【NN Foreget】2021-arxiv-What Do Compressed Deep Neural Networks Forget?-论文阅读
What Do Compressed Deep Neural Networks Forget?
2021-arxiv-What Do Compressed Deep Neural Networks Forget?
来源:ChenBong 博客园
- Institute:Google && MILA
- Author:Sara Hooker, Aaron Courville (H80)
- GitHub:https://github.com/google-research/google-research/tree/master/pruning_identified_exemplars
- Citation:16
Introduction
压缩中的(权重)剪枝和量化技术已经被证明可以在很高的压缩率下几乎不损失测试集精度. 但是只考虑top-1/5 acc的评价指标, 忽视了这些压缩技术对不同类别, 不同样本, 已经模型泛化性的影响.
几个发现:
- 压缩技术也许在整个测试集的top-1/5 acc的评价指标下变化不大, 但对不同类别(部分子集)的影响并不是均匀的, 而是不平衡的(即有些类的acc上升, 有些类的acc下降).
- 压缩技术对子集中的部分样本的影响更大(未剪枝模型和剪枝模型对同一个样本给出了不同的预测label), 作者将这些样本称为 "Pruning Identified Exemplars (PIEs)"
- 压缩技术对模型的泛化性有很大的影响.
总的来说, 压缩方法中通常认为模型存在很大的冗余, 而这篇文章说明了模型冗余的部分并不是完全没用的, 冗余部分是用来增强模型对特殊数据点的识别能力, 以及增强模型的泛化能力的.
Motivation
- 婴儿到成人期间神经元的数量先成倍增加而后又减少(2-10岁期间失去50%的神经元), 但大脑能力并没有因此受损, 因此这期间失去的神经元对大脑来说到底失去了什么还是个问题.
- 而这篇文章我们要回答, 当我们在压缩模型的过程中, 模型到底失去了什么
Contribution
- top-1/5这类指标掩盖了模型损失的一些细节
- 首次从类别和样本角度分析压缩技术对模型的影响, 在样本的层面上提出Pruning Identified Exemplars (PIEs), 且发现PIEs通常对人类来说也是困难的样本(标签错误, 标签质量差, 多类别等)
- 压缩后的模型泛化性能受损, 即对对抗图像的敏感性更高, 且敏感性随着压缩率的上升而上升
- 不同的压缩方法都对不同的子集有不均匀的影响, 权重剪枝带来的不均匀影响比量化(PTQ)更大
Method
- 压缩方法
- 权重剪枝: L1, 剪枝率=
- PTQ量化: float16, dynamic range int8, fixed in8
- 数据集与模型
- wide ResNet on CIFAR-10 (94.35%)
- ResNet-50 on ImageNet (76.68%)
- ResNet-18 on CelebA (94.73%)
- 每组实验使用不同的随机种子重复30次, 排除统计上的偏差
Experiments
压缩方法对子集的不均匀影响
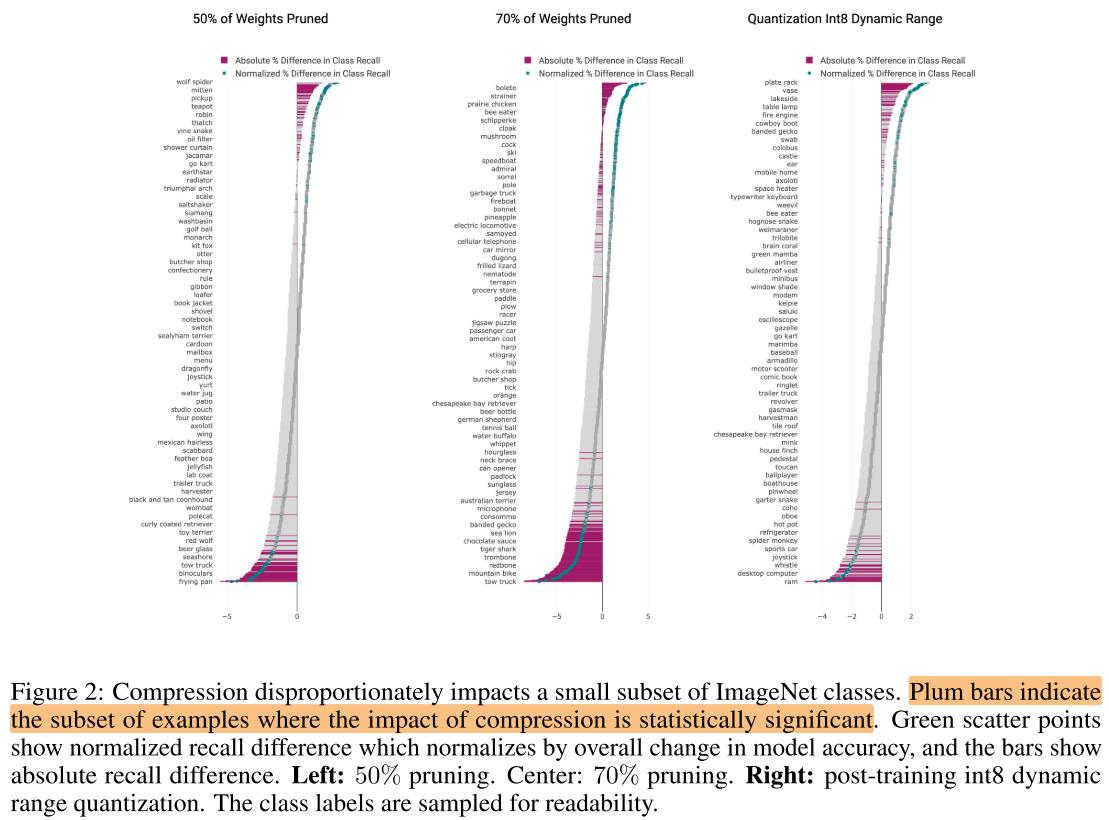
- 纵轴为不同类别, 横轴为压缩后模型与压缩前模型的相对类别准确率的变化
- 红色表示具有显著统计学差异的类别
- 压缩方法都会来带类别不均匀的影响, 在相近的压缩率下(70% pruning, int8 量化), 量化带来的不均匀性更小
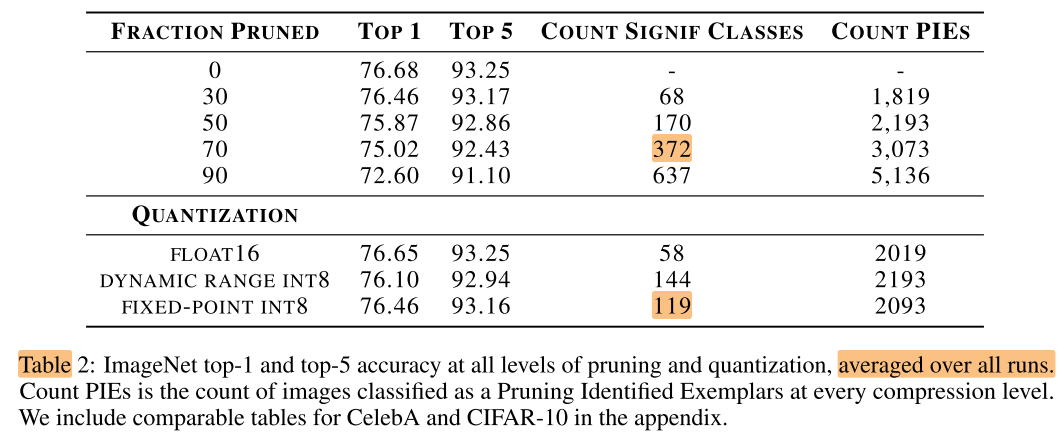
- 在90%稀疏率下, ImageNet测试集中有10.27%的样本为PIEs

- PIE图片可以分为以下一些类别: 标注错误, 多目标, 损坏, 抽象概念("画"与"画中的内容")
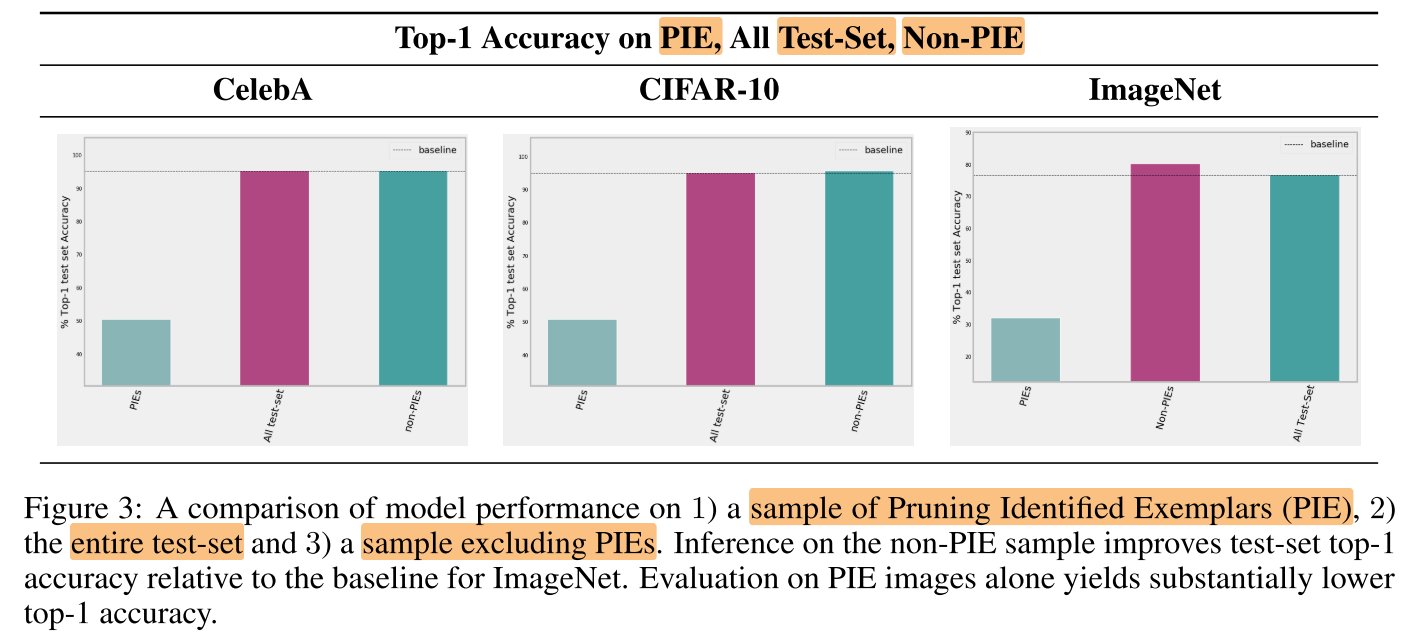
- 使用未压缩的模型分别对PIE, 整个测试集, Non-PIE进行测试, 发现去掉PIEs以后, 测试集上的精度显著提高(ImageNet: 76.75% => 81.20%), 说明PIEs中有很多未压缩模型就识别错误的样本
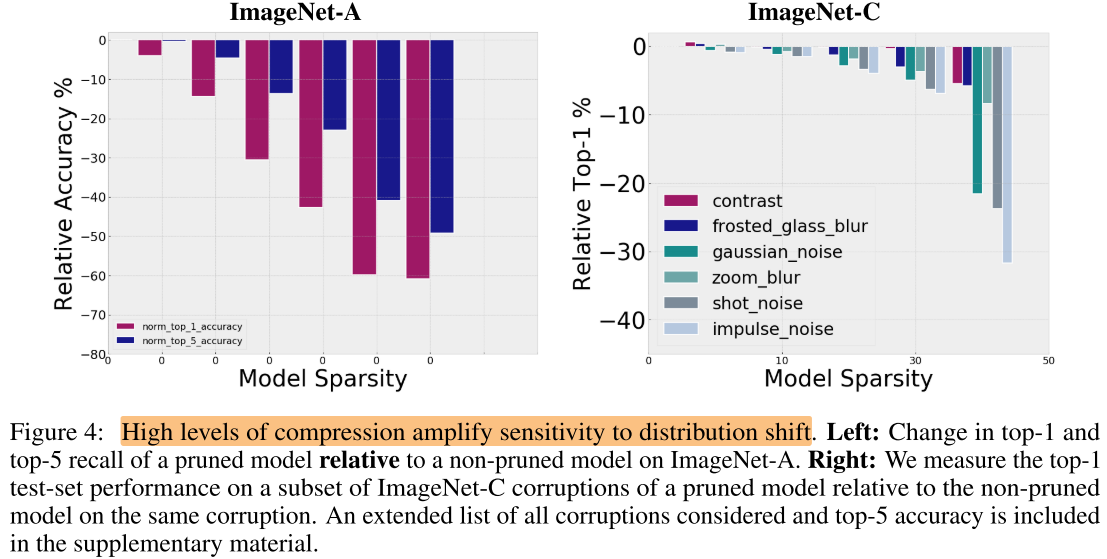
压缩对模型泛化性(数据分布的偏移)的影响
- ImageNet-A: 7500张对抗测试图片
- ImageNet-C: 对ImageNet测试集使用16种腐蚀算法(blur, noise, fog)
Conclusion
- 压缩技术对不同类别(子集)的样本有不均匀的影响, 以及模型泛化性变差, 在敏感任务 (医疗, 自动驾驶等) 中应当慎重使用
- 不均匀: 某个ImageNet模型压缩后性能掉了0.1%, 如果这0.1%全都集中在"人"这一类别上, 对任务会有巨大的影响
- 泛化性变差(不鲁棒): 遇到不同的天气/光线等识别率下降
- 要提高模型的性能, 除了增加模型的容量, 还应该多关注PIE样本(可以利用压缩模型找出PIE样本), 在data pipeline过程中就处理好标签错误之类的问题可能对模型性能的提高更重要.
Summary
模型压缩与模型性能的影响(广义, 不仅指acc)
- 类别/样本acc (本文)
- 模型泛化性 (本文)
- 模型鲁棒性
不同压缩算法对模型(广义)性能的影响 (提出新的评价指标, 鲁棒的模型压缩算法)
- L1权重剪枝与3种PTQ量化 (本文)
- 不同的权重剪枝, filter剪枝算法, PTQ, QAT量化算法对模型广义性能的影响
- 例如:
- A, B 2种剪枝算法, 在相同的压缩率下, 相同的全局acc下, 其他方面的性能指标会不会有比较大的差异? 如果有的话, 说明不同的剪枝算法存在"鲁棒性"上的区别
- 什么原因导致不均匀的类别偏差? => 每次剪对(类别acc偏差)影响最小的权重? => 类别无偏的压缩算法
- 什么原因导致模型泛化性的下降? => 每次剪对(模型泛化性)影响最小的权重? => 泛化性能无损的压缩算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号