【Deeper Insights into Weight Sharing NAS】2020-ArXiv-Deeper Insights into Weight Sharing in Neural Architecture Search-论文阅读
Deeper Insights into Weight Sharing in NAS
2020-ArXiv-Deeper Insights into Weight Sharing in Neural Architecture Search
来源: Chenbong 博客园
- Institute:MSRA
- Author:Yuge Zhang, Zejun Lin, Junyang Jiang, Quanlu Zhang
- GitHub:https://github.com/ultmaster/deeper-insights-weight-sharing 4+
- Citation:14+
Introduction
研究了基于参数共享的超网训练方式是否真正有效.
Motivation
- 超网训练在很多实验中被证明对减少(搜索)训练开销有效, 但并没有理论上的研究和证明
- 基于参数共享的超网训练方式, 基于一个假设:
- 对超网中的不同子网进行训练, 可以同步优化各个子网的权重, 提高各个子网的性能 √
- 但是各个子网之间存在互相的干扰, 导致每个子网都无法被优化到 train alone 的程度 √
- 但互相的干扰不会(或很小)影响子网之间的相对性能排序(排序稳定的假设), 因此训练后的超网可以作为一个所有子网的性能评估器, 找到最佳的子网 (?)
- 几个问题有待解决:
- 通过超网训练方式找到的最佳子网, 与搜索空间中的最佳子网距离远吗?
- 在多次run中, 最佳子网是稳定的吗?
- 权重共享是如何影响搜索结果的精度和稳定性的?
Contribution
- 作者通过大量实验观察发现:
- 不同 seed run下的最佳子网 (使用 supernet 评估出来的 rank1 子网) 是不同的, 而且方差很大 ==> 排序不是稳定的
- 子网之间的互相干扰是导致不同run方差大的主要因素
- (通过精心设计)适当地减小权重共享的程度, 可以降低不同run的方差并提高超网训练的表现
- 虽然有很大的方差, 我们依然可以从超网的训练过程中提取有价值的统计信息, 从而指导搜索空间的调整
- 定义了一种新的metric来评估基于 weight share 的NAS方法
- 一些观察和发现 (不同run直接的高方差)
- 解释了高方差的来源, 并使用降低权重共享程度的方式, 降低了方差
Method
Search Space
经典的supernet NAS的搜索空间都很大(\(10^{10}\)), 无法将搜索空间中的每个子网都完全训练, 导致没有ground truth, 不利于实验研究
我们认为, 如果supernet NAS在大搜索空间上有效, 那么在小搜索空间上也应该有效, 因此我们设计了一个小的搜索空间进行实验:
每个子网由4个相同的cell组成, 每个cell内部有n个输出, 输出之间是密集连接: \(x_{j}=\sum_{0 \leq i<j} O_{(i, j)}\left(x_{i}\right)\) , 在连接上是不同的操作 \(O(i,j)=\{1,2,3,4\}\)
我们取n=2, 即每个cell可以表示为 \(O(0,1), O(0,2), O(1,2)\) , 因此一共有 \(4^{4}=64\) 种cell, 即64种子网
(这种搜索空间和 通道left n的搜索空间有点区别, 本文这种空间不同的子网基本上大小一致, 而且不会不同子网互相包含的情况)
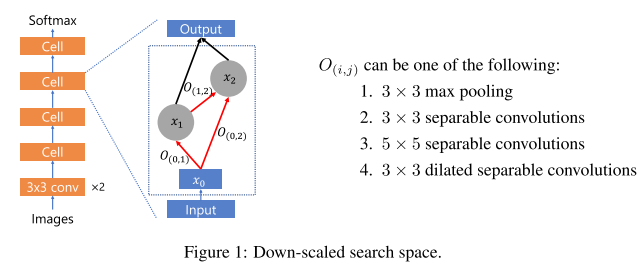
训练方式
Setup
- CIFAR10
- K80
- SGD, momentum=0.9, weight decay=1e-3
- init lr=0.025, cosine schedule, annealed down to 0.001
- batch size=256
- epoch=200
Ground Truth
64个子网单独训练, 每个子网都用10个seed训练10次取平均
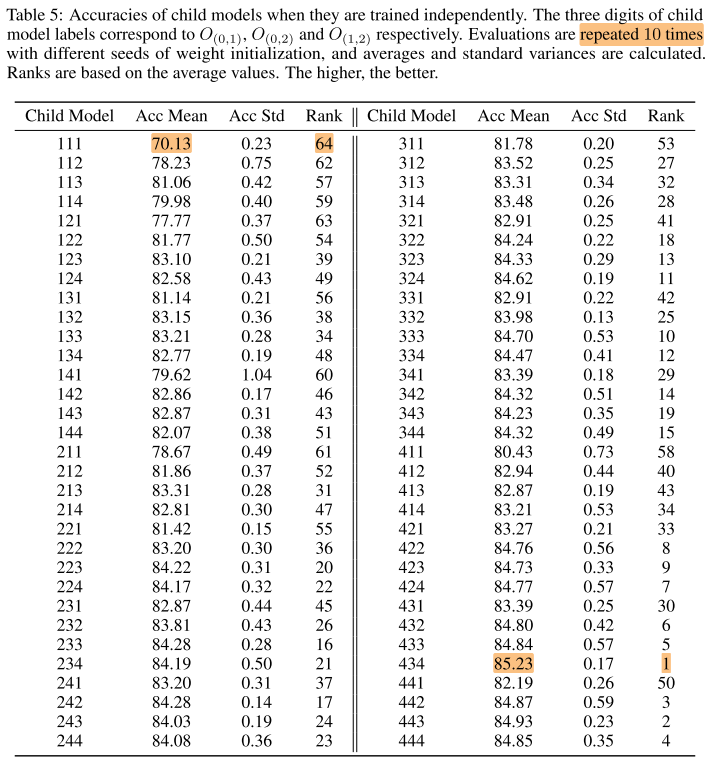
Supernet Search
使用sampler均匀生成子网序列(64个), 每个batch训练1个序列中的子网(64个batch可以把所有子网训练一遍)
- 超网训练seed: 超网权重初始化
- sampler seed: 控制生成的子网序列的顺序
- sampler shuffle: {True, False} 每64个batch是否重新生成 新的子网顺序
可以看出, 不同的run 使用相同的超网训练seed, sampler seed, 相同的sampler shuffle, 得到的结果应该相同
训练完成后, 使用超网的参数对每个子网进行评估, 得到64个子网的排序
Metric
Kendall 相关系数, 衡量两组排序 \(R_1, R_2\) 的相关性: \(\tau(R_1, R_2)\) ; 排序完全一致时, \(\tau=1\) , 排序完全反序时, \(\tau=-1\)
一次supernet search run会得到一组排序 \(R_i\)
设计一个metric来衡量 N次 run得到的N组rank: \(R_1, R_2, ..., R_N\) 的排序稳定性(-1, 1 越大越好), 衡量N组排序的内部差异程度, 类似方差 (任意2个rank都计算一次 \(\tau\)):
- S-Tau: \(\frac{2}{N(N-1)} \sum_{1 \leq i<j \leq N} \tau\left(R_{i}, R_{j}\right)\)
某次run的rank \(R\) 和 ground truth rank的相关性(-1, 1 越大越好):
- GT_Tau: \(\tau(R, R_{gt})\)
某次run 的top n个子模型的ground truth rank平均值(衡量本次run找到优质子网的能力, 1, 64 越小越好):
- Top-n-Rank(TnR): \(\tau(R_{top_n}, R_{top_n gt})\)
Experiments
Multi run: S-Tau 子网排序的稳定性
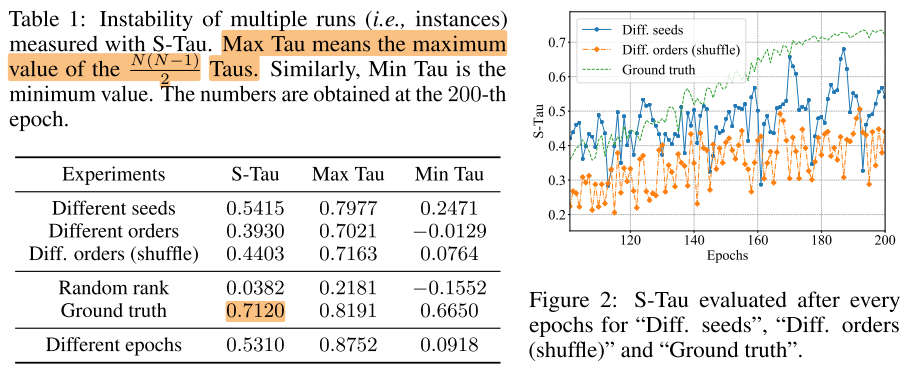
神经网络无论使用什么种子初始化, 最后都能逐渐收敛到一个性能好的, 稳定的(收敛的)状态
我们期望基于权重共享的NAS也是如此, 即无论使用什么seed, 搜索的结果(rank)都要逐渐收敛, 稳定性S-Tau越来越高, 且接近ground truth
每行都是10个run计算的结果
- Different seeds (不同run之间, 超网初始化不同, 子网序列相同, 且子网序列保持不变(周期循环)):
- 不同的超网训练seed
- 相同的sampler seed
- sampler shuffle=False, 每64个batch不重新生成子网序列
- Different orders (不同run之间, 超网初始化相同, 子网序列不同, 且子网序列保持不变(周期循环)):
- 相同的超网训练seed
- 不同的sampler seed
- sampler shuffle=False, 每64个batch不重新生成子网序列
- Diff. orders (shuffle) (不同run之间, 超网初始化相同, 子网序列不同, 且子网序列一直变化(没有周期循环)):
- 相同的超网训练seed
- 不同的sampler seed
- sampler shuffle=True, 每64个batch重新生成子网序列
最随机的方式应该是, 超网初始化不同, 子网序列不同, 序列不重复
2个baseline:
- random rank: 随机生成10组rank
- Ground truth: 单独训练64个子网, 得到1组rank; 重复10次, 得到10组rank
观察:
- 表1: 不同的seed(超网seed, sampler seed), 会导致不同run之间差异很大, 有的run之间相关性很高(0.79), 有的甚至负相关(-0.01)
- 表1: Ground truth的baseline就稳定得多, max=0.82, min=0.67
- 表1: 3个实验的总体稳定性都不高(0.5)
- 图2: 虽然3个实验的总体稳定性都不高, 但实际上他们并没有可比性, 由图2可以看出, S-Tau在训练后期的几个epoch依然剧烈变化(0.3-0.7), 说明搜索结果(rank)并没有收敛
总结: 不同run之间, 子网的rank是非常不稳定的; 超网NAS的假设并不成立
Multi run: GT-Tau & TnR
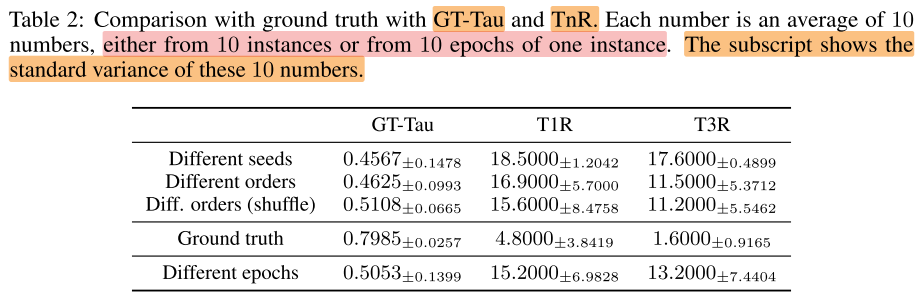
观察:
- 3个实验与GT rank的相关性都很低(0.5), 说明run产生的rank不足以指示子网性能的真实排序
- T1R的范围在15-19, 说明以训练后的超网作为评估器搜索到的top 1, 实际的rank排在15-19, 和GT Top1差距很远; T3R稍好, 但超网NAS中一般无法承担将top n的子网都train from scratch; 进一步说明了使用run得到的rank来作为子网排序的proxy并不靠谱
Single run: S_Tau & GT-Tau & TnR
既然不同run之间的差异很大, 那同一个run在训练末期的稳定性如何?
Different epochs:
- 表1, S_Tau中位数
- 表2, GT-Tau 均值±方差; TnR
观察:
- 同一个run, 在训练后期不同的epoch, 产生的rank也是很不稳定的, 即不同的epoch设置(100/120/150)对产生的rank也有很大的影响
- single run different epoch 与 Multi run 的 metric(S_Tau & GT-Tau & TnR)很接近
single run different epoch 与 Multi run final epoch 的rank分布对比:
图例
- 线段: 数据范围
- 方框: 四分位数/中位数
- 圆圈: 离群点
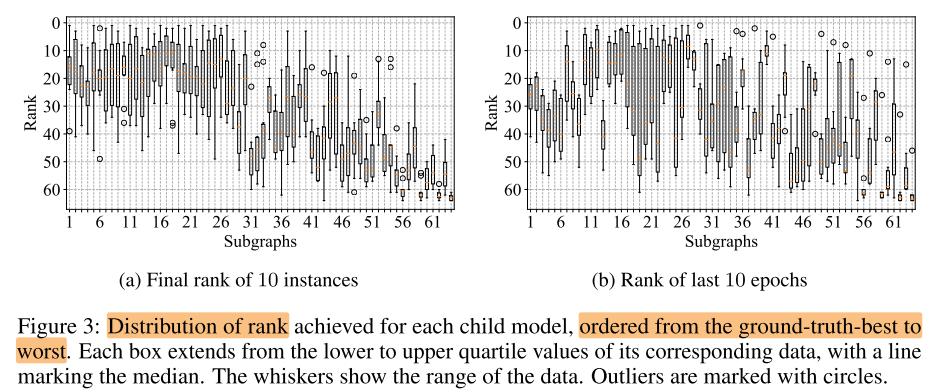
single run different epoch 与 Multi run final epoch的分布很接近, 差的子网容易被识别, 好的子网不容易被识别
Insight 1: 虽然超网NAS的rank是不稳定的, 但由于single run与multi run具有相似性, 可以利用single run快速识别出差的子网, 从而缩小搜索空间, 只训练排名靠前的模型
从前面的实验我们知道, 当超网训练到一定的阶段后(e.g. 100 epochs), 继续训练并不能提高产生的rank的质量, 可以认为是一种"稳定"状态, 因此可以让子网继承当前状态的权重, 对每个子网进行微调:
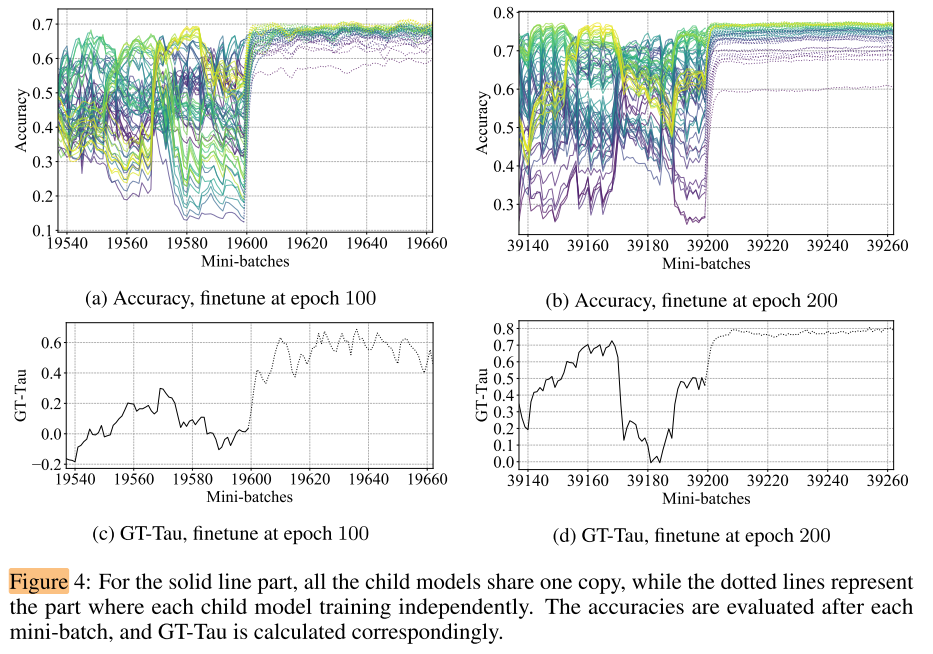
图4 a/c: 在训练100个epoch后, 对每个子网进行64个batch的微调, 可以发现只用了10个batch左右, 每个子网的acc都迅速提高且趋于稳定, GT-Tau也迅速提高到0.6左右
图4 b/d: 从200个epoch后开始微调的结果更好, GT-Tau迅速提高到接近0.8
Insight 2: 训练后的权重共享超网可以作为一个良好的 pre-trained model, 只需要很少的微调(10个batch), 就可以迅速得到各个子网的rank
不同run差异的来源
对single run, 最后128个batch, 计算每个batch后所有子网的精度:
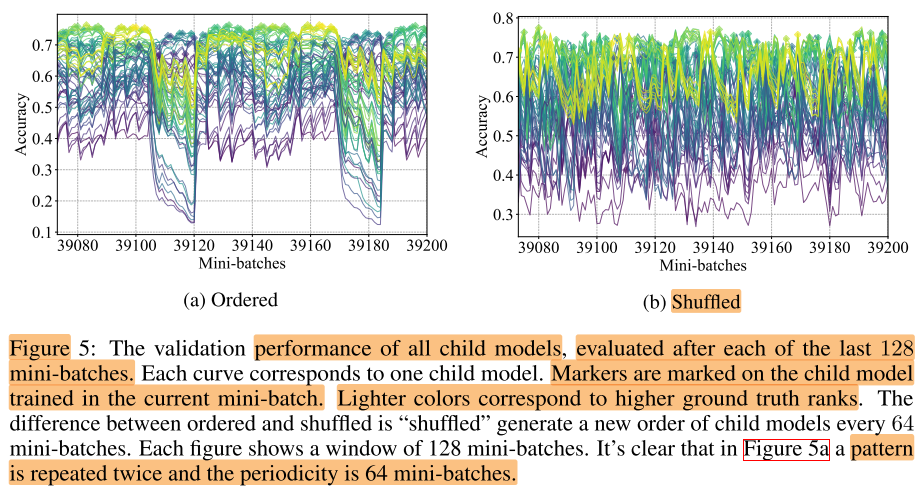
图例:
- 该batch训练的子网用方块标记
- 浅色的是GT性能好的子网
观察:
- 图5 a: 有明显的周期性, 且周期为64, b shuffl后, 周期性消失
- 图5 a/b: 每个子网被训练1个batch后, 性能都会迅速提升
- 优质子网被训练后, 会提升到更高的性能, 但在其他batch, 优质子网不一定是排在最上方的 (训练一个子网, 很容易扰乱整体的rank), 因此在哪个batch生成rank对最终结果影响很大
- 因此rank高差异的原因可能是不同的子网训练产生的相互干扰
Group Sharing
将64个模型分为m组, 每组之内共享参数, m=1即超网训练, m=64即每个子网 train alone
GT-Tau-Mean-k(Mean-k): 最后k个batch的GT-Tau均值
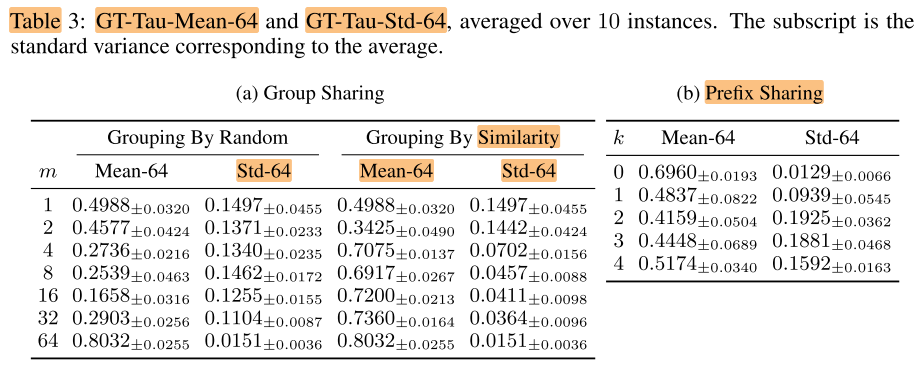
观察:
- 表3 a 左: 随机分组并不能提高稳定性
不合理的分组: 分为16组, 每组4个子网, 424是GT最好的子网
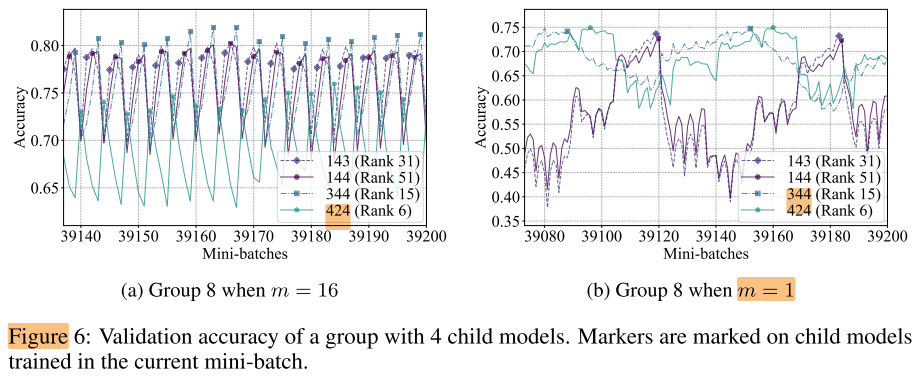
因此我们认为不合理的分组(随机分组)是导致分组不能提高稳定性的原因
合理的分组: 尝试对子网编号 (111-444) 按照字典序进行分组, 表3 a 右, 分组有效地提高了GT-Tau的值, 即m越大, 生成的rank越接近GT
结论:
- 当多个子网共享权重进行训练时, 子网之间存在相互干扰, 一个子网的精度, 严重依赖于与之一起训练的其他子网
- 一中Smart的分组方式, 可以改善训练的稳定性 (本例子中的smart指的是similarity, 但使用字典序衡量相似性可能不是最佳的)
Prefix sharing (left n)
有k个cell共享
- k=0, 只有first conv共享;
- k=4, first conv+4个cell都共享
表3 b, epoch=2000
k越小, GT-Tau越高, k=0时, 仍需要1000个epoch才能提高到0.6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号