【TF-NAS】2020-ECCV-TF-NAS: Rethinking Three Search Freedoms of Latency-Constrained Differentiable Neural Architecture Search-论文阅读
Three-Freedom NAS
2020-ECCV-TF-NAS: Rethinking Three Search Freedoms of Latency-Constrained Differentiable Neural Architecture Search
来源:ChenBong 博客园
- Institute:CASIA, JD AI Research
- Author:Yibo Hu, Xiang Wu, Ran He (H44)
- GitHub:https://github.com/AberHu/TF-NAS 50+
- Citation:10+
Introduction
可微分的Macro NAS(backbone确定, 搜索backbone中每个layer的op, stage的layer num, width num), 搜索精确满足 Latency Constrain 的网络结构
在operation sample (layer wise), depth sample (block wise), width sample (network wise) 3个方面对原始的可微Macro NAS进行改进
Motivation
之前的方法的搜索粒度较粗, 不能搜索到精确满足 Latency Constrain 的网络结构(e.g. target=15ms, 14.3ms 15.7ms)
Contribution
Related Work
Micro Search: 搜索足够鲁棒的cell, 将同样的cell堆叠N次 (搜索的空间比较小)
Macro Search: 搜索整个backbone中每个layer的op, stage 的 layer num, width num(搜索空间比较大)
Method
Review of Differential NAS
\(\min _{\alpha \in A} L_{\mathrm{val}}\left(\omega^{*}, \alpha\right)+\lambda C(L A T(\alpha)) \qquad (1)\)
s.t. \(\quad \omega^{*}=\arg \min L_{\text {train }}(\omega, \alpha) \qquad(2)\)
\(x^{l+1}=\sum_{i} u_{i}^{l} \cdot \mathrm{op}_{i}^{l}\left(x^{l}\right), u_{i}^{l}=\frac{\exp \left(\left(\alpha_{i}^{l}+g_{i}^{l}\right) / \tau\right)}{\sum_{j} \exp \left(\left(\alpha_{j}^{l}+g_{j}^{l}\right) / \tau\right)} \qquad(3)\)
使用 gumbel softmax 添加随机性, u为gumbel softmax后的概率分布.
\(L A T(\alpha)=\sum_{l} L A T\left(\alpha^{l}\right)=\sum_{l} \sum_{i} u_{i}^{l} \cdot L A T\left(\mathrm{op}_{i}^{l}\right) \qquad(4)\)
根据事先构建的查找表来估计整个网络的Latency
Search Space
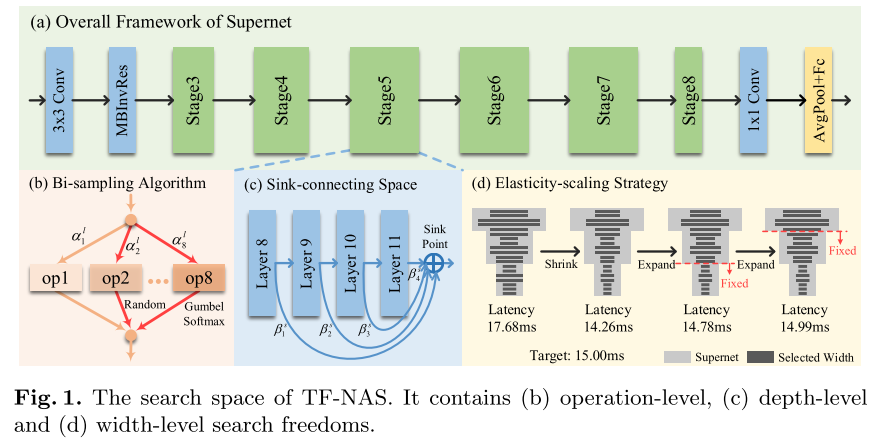

Three-Freedom NAS
Operation-level Freedom -- bi-sampling
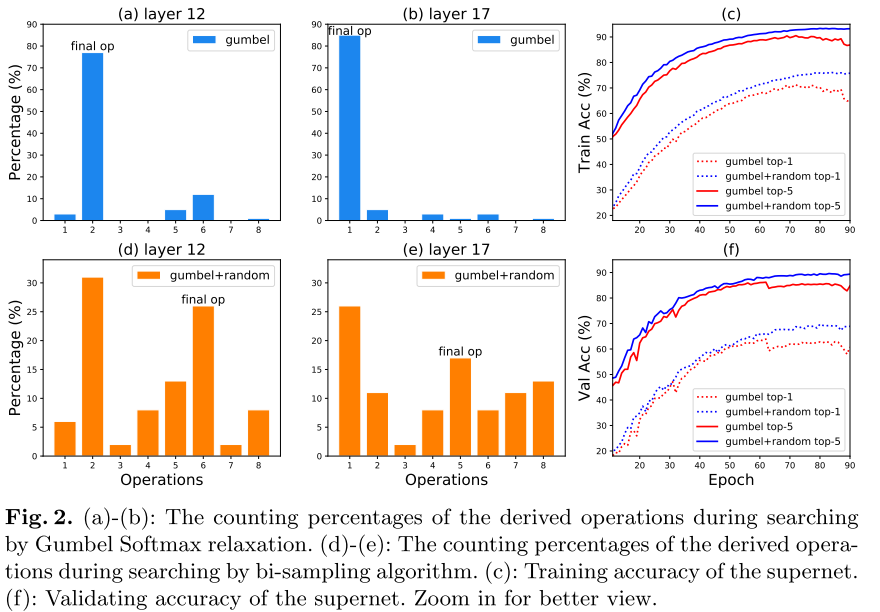
可微NAS中 one path 的采样策略, 会偏向某些op, 导致这些op被采样的概率过高, 得到优化的机会也更多, 导致operation collapse, 虽然温度系数 \(\tau\) 可以让采样分布在初期变得平滑, 但最后总要收敛, 因此op collapse依然存在(图2 ab)
为了解决这个问题, 作者提出 bi-sampling 的采样策略, 即每个batch采样2个path( gumbel sample + random sample, 2次forward, 1次backward), 经过统计发现op collapse的现象减轻了, 且supernet 在训练集和验证集上的精度都提高了(图2 cf)
Depth-level Freedom -- sink-connecting
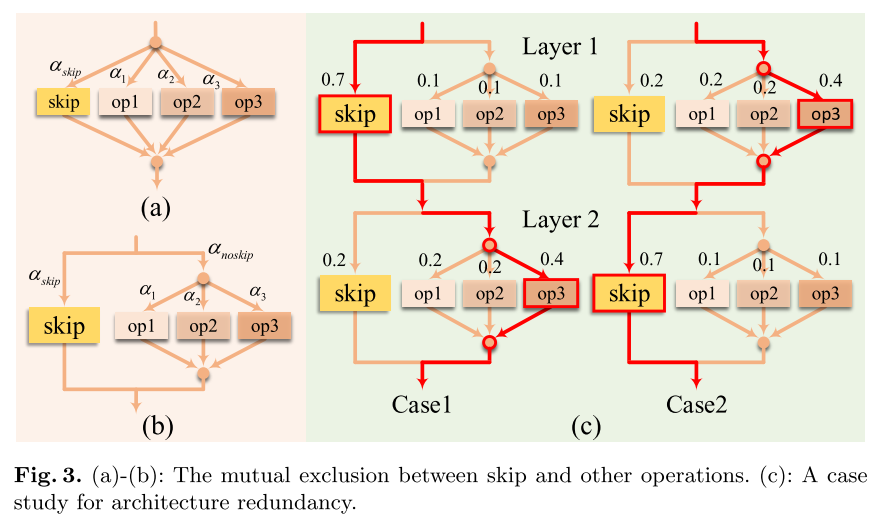
在之前的方法中, skip-connection当成一种普通的op, 与其他op一起参与可微优化(图3 a)
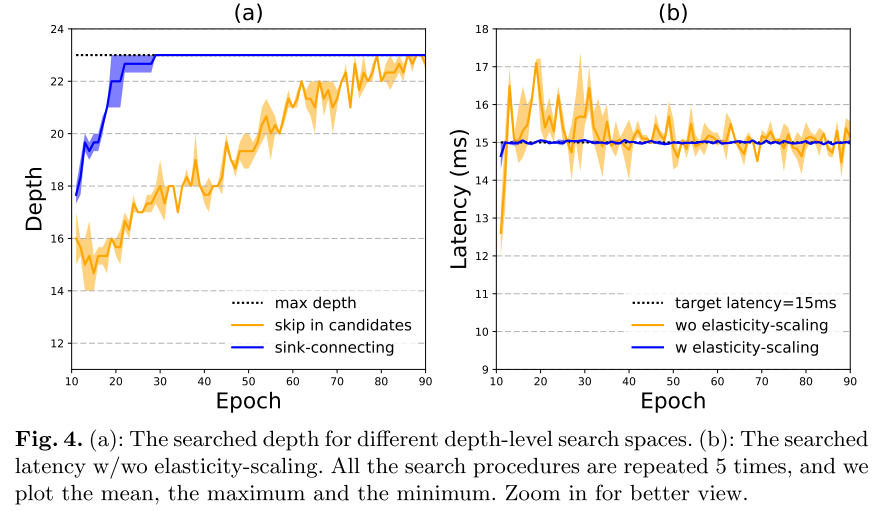
作者认为skip会导致训练中(尤其是训练早期), 网络层数有较大的抖动, 且超网倾向于选择skip(skip α的梯度相对于其他op来说更大) 导致网络的层数较浅(图4 a)
因此作者认为需要将skip与其他op独立开来(图3 b), 但将skip独立出来以后(其实不独立出来也会), 会出现结构冗余(图3 c)
为了解决结构冗余, 作者提出一种skip与其他op互斥的搜索空间sink-connecting(图1 c):
Width-level Freedom -- elasticity-scaling
实际上解决精确的 latency constrain 的只有elasticity-scaling
之前的NAS搜索空间尽管很大(\(10^{21}\) for FBNet), 但可选的 latency 是有限且离散的 (e.g. target=15ms, 14.3ms / 15.7ms), 无法精确满足所需的latency约束
为了实现精确地满足 latency约束, 作者提出 elasticity-scaling 的搜索空间, 即逐渐调整layer-wise宽度, 以精确达到目标latency 约束: \(\gamma \cdot sn_{i:j} (i=3 \sim 8, j=8)\)
- 初始使用 global 的宽度系数 \(\gamma \cdot sn_{i:j} (i=3)\)
- 逐渐减小宽度系数的作用范围: \(\gamma \cdot sn_{i:j} (i=4,5...8)\)
加入elasticity-scaling后, 可以很快达到目标latency
Experiments
Setup
- Dataset: ImageNet
- GPU: 1 × Titan RTX
- Latency: 构建每个 op 在GPU上 latency 的查找表
- Supernet searching: 使用 ImageNet100 训练 90 个epoch, 最开始的10个epoch不对结构参数进行更新 (1.8 GPU day) (&& 每个target latency都要搜索一次?)
- 最佳子网: 在 ImageNet 上 train from scratch 250个epoch, 标准的数据增强, 没有使用auto-augmentation/mixup (&&每个子网的重训开销50 GPU days?)
ImageNet
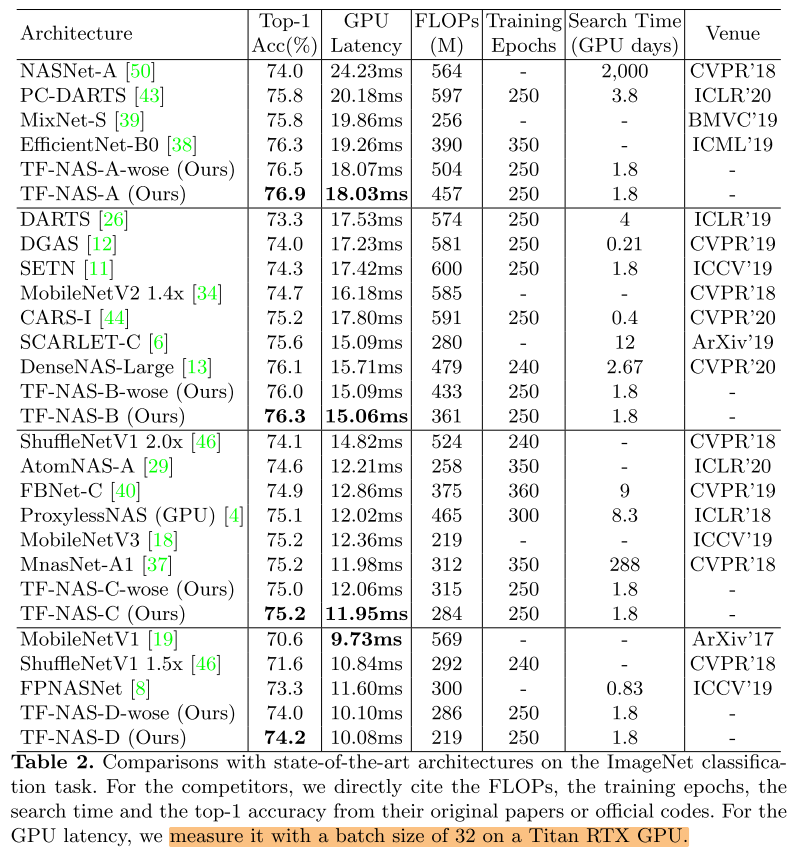
Ablation
bi-sampling
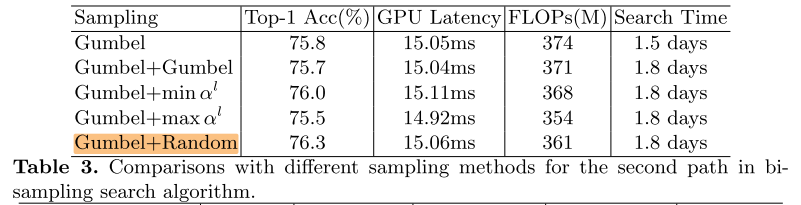
第二个path的sample使用random的效果最好, gunbel+gumbel 或 gumbel+max会有负面的效果
sink-connecting

将skip分离可以提高搜索结果的性能(+0.5%)
进一步使用sink connection可以进一步提高结果性能(+0.2%)
Elasticity-scaling
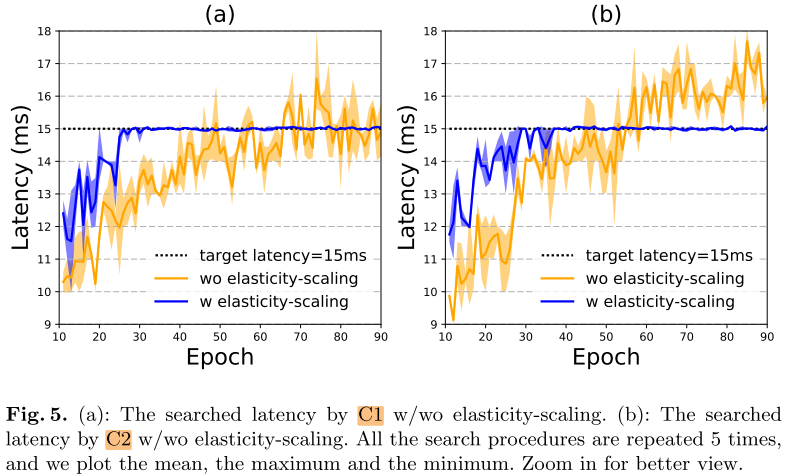

其他2种方法的Latency约束, 加上Elasticity-scaling 后, 也可以很快收敛到目标 latency
Conclusion
Summary
pros:
- 分离op与skip的方式比较简洁
cons:
- bi-sample实际上增加了训练开销(1.2x), 没有在相同训练开销的情况下与singe-sample进行对比(图2 c)
- 精确的 latency constrain 的motivation是否足够充分? (target=15ms, 15.3ms vs 15.1ms)
- 只做GPU Latency的实验感觉比较奇怪(CPU, mobile device)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号