【InstaNAS】2020-AAAI-InstaNAS: Instance-aware Neural Architecture Search-论文阅读
InstaNAS
2020-AAAI-InstaNAS: Instance-aware Neural Architecture Search
来源:ChenBong 博客园
- Institute:National Tsing-Hua University, Google Research
- Author:An-Chieh Cheng, Chieh Hubert Lin, Da-Cheng Juan, Wei Wei, Min Sun
- GitHub:https://github.com/AnjieCheng/InstaNAS 70+
- Citation:10+
Introduction
超网中包含一系列子网, controller用于搜索instance-aware的子网分布, 而不是单一的一个子网, 从而实现对困难的样本使用复杂的子网, 简单的样本使用简单的子网
- 训练一个超网, 包含一系列不同复杂度子网的分布, 每个子网都是某个特定领域的expert(不同难度, 纹理, 内容, 风格..)
- 训练一个controller, 可以根据样本, 从超网中选择一个适合该样本的子网
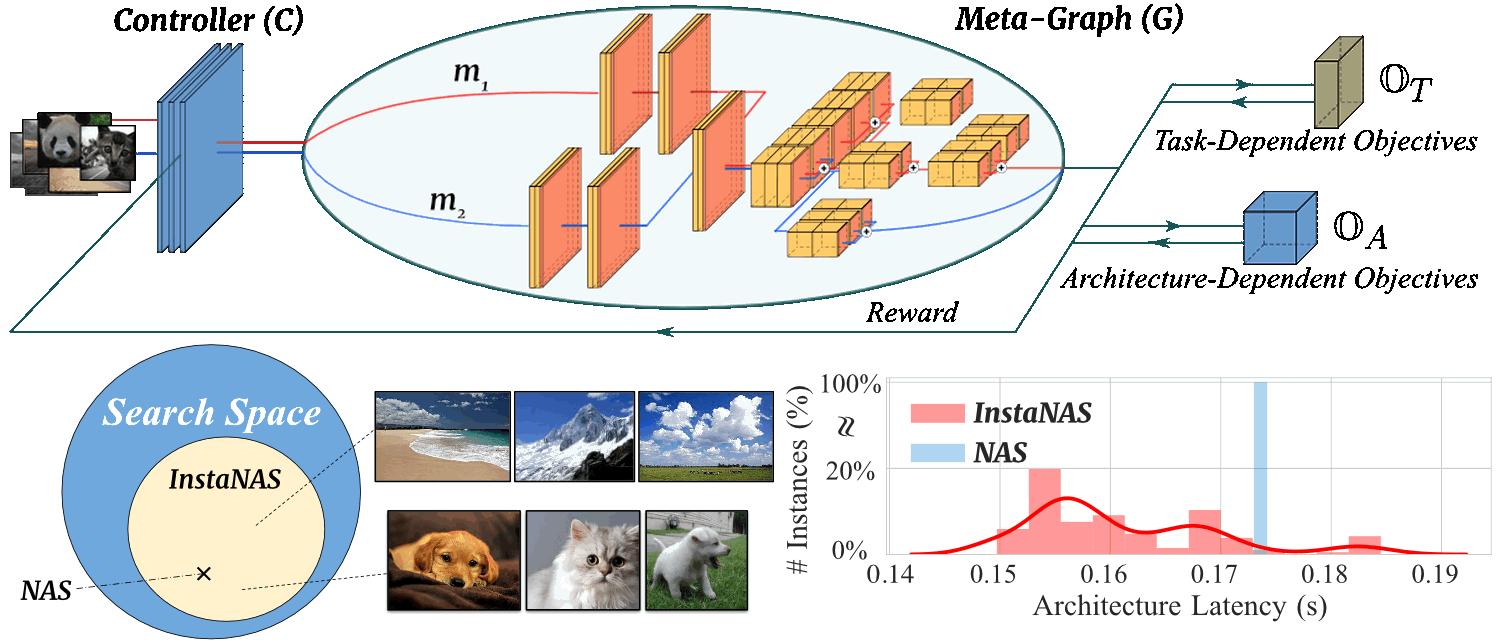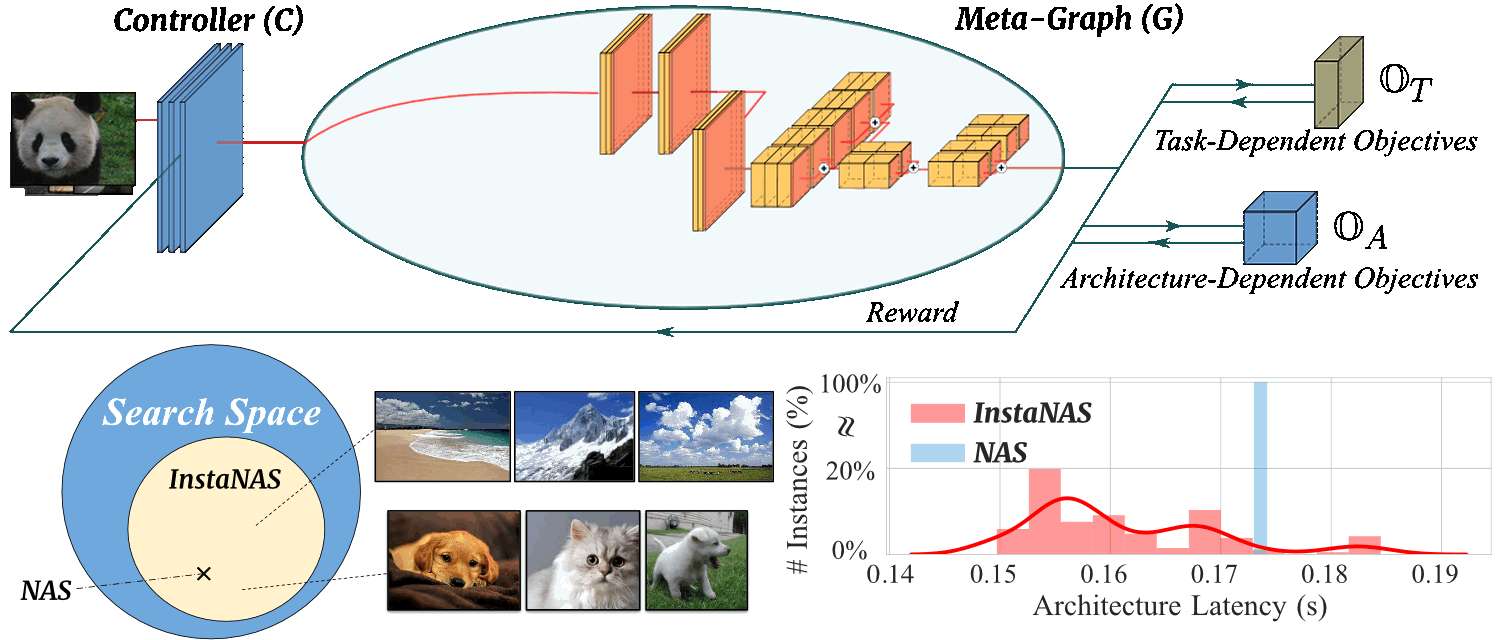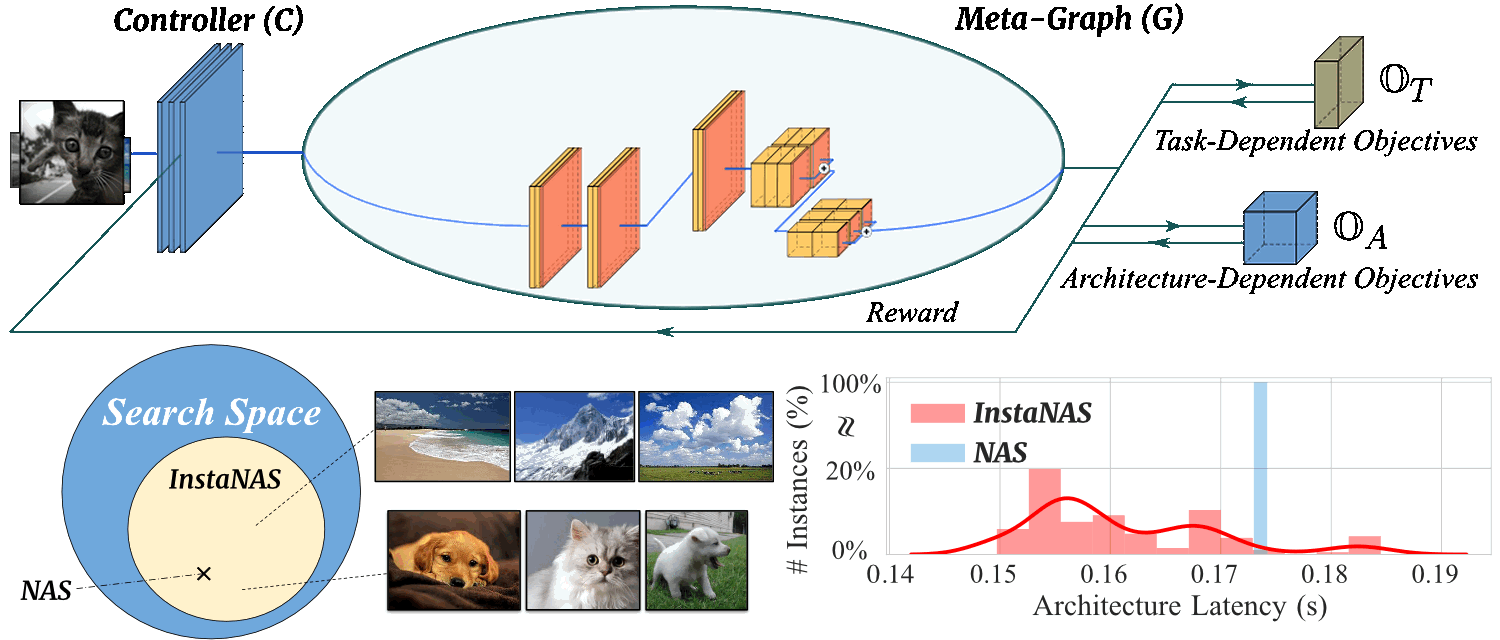
Motivation
- NAS可以搜索到满足多目标(高acc, 低FLOPs, 低Latency, etc.)的单一架构, 但实际不同实例难度不同, 困难的样本通常需要复杂的子网(深度, 宽度..), 简单的样本可以用简单的子网, 因此NAS搜索到单一子网, 实际上是对不同难度样本的tradeoff
Contribution
- 第一个 Instance-aware 的NAS方法
- 在相同性能的情况下, Latency大大低于MobileNetV2
Method
2个目标(Loss):
- 任务相关目标 \(O_T\) (Object Task), 精度Acc
- 结构相关目标 \(O_A\) (Object Arch), Latency
3个步骤:
- 预训练超网 (以 \(O_T\) 为目标, 只考虑精度)
- 联合训练 控制器和超网 (epoch交替训练, 冻结超网, 训练控制器; 冻结控制器, 训练超网), (控制器使用强化学习训练, Reward= \(O_T\) 和 \(O_A\))
- 固定控制器, 微调超网, (控制器固定后, 为每个样本选择的子网结构就固定了)
Supernet
共享参数的超网, 训练方式:
- 每个batch随机drop一部分path, (drop path rate, 超参数, 在训练中间阶段, 线性增加到0.5), 剩下的部分组成一个子网(等价于随机采样一个子网)
- 优化Acc, 即 \(O_T\)
Controller
控制器是通过策略梯度和奖励函数R来训练的,奖励函数是OT和OA
- 目的: 捕捉每个实例的低级特征(颜色, 纹理, 难度) &&难度是低级特征吗?
- 结构: 3层大kernel size的CNN
- 训练方式:
- 每个子网表示为1个一维的01向量, 每一维表示是否启用一个卷积核
- 控制器输入一个样本x, 输出一个概率向量p, 每一维为(0-1)的值, 表示启用某个卷积核的概率, 以0.5为阈值二值化概率向量p
- 使用鼓励参数\(\alpha\), 来改变概率向量: \(\boldsymbol{p}^{\prime}=\alpha \cdot \boldsymbol{p}+(1-\alpha) \cdot(1-\boldsymbol{p})\)
- 按照概率p, 使用伯努利分布, 采样子网进行训练
- 子网的梯度和控制器的梯度会被采样断开, 子网无法回传到控制器, 因此使用强化学习来训练控制器
- 奖励函数: \(R=\left\{\begin{array}{ll}R_{T} \cdot R_{A} & \text { if } R_{T} \text { is positive } \\ R_{T} & \text { otherwise }\end{array}\right.\) , 其中 \(R_T\) 表示精度奖励, 有正有负; \(R_A\) 表示延时奖励 [0, 1]; 目的是为了优先保证精度, 如果同时优化 \(O_T, O_A\), 精度和延时, 很容易崩溃为所有样本都选择最浅的网络, 来获得最高的延时奖励 (文中没具体写 \(R_T, R_A\) 是如何设计, 以及相关的训练细节)
Experiments
Setup
Search Space
MobileNetV2 bakcbone
- 17个cell
- 每个cell有5种选择
- 1 BasicConv
- 4 MBConv (ks=3,5; expansion ratio=3,6)
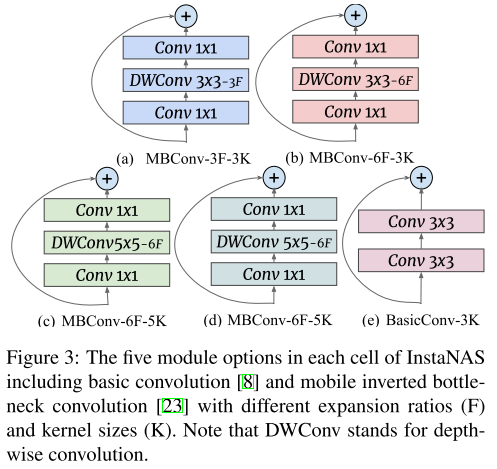
Supernet: 1.8G FLOPs
Controller: 21M FLOPs
Policy224(
(features): ResNet224(
(conv1): Conv2d(3, 16, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(blocks): ModuleList(
(0): ModuleList(
(0): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU6(inplace=True)
)
)
(1): ModuleList(
(0): BasicBlock(
(conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU6(inplace=True)
)
)
(2): ModuleList(
(0): BasicBlock(
(conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU6(inplace=True)
)
)
(3): ModuleList(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU6(inplace=True)
)
)
)
(ds): ModuleList(
(0): Sequential()
(1): Sequential(
(0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AvgPool2d(kernel_size=4, stride=4, padding=0)
(fc): Sequential()
)
(logit): Linear(in_features=128, out_features=85, bias=True)
)
Latency Profile
- i5 7600 CPU
- Lookup table
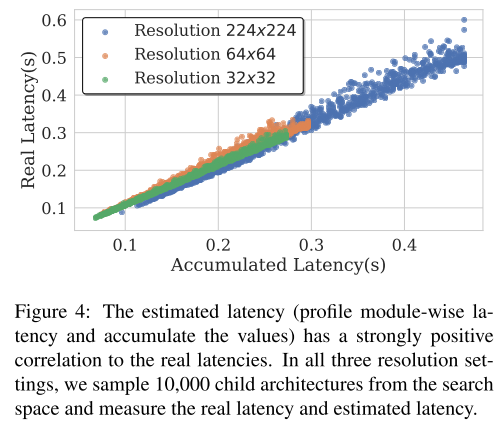
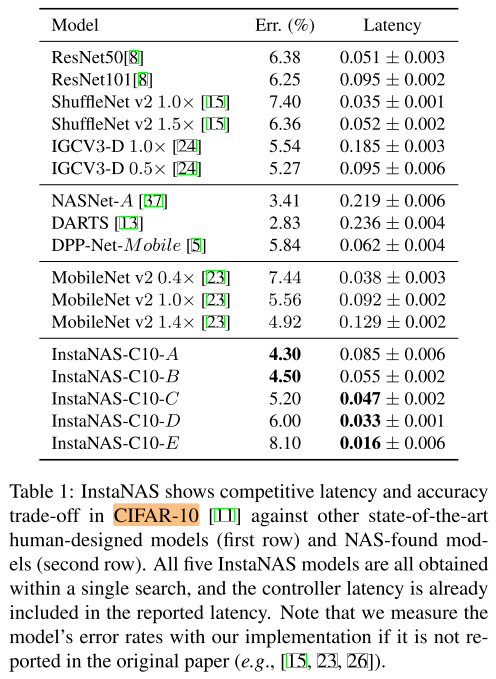
CIFAR-10/100

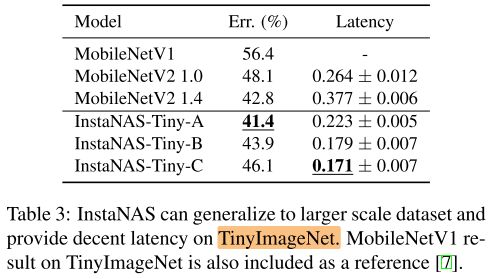
TinyImageNet
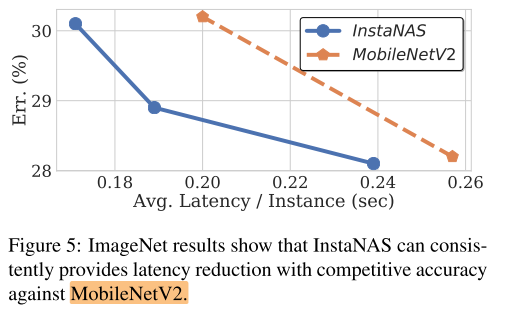
ImgeNet
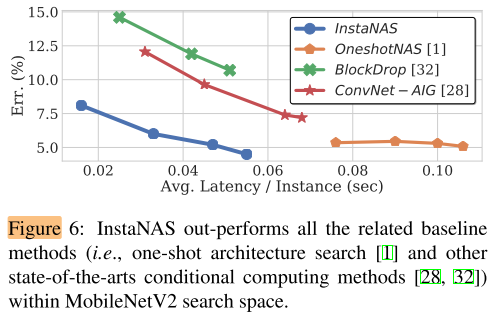
可视化

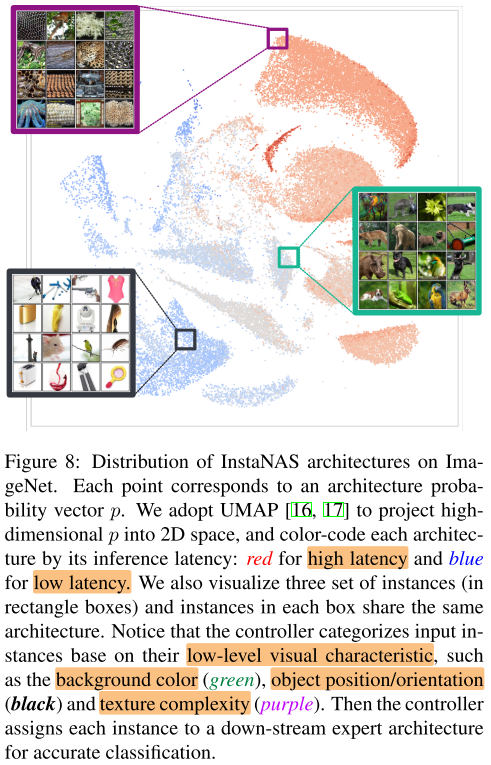
Conclusion
Summary
pros:
- 第一个做 Instance-aware 的动态NAS
cons:
- 方法的关键步骤, Controller的训练细节没有写清楚
- 实验部分没有写清楚训练开销
- 代码中前向是mask的方式, 不能做到实际的加速, 实验中算的应该是理论加速比
To Read
Reference
强化学习(十三) 策略梯度(Policy Gradient) - 刘建平Pinard - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号