【Dynamic-OFA】2021-CVPRw-Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms-论文阅读
Dynamic-OFA
2021-CVPRw-Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms
来源:ChenBong 博客园
- Institute:University of Southampton
- Author:Wei Lou, Lei Xun, Amin Sabet, Jia Bi, Jonathon Hare, Geoff V. Merrett
- GitHub:https://github.com/UoS-EEC/DynamicOFA 10+
- Citation:2
Introduction
在OFA (Once for all) 的 pre-trained model 中提前搜好满足不同约束的多个子网, 将结构存储起来, 以便在推理时根据平台/可用资源动态切换.
Motivation
- 不同平台偏好的网络类型是不同的(GPU: 浅, 宽; CPU: 窄, 深)
- 同一平台推理时的可用资源是动态的
- 剪枝/NAS方法生成的是固定平台的固定网络, 无法针对不同平台, 或同一平台动态的资源进行切换
- 之前的动态切换的网络要么是针对宽度(Slimmable, Universal Simmable)进行动态切换, 要么是对深度进行动态切换, 但是不同平台偏好的网络类型是不同的 (不同平台下, 有时候需要浅的网络, 有时候需要深的网络), 本文的方法可以对4个维度进行动态切换(width, depth, filter size, input resolution, 其实就是OFA的4个维度)
- OFA使用进化算法, 在pre-trained model上 搜索满足指定约束的最优子网, 效率不高, 无法搜索大量网络
Contribution
改进了OFA的子网搜索算法, 使得每个子网的搜索成本大大降低, 所以可以提前搜好大量的子网, 以便在推理时动态切换
Method
OFA的子网搜索算法
随机搜索+进化算法, 以 Latency 约束为例
- 随机搜索: 先随机搜索找到满足 Latency 约束的一批子网
- 进化算法搜索: 以这批子网为初始种群, 执行进化算法, 一定时间后停止, 保留精度最高的那个
缺点: 低效(e.g. 第一步的随机搜索, 只要求子网Latency<目标Latency, 因此往往在不同 Latency 约束下给出相同的子网: 在30ms, 40ms, 50ms的约束下都搜出 30ms acc=75%的子网, 使得初始种群的质量不高)
Dynamic-OFA的子网搜索算法
同样是随机搜索+进化算法搜索
随机搜索中, 增加Acc作为 hard constrain, 迫使搜索算法在给定约束下找到性能较好的子网:

- 如果在 \(itr_n\) 次随机采样中, 没有采到满足Latency的子网, 则放松Latency约束
- 搜索结果存储在Patents中, 作为下一步进化算法的父代
- 随机搜索算法中的 Acc Predictor, Latency Predictor和OFA中一致
Dynamic-OFA 动态推理前的预处理
- 将搜索到的满足不同约束的子网(结构)存储为查找表
- 将这些子网的BN进行校正并单独存储(每个子网约2KB)
这样就可以在推理时根据资源对子网进行动态切换
Dynamic-OFA 动态推理的2种使用方法
- 使用查找表, 根据平台和约束直接查找特定子网, 进行一次性切换
- 根据可用资源情况, 动态增加/减少子网的规模(多次切换, 可用资源增加时, 逐渐切换到大的子网; 反之亦然)
Experiments
Setup
Nvidia Jetson Xavier NX平台:
- 384 core GPU
- 6 core CPU, use single-core CPU
ImageNet
在同一个超网中, 存在6个GPU最优子网, 7个CPU最优子网:
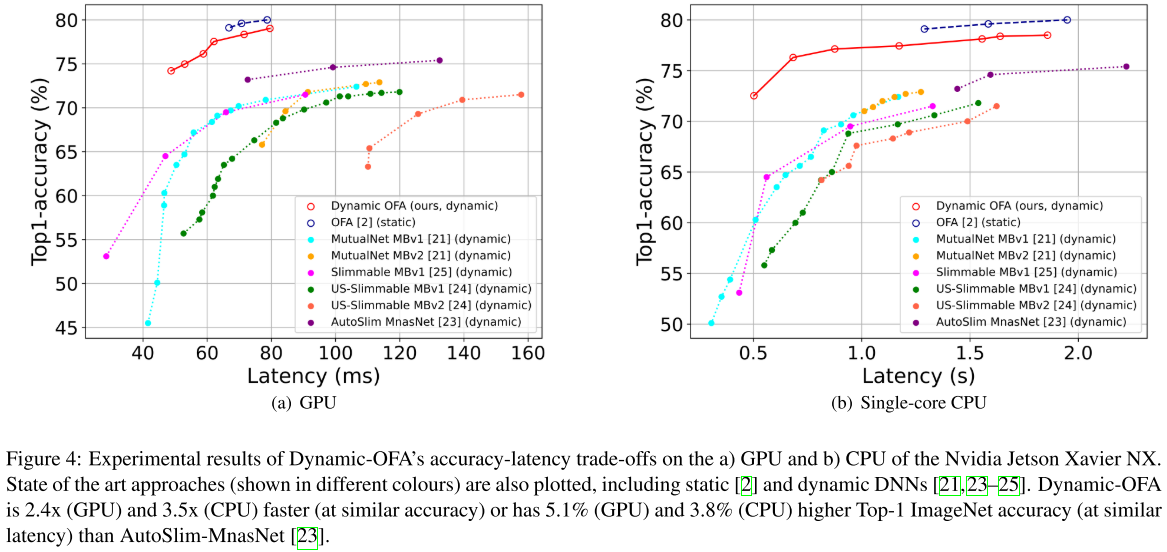
Dynamic-OFA在ImageNet上实现了79%(<600M)的Acc, 略低于OFA的 80%(<600M), 是由于OFA对单个子网进行了额外的fine-tune步骤, 我们的Dynamic-OFA包含13个不同的子网, 因此难以进行fine-tune
当资源限制发生变化时, 切换不同子网所需的时间

其中OFA的切换时间应该是将搜索时间也算进去了
应用场景
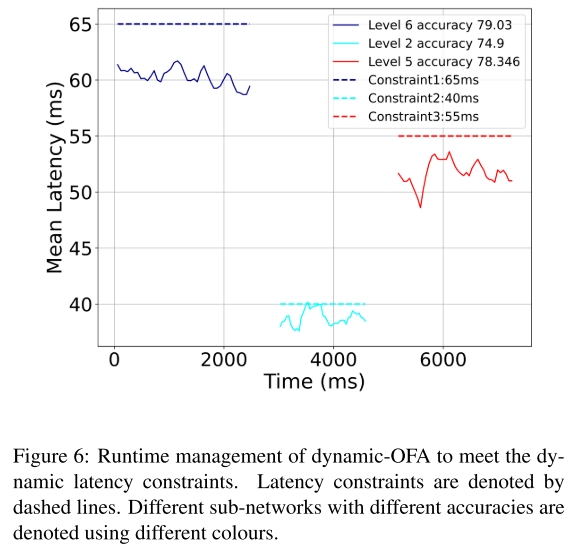
根据资源约束的变化切换子网
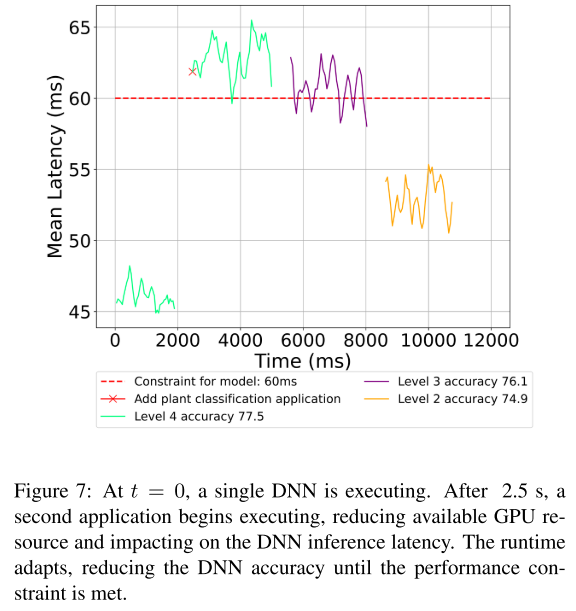
根据自身实时Latency的变换切换子网(在2.5s时加入了1个其他计算进程)
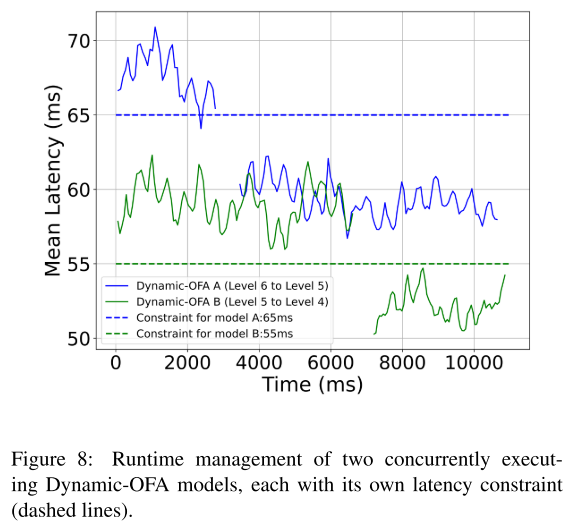
多个Dynamic-OFA 根据自身约束和约束动态调整

 浙公网安备 33010602011771号
浙公网安备 33010602011771号