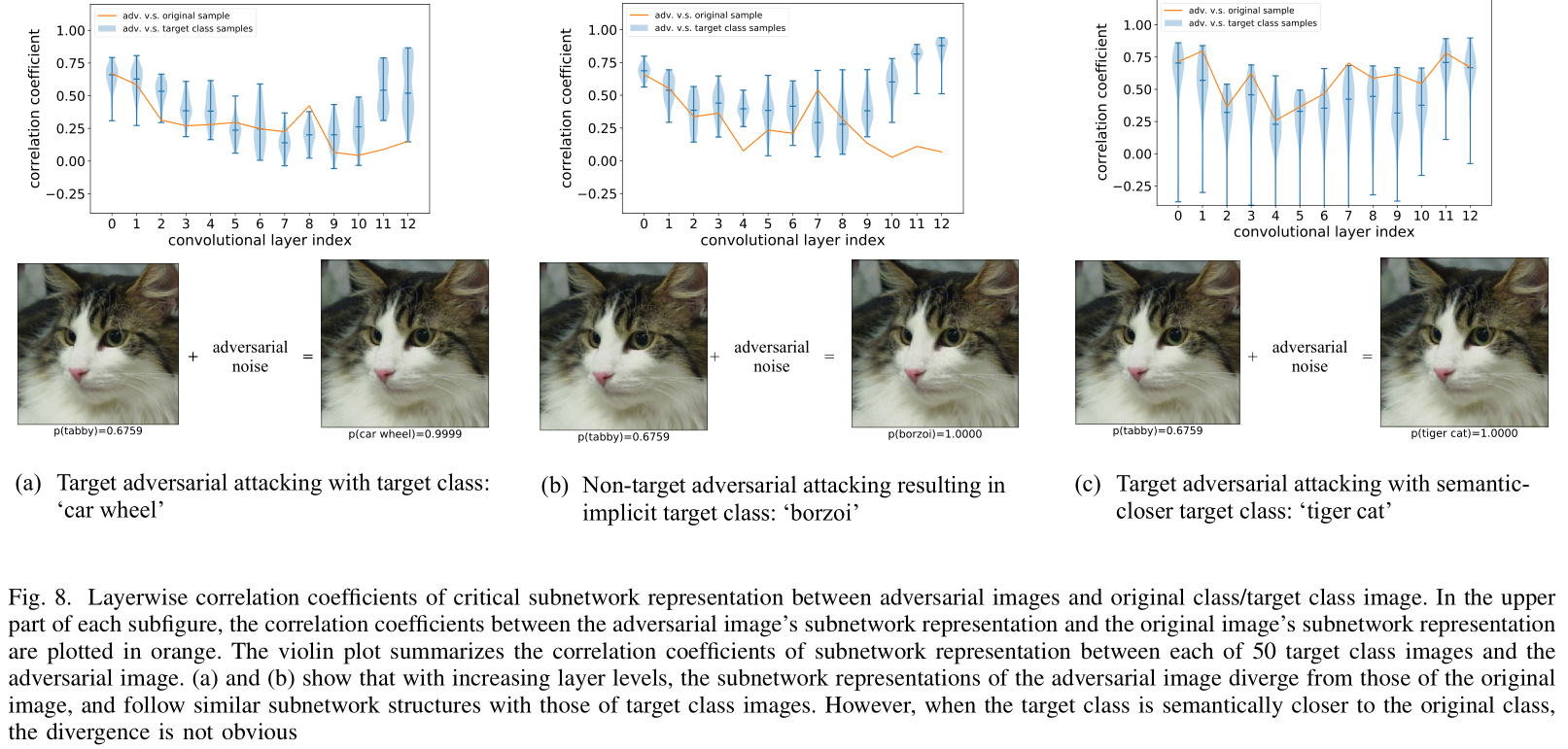
蓝色: 攻击图片(右) 与 50张目标类(car wheel)图片的 Sample-Specific Subnetwork gate vector在不同层的相关系数, 都在一个比较高的值
橙色: 攻击图片(右) 与 原始图片(右) 的 Sample-Specific Subnetwork gate vector在不同层的相关系数, 在越深的层相关系数越小(在深层语义上逐渐背离原始图片)
- 如果攻击图片的语义与原始图片接近, 则差距不大
Class-Specific Subnetwork
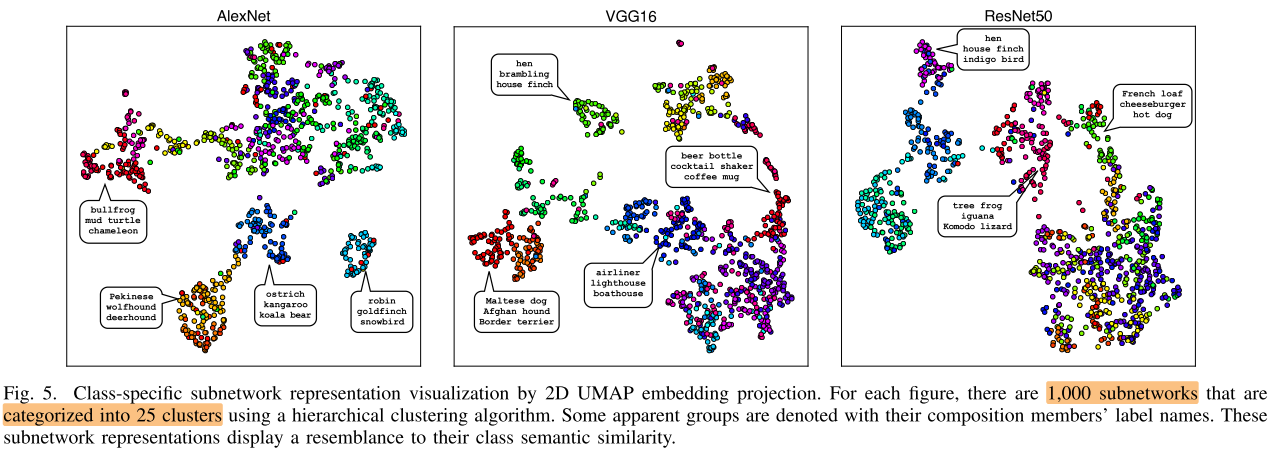
对1000个类的Specific Subnetwork(vector)聚类为25类可视化:
Summary
样本自适应的动态网络工作与模型剪枝, (空间/通道)注意力, 神经网络可解释性的工作有很多交叉的地方, 可以从这些工作中得到一些启发
Reference
https://zhuanlan.zhihu.com/p/68299186
http://www.hahnyuan.com/algorithm/interpret-nn-CDRP.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号