2021-ICLRw-How Does Supernet Help in Neural Architecture Search? - 论文阅读
How Does Supernet Help in Neural Architecture Search?
2021-ICLRw-How Does Supernet Help in Neural Architecture Search?
来源: ChenBong 博客园
- Institute:MSRA
- Author:Yuge Zhang, Quanlu Zhang, Yaming Yang
- GitHub:/
- Citation:2
与2020-ArXiv-Deeper Insights into Weight Sharing in Neural Architecture Search同一个团队
Introduction
基于超网的NAS方法, 5个搜索空间上进行实验的一些发现:
- 一个well-trained 的supernet, 不一定是一个好的 subnet ranking model
- supernet作为ranking model的有效性, 与搜索空间有关(有的空间上, supernet ranking相关性高, 有的低)
- supernet 更擅长发现相对好的子网(top 10%), 而不擅长发现最好的(top 1%)的子网
- 相比与发现好的子网, supernet更擅长发现差的子网(可以用于search space pruning)
- supernet在小的搜索空间上ranking效果差
- 但如果一个小的搜索空间是经过合适地剪枝, (虽然ranking效果差) 但超网反而更容易发现好的子网 (top ranking的子网gt性能更高)
- supenet有固有的偏好(bias), e.g. 更偏向某些operation(这些operation的子网ranking高)
Motivation
- supernet NAS 很有效, 但缺乏理论的解释;
- 很多工作通过实验对supernet NAS进行分析, 但仍存在局限性(e.g. 搜索空间单一)
Contribution
- 第一次在多个搜索空间上进行广泛实验
- 第一次分析了搜索空间的剪枝
Method
Training Setup
最朴素的supenet NAS: uniform sampling (SPOS)
超网训练的目标:
- 最小化所有子网的训练损失
- 提供一个相关性高的子网性能评估器
Search Space
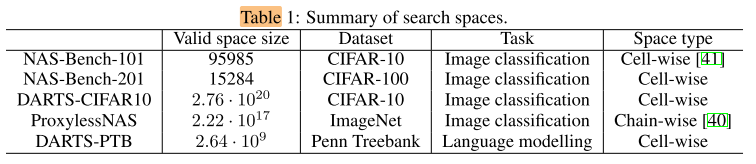
Metrics
衡量子网:
- Ground truth performance (ground truth): subnet train from scratch的acc1
- Supernet performance: subnet 继承超网权重, 校正BN后的acc1
衡量空间:
- avg ground truth
- avg supernet performance (目标1: 最小化所有子网的训练损失)
- (GT与sp的)Correlation (目标2: 提供一个相关性高的子网性能评估器): 随机采样的子网的Supernet performance 与 ground truth 之间的相关系数 (Spearman correlation), 采样个数: (1k for NAS-Bench series, 100 for DARTS series, 20 for ProxylessNAS)
- Top-k: 随机采样1k个 subnet, 基于supernet performance选择 top-k个, 查询这k个subnet对应的gt, 报告最高的gt acc1
Experiments
确定了搜索空间后, 探究不同的训练设置(epoch)对各个metric的影响
number of epochs
超网训练的epoch对各个metric的影响
3个metric:
- avg supernet perf (目标1: 最小化所有子网的训练损失)
- Correlation (目标2: 提供一个相关性高的子网性能评估器)
- top-k (目标2: 提供一个相关性高的子网性能评估器)
avg supernet perf
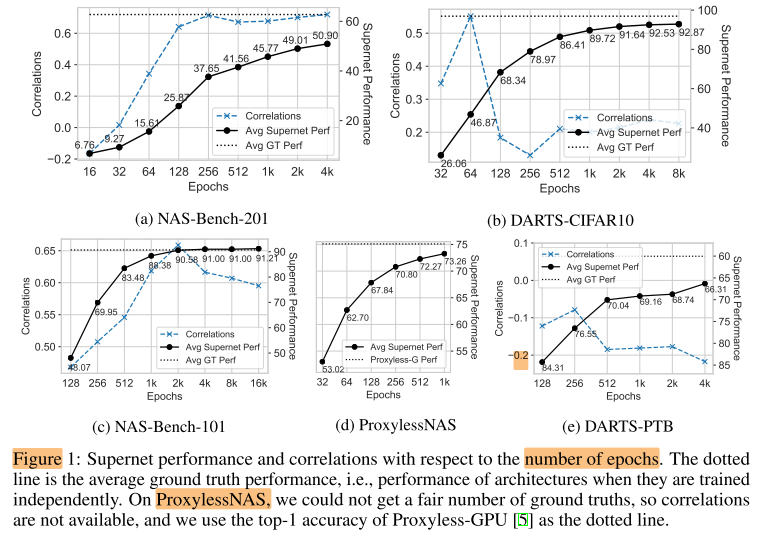
- 增加训练epoch, 可以提高5个搜索空间上的 avg supernet perf
- ProxylessNAS上, 仅有2%的差距(可能可以通过继续增加epoch来达到avg GT perf); 在NAS-Bench-101上, avg supernet perf 甚至超过了avg GT perf
- 但在其他3个搜索空间上, 增加epoch带来的增长趋于稳定, 且仍有较大差距, 似乎存在一个固有的上限
- ==> 说明在部分搜索空间中, 通过训练超网来同时优化大量的子网是可能的, 但需要较大的计算开销(或其他训练技巧)
Correlation
虽然 avg supernet perf 随着epoch的增加持续上升, 但相关性并没有这样的趋势
- 随着epoch的增加, correlation开始上升, 但很快饱和, 甚至开始下降, DARTS-PTB空间上, 甚至随着epoch增加, correlation降为负值
- avg supernet perf与correlation没有相关性(avg supernet perf高的空间, correlation不一定高)
- ==> 说明超网训练的2个目标: 1. 最小化所有子网的训练损失 2. 提供一个相关性高的子网性能评估器; 2个目标之间存在gap, 两个目标不相关甚至互相冲突(不能同时达到)
Top-k
所有子网的ranking质量(Correlation)只是一个中间指标, top-k的子网质量对于supernet NAS来说更重要
ps.
- top1/10 指使用supernet生产的rank, 取top1/10的子网中的best GT
- random top1/10 指生成随机rank, 取top1/10的(随机取1/10个)子网中的best GT(可以作为baseline)
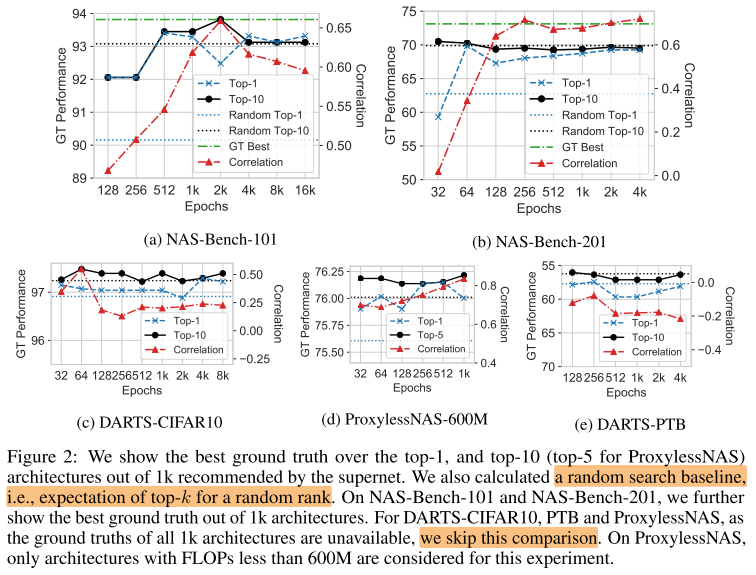
- top10基本上都比top1更好 ==> supernet有助于找到较好的网络, 但很难找到最好的
- 较好的correlation通常会产生较好的top1和top10
- DARTS-CIFAR10的使用超网rank找到的 top1/10 优势最大, DARTS-PTB甚至比随机的baseline更差 ==> weight sharing NAS的有效性与搜索空间有关
Bias of Weight Sharing NAS
上一节说明了Weight Sharing NAS的有效性(ranking的质量)对不同搜索空间的bias(偏好)
这一节讨论Weight Sharing NAS在同一个搜索空间内, 对不同子网的bias(偏好)
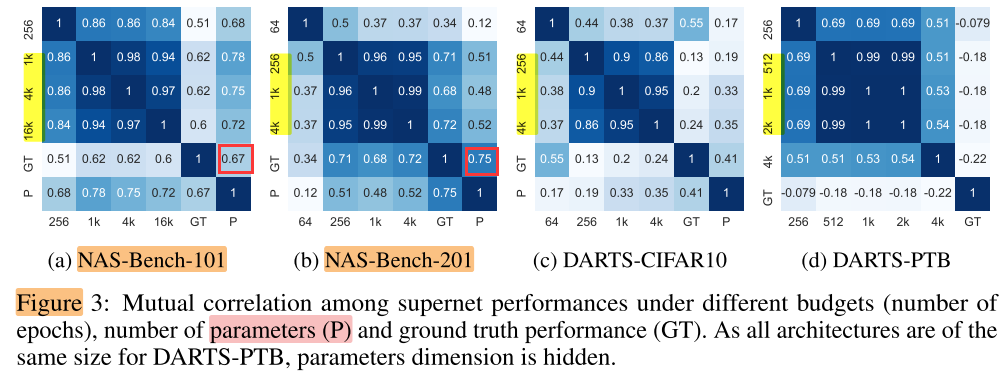
不同的epoch, 子网rank相似度很高 => 增加epoch几乎不再改变子网rank => rank进入稳定状态, 但这个稳定状态和GT的rank还有较大的差距, 说明weight share NAS与GT之间的bias(偏差)是真实存在的
Bias towards big models
一般来说, 模型越大, 性能越好, 因此如果直接用模型大小来预测性能, 也能得到一组rank
对于包含不同大小的子网的搜索空间(NAS-Bench-101)来说,
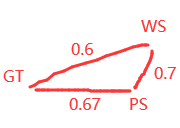
ps. param生成的rank(PS); GT的rank(GT); weight sharing NAS生成的rank(WS)
- PS与GT相似度高达(PS, GT)=0.67, 超过了所有WS与GT: (WS, GT)=0.6 => (PS, GT) < (WS, GT)
- WS与PS的相似度(WS, PS=0.7) 高于 WS与GT(WS, GT)=0.6 => WS, 说明WS比GT更偏好参数量大的子网(对参数量大的子网的rank更高)
Bias towards certain operators
supernet会偏好某些operation(让选择了这些op的子网性能更高), 但不一定说明这些op在train from scratch时性能也会较好
分组抽样
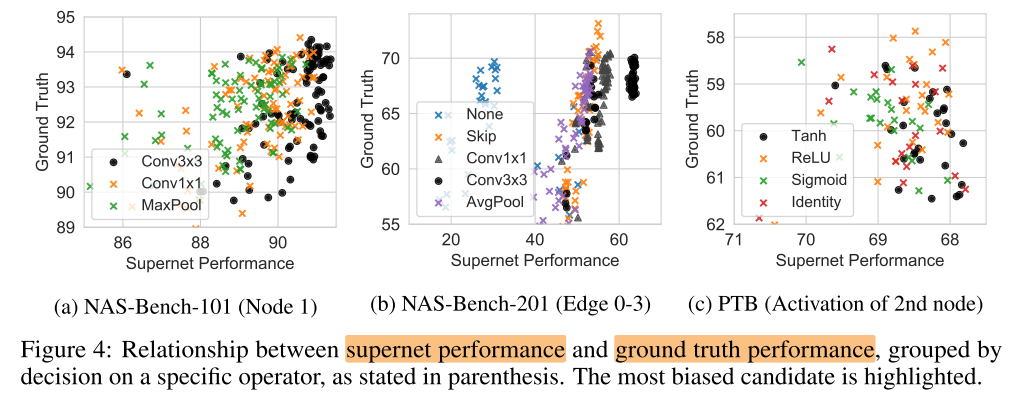
在NAS-Bench-201中, 超网认为选择了conv3x3的子网性能更好, 但在GT中, 性能最好的子网大部分都是选择skip
Pruned Search Space
Intuition: 减小空间, 降低子网的互相干扰; 提高空间的整体质量, 使得baseline提高
Effectiveness of Pruning
- Optimistic Pruning: Prune architectures with the worst ground truth performance
- Random Pruning: Prune a random part of search space
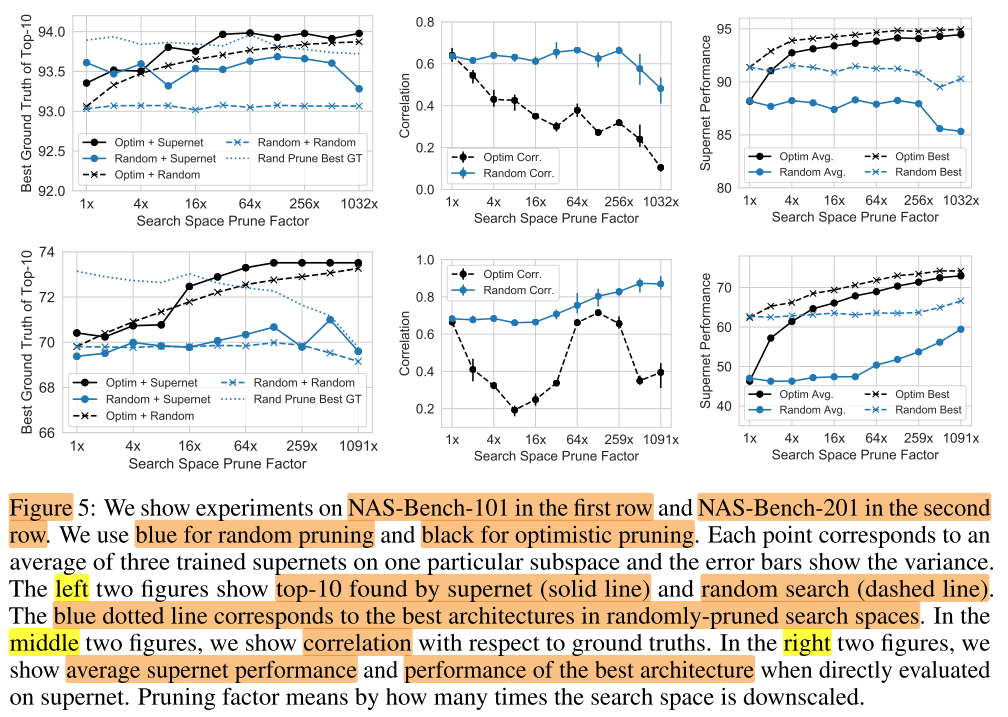
第一行NAS-Bench-101, 第二行NAS-Bench-201, 每个点是3个supernet上的平均值
左
-
图例
- 2种空间剪枝方式:
- 最优空间剪枝(黑色);
- 随机空间剪枝(蓝色)
- 2种搜索方式:
- 使用超网rank搜索top10(best GT)(实线);
- 使用随机搜索(随机抽10个, 取best GT)top10(虚线)(代表空间的平均子网性能)
- 2种空间剪枝方式:
-
蓝色虚线不随prune factor上升 ==> 随机空间剪枝不能提高空间的评价子网性能;
-
黑色虚线随着prune factor 上升 ==> 而最优空间剪枝可以提高空间的平均子网性能
-
蓝色实线不随着prune factor 上升 ==> 随机空间剪枝不能提高超网的top10, 不能提高超网找到优质结构的能力
-
黑色实线随着prune factor 上升 ==> 最优空间剪枝可以提高超网的top10, 即可以提高超网找到优质结构的能力
中
- GT 与supernet perf的相关性Correlation
- ==> Correlation与空间剪枝率没有明显的关系(无论哪种剪枝方式), 也就是增加空间剪枝率(使用小空间)不会提高相关性, 但
右
- 图例
- avg (supernet perf)
- best (supernet perf)
- ==> 最优空间剪枝可以提高评价子网性能以及最佳子网性能, 随机空间剪枝不一定可以
Conclusion
Summary
- 子网rank的相关性是一个很困难的问题, 不同子网间的权重共享导致固有的相互干扰, 目前的超网NAS中好像还没有任何方法可以在权重共享的情况下提高子网rank的相关性
- 根据上一篇的结论, 子网继承超网权重, 进行少量(10个batch)的fine-tune(不共享权重), 可以显著提高rank的相关性
- 另一种做法是通过对空间进行适当的剪枝, 提高空间的整体子网质量, 不能提高rank相关性, 但可以提高找到优质子网的能力(baseline提高了)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号