【Joslim】2021-ECML-Joslim: Joint Widths and Weights Optimization for Slimmable Neural Networks-论文阅读
Joslim
2021-ECML-Joslim: Joint Widths and Weights Optimization for Slimmable Neural Networks
来源:ChenBong 博客园
- Institute:CMU, FAIR, University of Texas at Austin
- Author:Ting-Wu Chin, Ari S. Morcos, Diana Marculescu
- GitHub:https://github.com/cmu-enyac/Joslim 3
- Citation:3
Introduction
layer-wise width 的 Slimmable Network
Motivation
Contribution
- 联合优化不同FLOPs下的不同子网的结构 (layer-wise宽度)和权重
Method
Problem formulation
将优化目标定义为(err-FLOPs)曲线下面积:

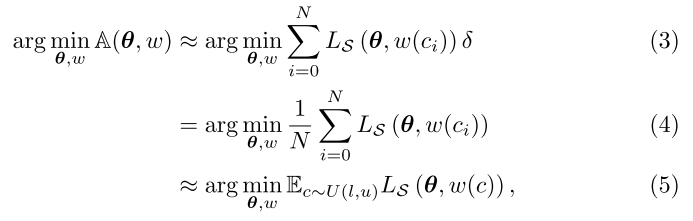
交替优化子网结构w和超网权重θ (用子网性能的期望代替曲线下面积):
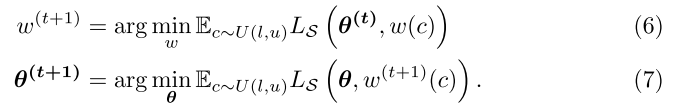
公式(6): 冻结超网权重, 优化区间内任意子网的结构, 使得每个子网的性能最高;
公式(7): 冻结区间内任意子网结构, 优化超网权重, 使得每个子网的性能最高;
公式(6)可以看做在固定的预训练超网权重上, 搜索区间内任意的子网结构 (类似OFA, BigNAS的搜索阶段), 可以使用进化算法等进行搜索, 但目标子网太多, 开销太大; 且每个迭代都要进行搜索的话, 开销太大
公式(7)意思应该是将区间内任意的子网结构都训练到收敛, 开销太大
Targeted sampling
针对公式(6)(7)待优化子网太多的问题, 每个迭代步骤不是优化区间内任意的子网结构, 而是只优化固定的M个FLOPs目标的子网结构 (用样本均值代替期望):
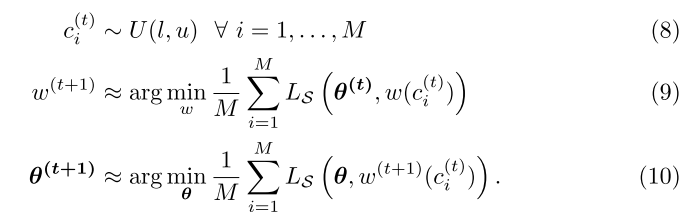
公式(9): 冻结超网权重, 优化区间内M个子网的结构, 使得每个子网的性能最高; 这里有一个问题, 在每个迭代中, 如何确定不同约束下最佳的M个子网结构?
公式(10): 冻结区间内M个子网结构, 优化超网权重, 使得每个子网的性能最高;
Local approximation
公式(10)的意思还是将M个子网都训练到收敛, 开销还是太大, 作者采用K步梯度下降 (每个子网训练K步) 来近似该结构的性能(K越大开销越大)
Temporal sharing
为了解决公式(9)中遗留的问题: 在每个迭代中, 如何确定不同约束下最佳的M个子网结构?
提出了一种使用历史数据点, 预测下一步的数据点的算法 MOBO_TS2(写的不是很清楚):

实验中, 历史数据集合的大小: \(|H| = 1000\)
总体算法

实验中M=2, 即每个batch训练max+rand2+min共4个子结构, 且这4个子结构梯度下降K次
其中rand2个子结构是使用MOBO-TS2算法生成的
Experiments
所对比的Slim(USNet), BigNAS是作者自己的实现 (改了一些配置以确保公平比较)
CIFAR-10/100
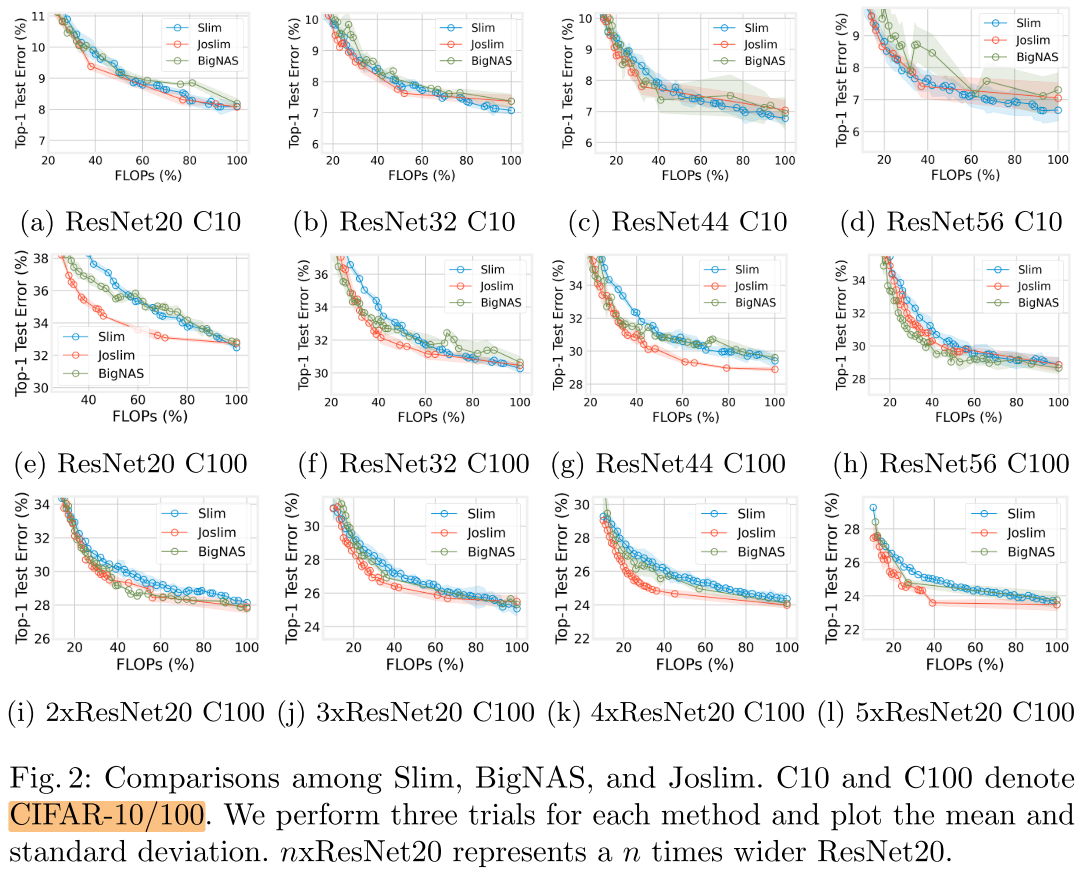
- CIFAR-10上, 3种方法性能相当
- CIFAR-100上, 越浅的网络Joslim的优势越大
- CIFAR-100上, 越宽的网络Joslim的优势越大 (&& 2345x的优势反而没有1x的优势大)
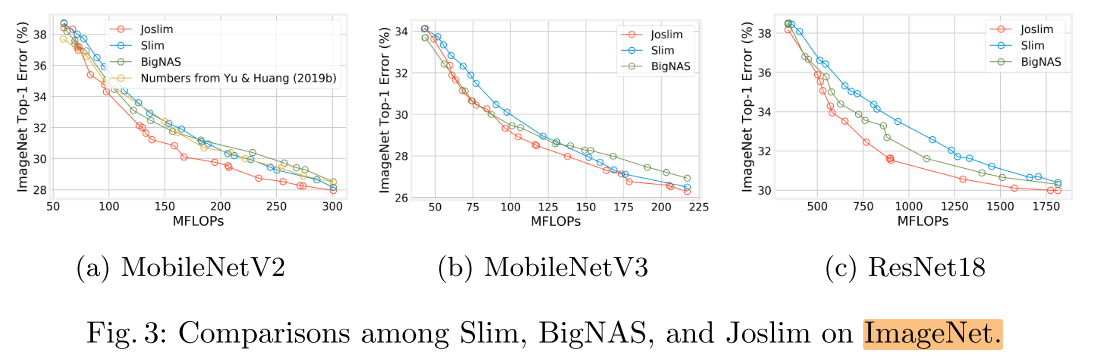
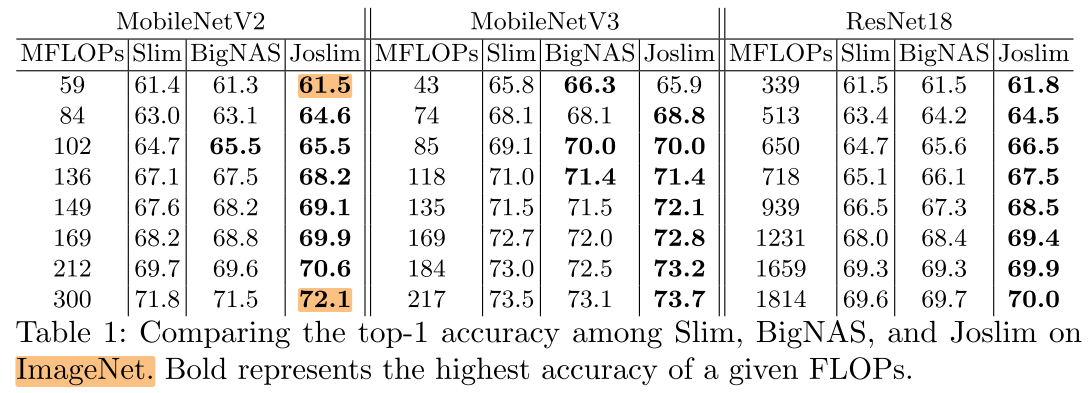
ImageNet
FLOPs
Latency 与 Memory foot-print
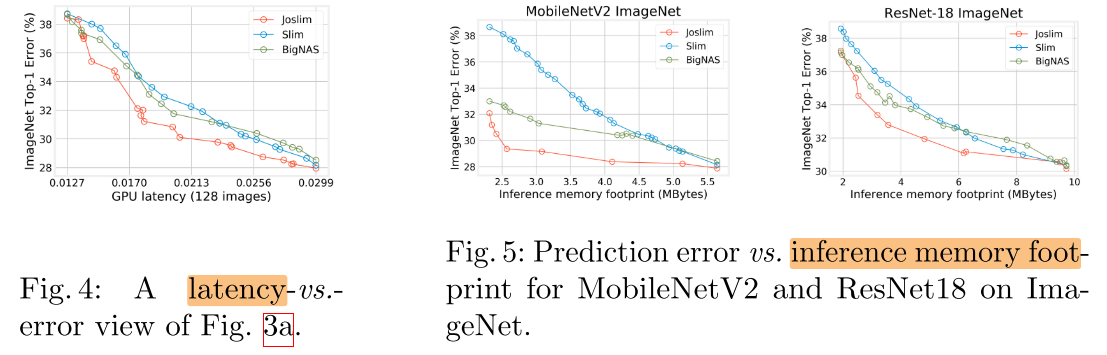
Memory foot-print(最大内存占用): 网络所需的最大内存:
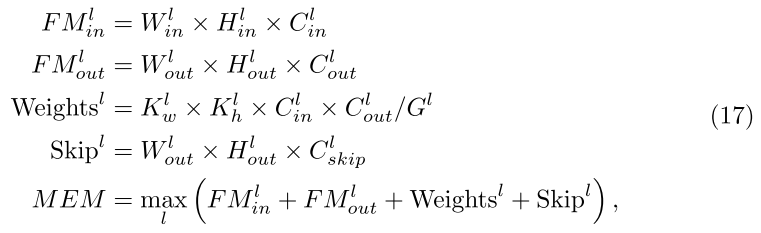
Ablation
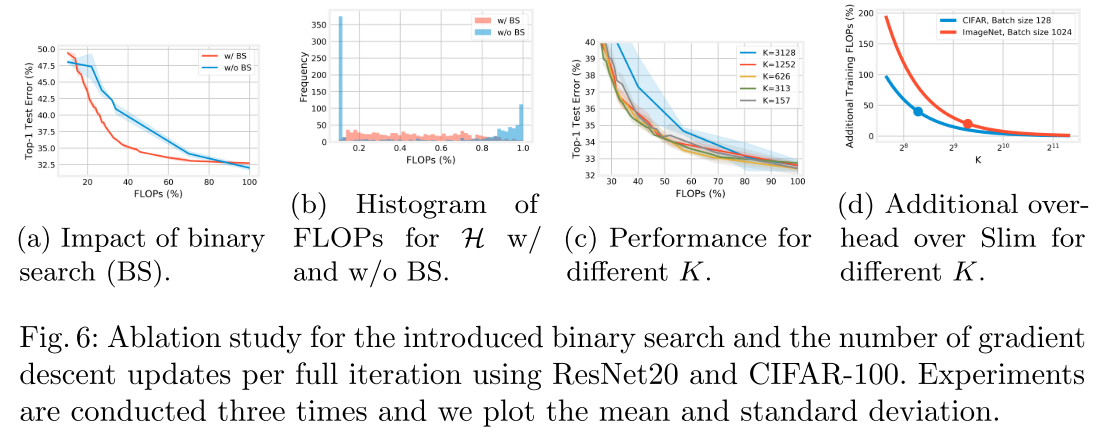
- MOBO_TS2中的二分查找可以让生成的子网FLOPs均匀分布(b), 从而提高性能(a)
- K步SGD中K的设置
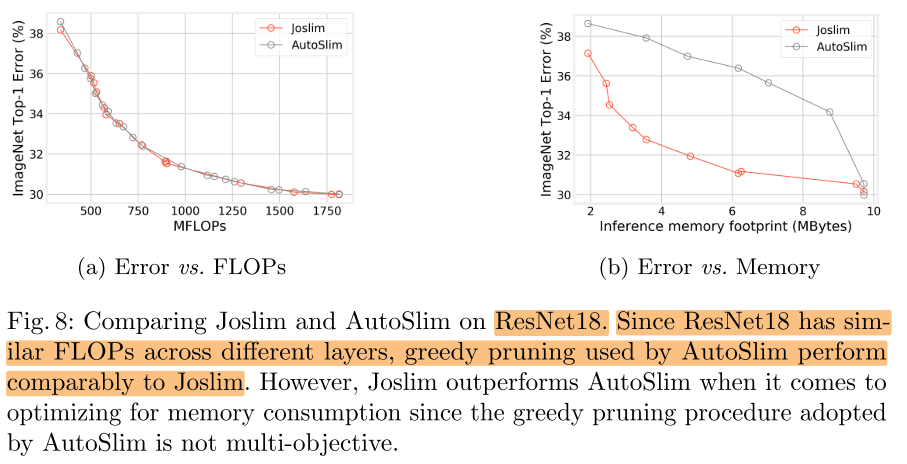
Compare with AutoSlim
将AutoSlim获得的不同子网的Layer-wise width提取出来, 训练Slimmable网络进行对比:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号