【ClassSR】2021-CVPR-ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic-论文阅读
ClassSR
2021-CVPR-ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
来源:ChenBong 博客园
- Institute:Shenzhen Institutes of Advanced Technology (中科院-深圳先进院)
- Author:Xiangtao Kong, Hengyuan Zhao, Yu Qiao (H65), ...
- GitHub:https://github.com/Xiangtaokong/ClassSR 180+
- Citation:1
Introduction
基于sample-aware思想的高分辨率(2K-8K)的图像超分
p.s. 2K: 2048x1080; 4K: 4096x2160; 8K: 7680x4320
高分辨率图片的底层视觉任务由于输入分辨率较大, 通常都是将输入图片切成小的patch再送入网络. 作者发现超分任务中, 不同区域的patch超分的难度是不同的, 例如纹理多的区域的难度就大于平滑区域.
于是作者想到可以用不同大小的网络来处理不同区域的patch: 先用一个小的CNN (会带来额外的计算开销) 评估patch的难度, 再根据难度选择不同大小的网络来处理patch. 用小网络处理简单(平滑, 单一背景)的patch, 用大网络处理复杂(纹理细节多)的patch, 从而节约计算量.

如图1, 分类网络将patch分为simple, medium, hard三类, 对应三个大小的网络 (会带来存储开销的增加, 本文不同大小的网络是通过设置不同的网络宽度来得到) 进行处理.

引入额外的分类网络会带来少量的计算开销, 但由于大部分patch都使用最小的网络进行超分, 因此还是可以带来总体计算量的下降.
本文的方法与与轻量超分网络是正交的, 即插即用的, 可以用在任意规模的超分backbone网络上, 或与压缩的方法结合.
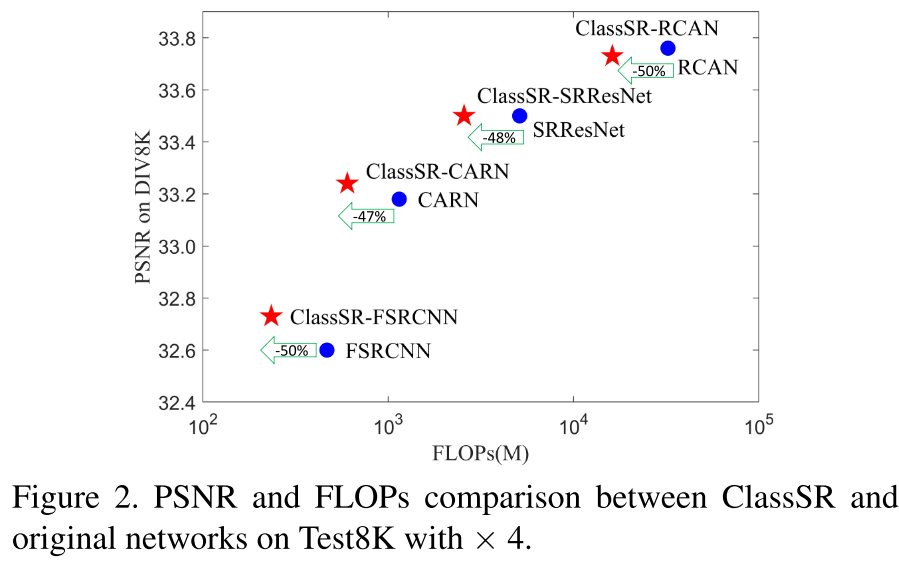
效果: 除了带来<3倍的存储开销的缺点之外, 基本上在不同的backbone上都可以做到剪一半的FLOPs性能不掉. 图2, FLOPs范围 468M~32.60G
p.s. 分类CNN计算开销 FLOPs=8M:
- input是32x32的patch, 而不是完整的图片, 层数少, 实际的FLOPs也不大;
- 超分backbone的网络的FLOPs都很大, 增加的相对开销也就不大
Contribution
- 第一个将分类网络与超分网络结合的工作, 具有sample-aware动态网络的思想, 即不同的样本(patch)使用不同规模的网络
- 一般sample-aware动态网络方法中不同规模的网络是超网中的不同子网, 本文是独立的网络 (改进点, 将本文不同规模的静态网络融合在一个动态超网中, 可以节约存储开销)
- 一般sample-aware动态网络中是用layer-gate来进行条件计算, 本文是前置一个CNN进行子网选择 (InstaNAS也是前置1个CNN进行子网结构预测, 21M+1.8G)
- 根据提出的方法, 设计了新的分类CNN与超分backbone联合训练的方法 (训练分类CNN的3个loss)
- 可以实现实际的加速
Method
Observation (验证性实验)
作者对DIV2K数据集图片的patch(32x32), 用pretrain MSRResNet进行超分, 根据psnr将patch分成simple, medium, hard数量相等的三类:
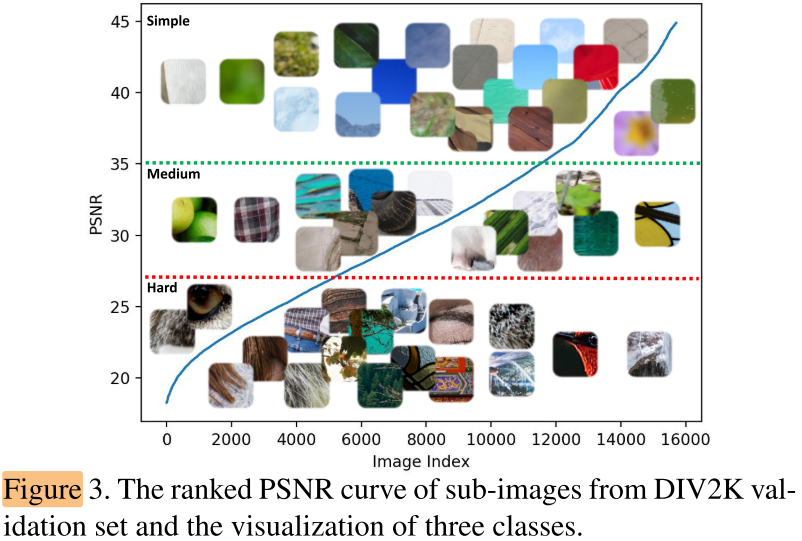
(psnr越大可以认为该patch的超分难度越小; 反之psnr越小, 超分难度越大)
可以观察到simple到hard有不同的特点, simple(smooth), hard(complex textures)
用三类不同难度样本分别训练三个规模(first and final通道数16, 36, 56)的FSRCNN, 以及用所有patch样本训练FSRCNN-O (56), 结果如下:
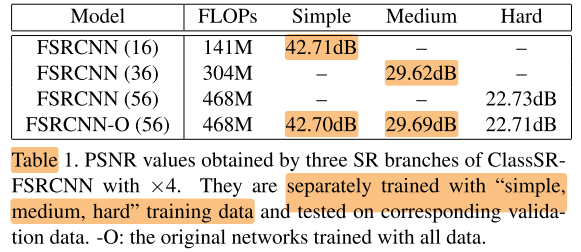
表1的结果说明了针对简单样本使用小网络并不会带来性能上的损失
Overview
Class-Module
5 conv + avgpool + FC
SR-Module
不同尺寸超分网络的设计方式: 不同宽度 (16, 36, 56), 56是原始宽度
p.s. 也可以用其他方式, 如不同深度, 不同大小的backbone
Training Strategy
- train SR-Module: 使用well-trained MSRResNet对训练集的patch进行超分, 根据超分结果的psnr分将patch为3类, 使用3类图片分别训练3个不同大小的SR model
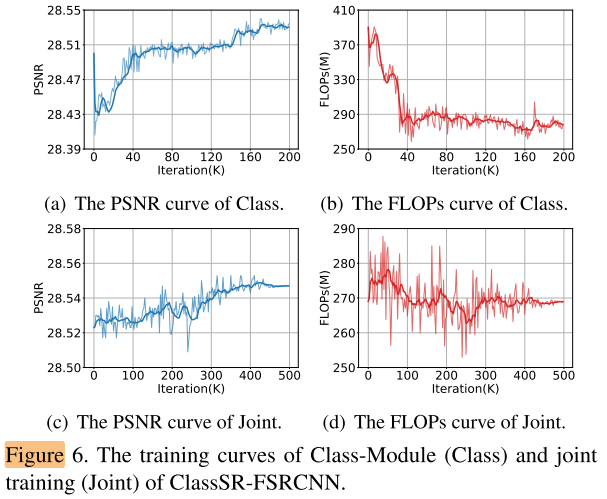
- train Class-Moudle: 固定SR-Module, 使用3个loss训练分类CNN, 图6 a b, 只训练分类CNN可以降低FLOPs(simple patch原来分配给大网络的改为分配小网络), 提高PSNR(simple patch用小网络超分的效果比大网络要好)
- joint train (fine-tune): 联合训练Class Module和SR-Module, 图6 c d
训练 Class-Module 的3个loss
\(L=w_{1} \times L_{1}+w_{2} \times L_{c}+w_{3} \times L_{a} \qquad (2)\)
Image Loss (\(L_1\) Loss)
\(L_1=|\hat y - y|\) ,
其中 \(\hat y\) 为HR图片,
y为对M个分支加权求和的SR图片 \(y=\sum_{i=1}^{M} P_{i}(x) \times f_{S R}^{i}(x) \qquad (1)\)
Class Loss (\(L_c\) Loss)
作者希望分类CNN能够突出某个分类的结果(e.g. [0.90, 0.05, 0.05]), 而只有 \(L_1\) loss的话, 会出现三个分支等概率的情况 (e.g. [0.34,0.33,0.33]), 类似随机分配, 因此加入Class Loss:
\(L_{c}=-\sum_{i=1}^{M-1} \sum_{j=i+1}^{M}\left|P_{i}(x)-P_{j}(x)\right|\), s.t. \(\sum_{i=1}^{M} P_{i}(x)=1 \qquad (3)\)
输出概率之间两两作差, 再求和. 即希望不同概率值之间差距越大越好
Average Loss (\(L_a\) Loss)
有了以上2个loss, 分类器可以突出某个分类结果, 但因为最大的SR分支效果好, 会都分配到最大的分支, 因此加上将样本平均分配到不同分支的约束:
\(L_{a}=\sum_{i=1}^{M}\left|\sum_{j=1}^{B} P_{i}\left(x_{j}\right)-\frac{B}{M}\right| \qquad (4)\)
Experiments
Setting
Dataset
- training data:
- DIV2K;
- scale 0.6, 0.7, 0.8, 0.9 => HR; HR crop 128x128 => HR patch
- downsample 4x => LR; LR crop 32x32 => LR patch
- testing data:
- DIV8K, 300张; downsample to 2K, 4K, 8K, 各100张 => HR
- HR downsample 4x => LR; LR crop 32x32 with stride 28 => LR patch
- SR patch = ClassSR(LR patch), SR patch 拼接成SR时, 重叠部分取平均(获得平滑的过渡)
...
Main Results
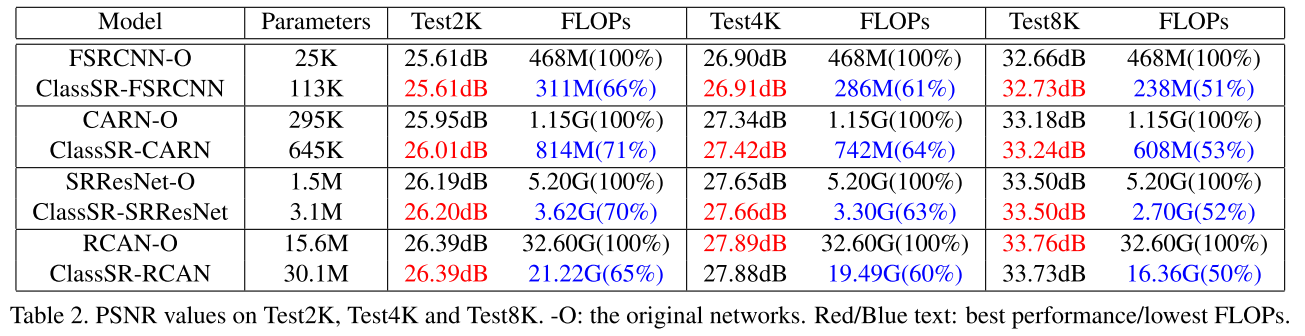
在分辨率越大(8K)的超分任务上, FLOPs减少的越多
Ablation Study
Effect of Class-Loss
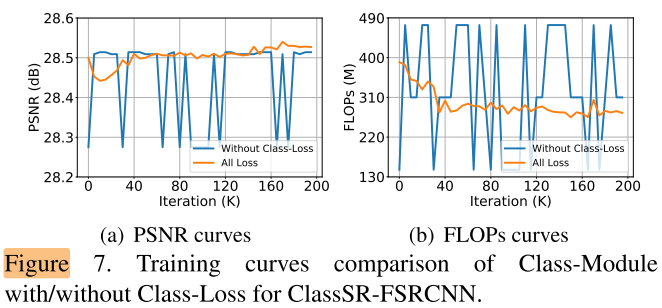
去掉class loss之后, 不再突出某个分类的结果, 接近随机分配, 训练不稳定
Effect of Average-Loss
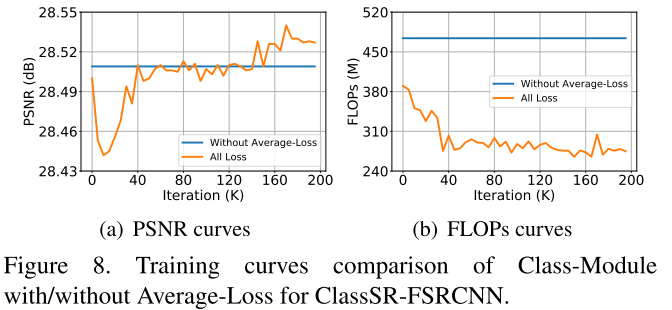
去掉average loss之后, 不再为M个分支平均分配样本, 都分配到最大的分支
Effect of the number of classes

分支的数量2 3 4 5, 加速效果相当
Controling network complexity

同时调整层数和宽度来设计不同的分支
Other low-level tasks

通用性: 可以应用到其他底层视觉任务上
Conclusion
Summary
pros:
- 条件计算, 样本自适应, 分而治之
- 与其他加速方法(轻量网络, 压缩等)正交, 即插即用
- 主实验/消融实验丰富, 开源
cons:
- 加速比是固定的, 难以手动控制, 虽然在训练阶段分类CNN的AvgLoss将batch平均分配到三个分支, 理论上训练后的网络的FLOPs应该是三个分支的平均, 但在测试集上的实际比例不是均等的(simple : medium : hard = 61:23:16), 因此实际的加速比是不可控的
- 这也是很多sample-aware动态网络共同的问题, 模型训练完以后, 由于训练集与测试集的差异, 导致实际的加速比不可控, 而且同一个样本, 分配的推理路径是固定的 (TODO: Sample aware + Resource aware, 同一个样本的推理路径是根据样本自身的特点和可用的计算资源共同决定)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号